


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
今回はトピックモデルについて解説していきます!
トピックモデルとは自然言語処理の一種で、文書を特定のトピックに分類する古典的なアプローチです。
トピックモデルの中でも最もよく用いられているLDA(潜在的ディリクレ配分法)を解説し実際にPythonで実装していきます。
今でも広く用いられているアプローチですのでぜひ理解しておきましょう!
ちなみに当メディアが運営する学習プラットフォーム「スタアカ」の自然言語処理コースで自然言語処理について詳しく学べますので興味のある方はチェックしてみてください!

以下のYoutube動画でも解説していますのであわせてチェックしてみてください!
トピックモデルとは
トピックモデルの主な目的は、大量の文書から隠れたトピックを抽出し、それらのトピックが文書にどのように分布しているかを理解することです。
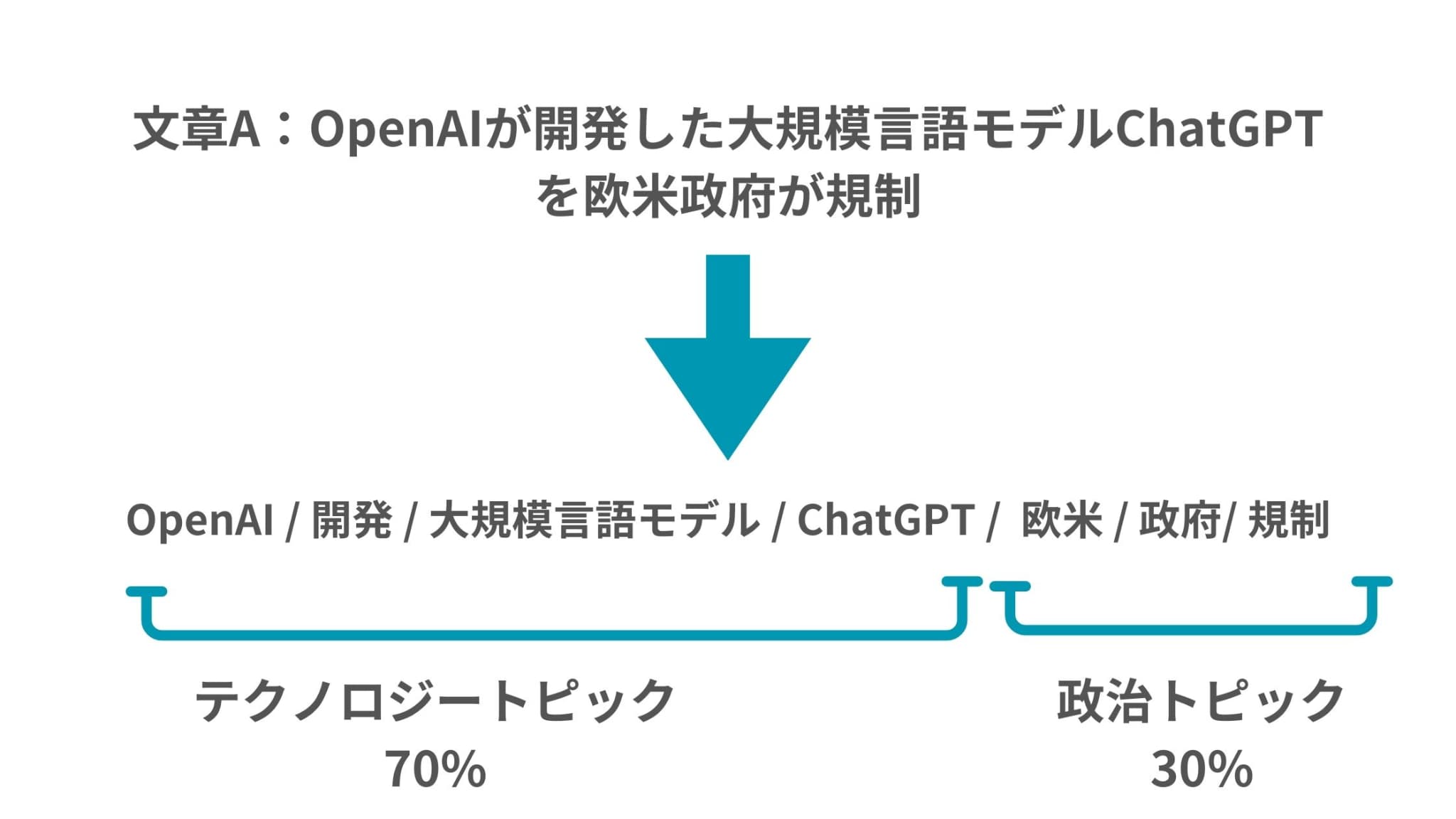
例えば、「OpenAIが開発した大規模言語モデルChatGPTを欧米政府が規制」
みたいな記事があればAI関連のトピックとも考えられますが、政治関連のトピックとも考えられます。
そのためこの文書にはAI関連のトピックと政治関連のトピックが潜在的に存在していることになるのです。
一方で別の記事「米国金利の上昇がFOMCにて決定付けられた」では同じく政治トピックと金融トピックかもしれません。 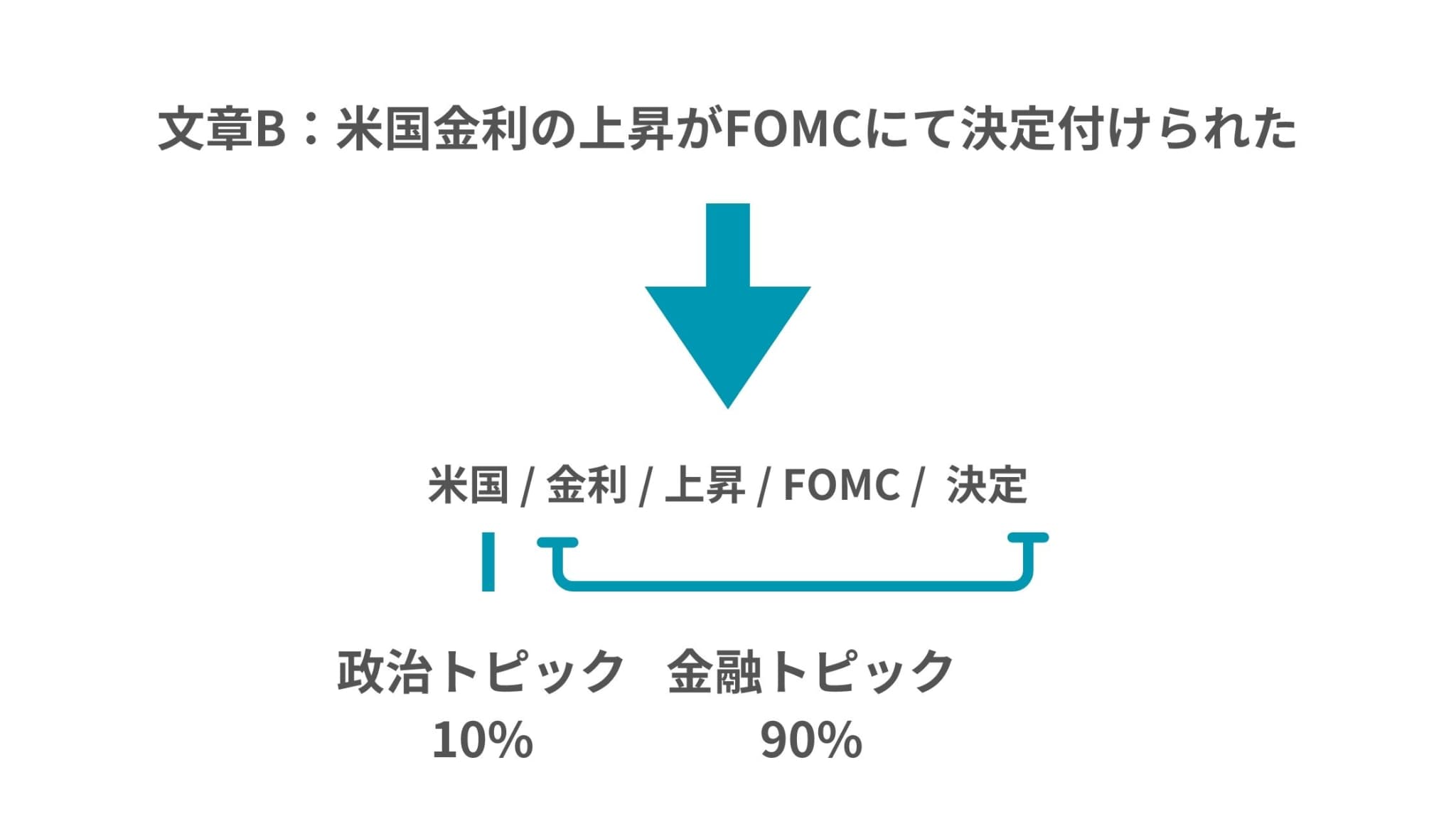
トピックモデルが利用されるシーンとしては以下のようなものがあります!
・推奨システム: トピックの類似性に基づいて、ユーザーに関連するコンテンツを推奨
・検索エンジンの改善: 検索結果をトピックに基づいてランク付け
トピックモデルのLDAをPythonで実装

