ここ3ヶ月くらいPyTorch Lightning (以下 Lightning)を使ってていろいろ機能を調べてます。それでfast.aiでお馴染みのLearning Rate Finder(LR Finder: 最適な初期学習率を探索する仕組み)がLightningにもけっこう昔から実装されているのですが、日本語での紹介がほぼ無いみたいなので情報をまとめておきます。せっかくなのでこのエントリーでは細かいtipsや内部実装なども掘り下げて紹介したいと思います。
環境
* Pytorch 1.12.1
* Pytorch Lightning 1.7.0
Learning Rate Finder (LR Finder)とは
機械学習にはSGDやAdamなど様々な最適化アルゴリズムがあります。もちろんPyTorchにもたくさんのオプティマイザが実装されていますが、それらを適切に使いこなすには奥が深く、その中でも学習率の設定は精度にも大きな影響がでることが多いのでそれを自動化したいモチベーションが生まれます。そのための仕組みがLearning Rate Finder(LR Finder)と呼ばれておりfast.aiでの実装が特に有名かと思います。
その仕組みを使うと初期学習率のサジェストを得ることができます。Lightningの実装だと以下のようにlossと学習率のプロット、おすすめの学習率(赤点)を教えてくれます。

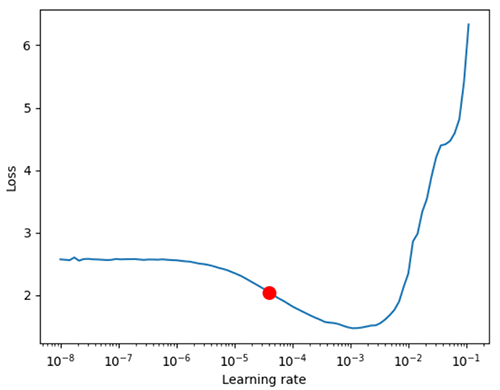
今回はLightningでの実装について紹介しますが、PyTorch IgniteではFastaiLRFinderというハンドラが実装されているので、もしIgniteを使っている人はそちらを使うと良いでしょう。
また、PyTorch Lightningを使ったサンプルコードはこちらのリポジトリにいろいろ置いてあるので参考までに。
* pytorch-learning/lightning/ at master · wellflat/pytorch-learning
使い方
公式ドキュメントはこちら
使い方は2パターンあって別々に紹介します。まず一つ目は以下のような学習率を1つのインスタンス変数として設定する方法です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
## learning_rate か lr という名前の変数に設定 class LitModel(LightningModule): def __init__(self, learning_rate): self.learning_rate = learning_rate def configure_optimizers(self): return Adam(self.parameters(), lr=(self.lr or self.learning_rate)) model = LitModel() # finds learning rate automatically # sets hparams.lr or hparams.learning_rate to that learning rate trainer = Trainer(auto_lr_find=True) trainer.tune(model) ## 任意の名前の変数にも設定可能 model = LitModel() # to set to your own hparams.my_value trainer = Trainer(auto_lr_find="my_value") # tuneメソッドで学習率探索・学習 trainer.tune(model) |
ただし、これは個人的にはあまりおすすめしない使い方です。というのも、上記のサンプルだとハイパーパラメータは学習率の一つしか設定していませんが、実際には他のパラメータやスケジューラの設定などもこのLightningModuleのサブクラスに渡すことになると思います。コンストラクタに引数がたくさんあるのは望ましくないので、その場合は設定用クラスを別で作って渡すか、Builderパターンを使って初期化処理を行いますが、この学習率設定方法だと柔軟なクラス設計ができません。また、Optionalなパラメータではないのにインスタンス生成時に引数を渡さないと、エディタやLintの設定によってはエラーになってしまいます。たぶんLightningの設計思想だとコード量を少なくするのが正義だと思うのでこういう実装方法も提供しているのでしょう。
ということで実装面での拡張を考慮するなら以下の二つ目の方法の方がおすすめです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