それではここでは、そんなトピックモデルの1つのアプローチであるLDA(潜在的ディリクレ配分法)をPythonで実装していきたいと思います。
トピックモデルのベースとなる文章を手に入れる必要があるので、NEWS_APIを使ってニュースを取得します。
処理の流れは以下の通りです。
1.NEWS_APIからニュース情報を取得
2.ニュース情報からタイトルだけ抽出
3.ニュースタイトルの文章からストップワードを削除して名詞だけに絞る
4.単語出現回数をカウント
5.LDAを適用させて結果を表示
あらかじめ必要なライブラリはpip installでインストールしておいてください。
ちなみにnewsapiのライブラリは
pip install newsapi-python
でインストールする必要があるので注意してください。
それでは実際にコードを見てみましょう!まずはコード全体から!
from newsapi import NewsApiClient
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import pandas as pd
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
# NLTKのリソースをダウンロード
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('stopwords')
# NEWS_APIのキーを設定
api_key = '<NEWS_APIのキー>'
newsapi = NewsApiClient(api_key=api_key)
# ニュース記事を取得
articles = newsapi.get_everything(q='latest', language='en', page_size=100)
titles = [article['title'] for article in articles['articles']]
# ストップワードの削除と名詞だけに絞る処理
stop_words = set(stopwords.words('english'))
filtered_titles = []
for title in titles:
words = word_tokenize(title)
words = [word for word in words if word.lower() not in stop_words]
nouns = [word for word, pos in pos_tag(words) if pos in ['NN', 'NNS']]
filtered_titles.append(" ".join(nouns))
# タイトルから単語の出現回数をカウント
vectorizer = CountVectorizer()
title_counts = vectorizer.fit_transform(filtered_titles)
# LDAモデルを適用
topic_num = 5
lda = LatentDirichletAllocation(n_components=topic_num, random_state=42)
lda.fit(title_counts)
# トピックごとの単語を表示
words = vectorizer.get_feature_names_out()
for topic_idx, topic in enumerate(lda.components_):
print(f"Topic #{topic_idx}:")
print(" ".join([words[i] for i in topic.argsort()[:-10 - 1:-1]]))
# 各記事のトピックをデータフレームに保存
doc_topic = lda.transform(title_counts)
df = pd.DataFrame(doc_topic, columns=[f'Topic {i}' for i in range(topic_num)])
df['Title'] = titles
print(df.head())
コードの中身を詳しく見ていきましょう!
まず、ライブラリをインポートしnltk(Natural Language Tool Kit)という自然言語処理ツールのリソースをダウンロードしていきます。
from newsapi import NewsApiClient
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import pandas as pd
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
# NLTKのリソースをダウンロード
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('stopwords')
続いてNEWS_APIのAPIキーを設定しニュース記事を取得していきます。NEWS_APIのAPIキーは無料で取得できるので事前に取得しておきましょう!
# NEWS_APIのキーを設定
api_key = '<NEWS_APIのキー>'
newsapi = NewsApiClient(api_key=api_key)
# ニュース記事を取得
articles = newsapi.get_everything(q='latest', language='en', page_size=100)
titles = [article['title'] for article in articles['articles']]
この時、パラメータを設定することで取得するニュースの種類を変更することが可能です。
続いて一般的に除外してもよいと考えられる”and”などのストップワードを除外した上で名刺だけに絞り込みます。
そして特定の単語の出現回数をカウントしています。
# ストップワードの削除と名詞だけに絞る処理
stop_words = set(stopwords.words('english'))
filtered_titles = []
for title in titles:
words = word_tokenize(title)
words = [word for word in words if word.lower() not in stop_words]
nouns = [word for word, pos in pos_tag(words) if pos in ['NN', 'NNS']]
filtered_titles.append(" ".join(nouns))
# タイトルから単語の出現回数をカウント
vectorizer = CountVectorizer()
title_counts = vectorizer.fit_transform(filtered_titles)
そしてその結果をもとにトピック分析をかけてトピックごとの単語を表示します。
# LDAモデルを適用
topic_num = 5
lda = LatentDirichletAllocation(n_components=topic_num, random_state=42)
lda.fit(title_counts)
# トピックごとの単語を表示
words = vectorizer.get_feature_names_out()
for topic_idx, topic in enumerate(lda.components_):
print(f"Topic #{topic_idx}:")
print(" ".join([words[i] for i in topic.argsort()[:-10 - 1:-1]]))
# 各記事のトピックをデータフレームに保存
doc_topic = lda.transform(title_counts)
df = pd.DataFrame(doc_topic, columns=[f'Topic {i}' for i in range(topic_num)])
df['Title'] = titles
print(df.head())
結果は以下のようになりました!


5つのトピックを表現する特徴的な単語が列挙されていて、それぞれのニュース記事がどのトピックに分類されそうか確率値が並んでますね!
今回は100記事で実装しましたので、若干違和感がありますがもっと記事数や文章ボリュームを増やすことで精度が向上していくと思われます。
また、今回は簡単のために英語で実装してみましたが、もし日本語でやる場合は形態素解析による分かち書きが必要になってきます。
その場合はMecabを使ってみましょう!
Mecabの使用方法やMecabを使った自然言語処理アプローチに関しては以下の記事でまとめています!

トピックモデル まとめ
本記事ではトピックモデルについてまとめました!
トピックモデルではレコメンドに関わる話も多いので、こちらの協調フィルタリングの記事やレコメンドのアルゴリズムも見てみると良いでしょう!


このようなデータサイエンスの力を身に付けるためにはスタビジの記事やスクールを活用すると良いでしょう。
そして僕の経験を詰め込んだデータサイエンス特化のスクール「スタアカ(スタビジアカデミー)」を運営していますので,興味のある方はぜひチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」


| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
データサイエンスに関する記事はこちら!


データサイエンスを勉強できるスクールやサイトは、ぜひこちらを参考にしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!





