model = MyModelClass(hparams) trainer = Trainer() # lr_find メソッドを明示的に呼んで学習率探索 lr_finder = trainer.tuner.lr_find(model) # results にロスと学習率のリストが入っている(後述) lr_finder.results # グラフの可視化 (要matplotlib) fig = lr_finder.plot(suggest=True) fig.show() # 提案された学習率を取得 new_lr = lr_finder.suggestion() # 提案された学習率で再設定 (設定先の変数は任意、ここではlr) model.hparams.lr = new_lr # 学習 trainer.fit(model) |
コード量自体は増えてしまいますが、後でDIコンテナ等の導入も容易ですし、学習率探索結果の可視化処理も切り分けて実行可能になります。
ちなみに個人的に最近よく使う手法としてはとしてはオプティマイザをRAdam、スケジューラにはOneCycleLRを使っています。fast.aiでいうところのfit_one_cycleを使うイメージです。ちなみにRAdamは少し前までは外部モジュールを使う必要がありましたが(例えばLiyuanLucasLiu /RAdamなど)、現在はPyTorch本体に実装済みなのでこちらを使っておけば良いでしょう。


実装
LightningでのLR Finderの実装はこちら。
提案する学習率の計算はシンプルにsteepest negative gradientで計算されます。文字通り内部スケジューラのステップがepochではなくstep指定(つまりミニバッチ毎)でlossが記録されていきます。
デフォルトの挙動は以下の通り
- 探索範囲 1e-8 ~ 1.0 の間でExponentialLRにより学習率をステップ毎に変更
- ステップ毎の学習率とlossを逐次記録
- 最初と最後の数ステップ分は無視して、勾配が一番小さくなる時の学習率を提案
内部的に計算されるlossは以下のようにモーメンタム法で減衰されてかつ平滑化されます。betaの初期値は0.98です。
|
1 2 |
self.avg_loss = self.beta * self.avg_loss + (1 - self.beta) * current_loss smoothed_loss = self.avg_loss / (1 - self.beta ** (current_step + 1)) |
提案される学習率を簡易的に実装すると以下のようにシンプルです。
|
1 2 3 |
lr_finder = trainer.tuner.lr_find(model) # results にロス(loss)と学習率(lr)のリストが入っている Dict[str, List[float]] suggested_lr = lr_finder.results['lr'][np.gradient(lr_finder.results['loss']).argmin()] |
実際には最初と最後の数ステップ分を無視したり、InfやNaNを無視する処理等が含まれていますが、簡易的には上記のように勾配が一番小さくなる時の学習率を返しているだけです。イメージとしては坂道を転げ落ち始める直前の値を使うという感じでしょうか。lossがモーメンタム+平滑化で計算されているのもこのためだと思います。
補足・注意点
LR Finder利用時の細かい注意点についても紹介しておきます。学習率探索時の探索範囲の指定ができるようになっていますが範囲の設定によって提案される学習率が変わります。
|
1 2 3 |
# min_lr, max_lr でそれぞれ探索範囲下限、上限を指定できる # デフォルトは min_lr=1e-8, max_lr=1.0 lr_finder = trainer.tuner.lr_find(model=model, datamodule=data_module, min_lr=1e-5, max_lr=1e-3) |
注意点としては、例えば適切な学習率はだいたい1e-4くらいかなと考えて探索範囲を上記のように意図的に狭めてしまうと、内部スケジューラ等の影響によって最終的に提案される学習率が大きく変わってしまうことがあります。併せて学習率提案時のオプションを指定する方法もあり、最初と最後のステップをいくつくらい無視するか指定することもできます。
|
1 2 |
# skip_begin, skip_endでそれぞれ最初と最後のサンプルを指定数分参照しないようにする new_lr = lr_finder.suggestion(skip_begin=15, skip_end=1) |
内部実装も見つつオプションをいろいろ試してみましたが、そもそもLR Finderを使う目的がパラメータの自動設定なので全部おまかせ(デフォルト)で良いのではないかと思いました。
あとは、学習率探索処理を実行するとモデルのパラメータが更新されてチェックポイントファイルが中間ファイルとして強制的にファイル出力されます。実行途中になんらかの理由でプロセスが停止するとチェックポイントファイルが削除されずに残ってしまうので注意してください。ギリギリのバッチサイズを攻めているとCUDA out of memoryが出てゴミファイルが残され続けてディスクを逼迫させてしまうことが何度かありました。
可視化
matplotlibモジュールが入っている場合は前述の通りplot関数を呼ぶだけでグラフが表示されます。ただし、plot関数ではグラフの体裁を整えたりはできませんし、matplotlibではなくSeabornやBokehなどモダンな可視化モジュールを使っている人は自前でプロット処理を書いても良いかもしれません。描画に必要なデータは以下のように取得できます。
|
1 2 3 4 5 6 |
lr_finder = trainer.tuner.lr_find(model) # results: Dict[str, List[float]] ロス(loss)と学習率(lr)のリスト loss = lr_finder.results['loss'] lr = lr_finder.results['lr'] # _optimal_idx: int 提案する学習率lrのインデックス optimal_idx = lr_finder._optimal_idx |
MLOps環境ではnotebook環境は使わずにサーバ環境で自動実行されるので、処理結果の可視化はMLOpsツールに任せるか、HTML出力して後でブラウザで見ることになるでしょう。MLOpsツールを使わない場合はHTML出力ができてインタラクティブな操作もできるBokehが最近だと良いかもしれません。
サンプルとしては以下のようにLR Finderの結果を可視化できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from bokeh.plotting import figure, show, output_file def plot_bokeh(lrs: List[float], losses: List[float]): p = figure( title='LR finder', x_axis_label='Learning rate', y_axis_label='Loss', x_axis_type='log' ) p.line(x=lrs, y=losses) grads = np.gradient(losses) skip_grads = grads[10:-1] # 最初と最後の数ステップ分は不安定なのでスキップ optimal_idx = skip_grads.argmin() p.circle(x=lrs[optimal_idx], y=losses[optimal_idx], color='red', size=10, alpha=0.5) output_file('results.html') ## 任意のHTMLファイル出力 show(p) |




↑のようにブラウザ上でインタラクティブに拡大縮小できるし、画像ファイル出力もできます。matplotlibよりも各APIの使い方が簡単ですし、出力されるHTMLは描画データもJavaScriptも埋め込まれるので.htmlファイル1枚で完結するところも良いですね。
おわりに
PyTorch LightningでのLR Finderの使い方を紹介しました。これをやって実務レベルでどれくらいのメリットがあるかというところについては適用するドメインで当然変わってくると思います。例えば広告配信系ならKaggleレベルの小数点以下の細かい精度向上に取り組むことも多いでしょうし、逆に画像認識系ならちょっとくらい物体検出の枠がズレていても使う人が気にしないのであればそこまで細かい数字を追い求めなくて良いこともあります。ある程度は経験によって適切な初期学習率はだいたいわかることもあるかもしれませんが、オプティマイザとスケジューラ、バッチサイズの組み合わせまで含めて経験に頼るのは厳しいでしょう。
最近は研究者やデータサイエンティストではない普通のWebエンジニアも機械学習モデルをさくっと作る時代ですから、学習率を良い感じに提案してくれる機能があればどんどん活用した方が良いと思います。
長らく素のPyTorchを使っている人にとってLightningを使うモチベーションは低いかも知れませんが、けっこう便利なのでこういうラッパーフレームワークを使うのも悪くないです。Lightningを使うくらいならfast.aiでいいやってなるかもしれませんが、宗教上の理由もあると思いますのでそこはよしなに。
* pytorch-learning/lightning/ at master · wellflat/pytorch-learning
参考
New LR Finder Output?! – fastai – fast.ai Course Forums
lightning/lr_finder.py at master · Lightning-AI/lightning
ignite.handlers > FastaiLRFinder
PyTorch初心者です。簡単といわれているLightningをちまちまと始めて数か月、PL公式のあまり体系化されていないドキュメントとつぶらな瞳のお兄さんの説明動画ばかり見ていました。そんな中で、単なる和訳資料だけでなく実際に試してみた情報もありとても貴重に感じます。ありがとうございます。