



Protocol Buffers are awesome. Having schemas to deflate and inflate data while maintaining some kind of validation is a great concept. Compactr's goal is to build on that to better suit the Javascript ecosystem.
npm install compactr
const Compactr = require('compactr');
// Defining a schema
const userSchema = Compactr.schema({
id: { type: 'number' },
name: { type: 'string' }
});
// Encoding
userSchema.write({ id: 123, name: 'John' });
// Get the header bytes
const header = userSchema.headerBuffer();
// Get the content bytes
const partial = userSchema.contentBuffer();
// Get the full payload (header + content bytes)
const buffer = userSchema.buffer();
// Decoding a full payload
const content = userSchema.read(buffer);
// Decoding a partial payload (content)
const content = userSchema.readContent(partial);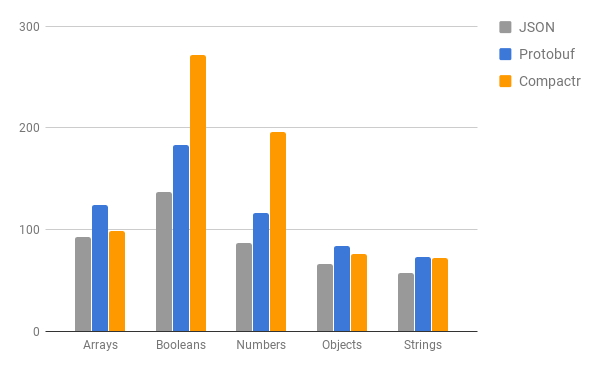
Measured against plain JSON serialization + convertion to buffer. Compactr serialization is performed with default settings via the partial (content only) load method
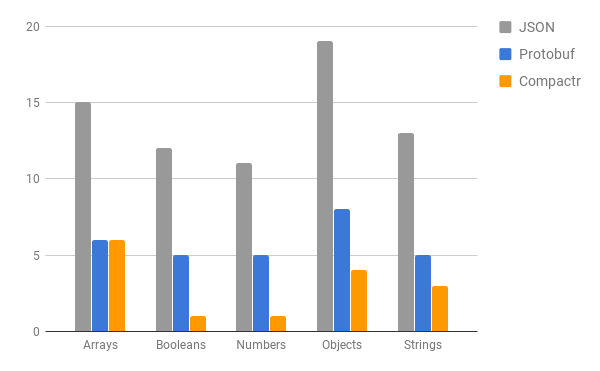
JSON: {"id":123,"name":"John"}: 24 bytes
Compactr (full): <Buffer 02 00 01 01 04 7b 4a 6f 68 6e>: 10 bytes
Compactr (partial): <Buffer 7b 4a 6f 68 6e>: 5 bytes
| Type | Count bytes | Byte size |
|---|---|---|
| boolean | 0 | 1 |
| number | 0 | 8 |
| int8 | 0 | 1 |
| int16 | 0 | 2 |
| int32 | 0 | 4 |
| double | 0 | 8 |
| string | 1 | 2/char |
| char8 | 1 | 1/char |
| char16 | 1 | 2/char |
| char32 | 1 | 4/char |
| array | 1 | (x)/entry |
| object | 1 | (x) |
| unsigned | 0 | 8 |
| unsigned8 | 0 | 1 |
| unsigned16 | 0 | 2 |
| unsigned32 | 0 | 4 |
- Count bytes range can be specified per-item in the schema*
See the full Compactr protocol
You are awesome! Open an issue on this project, identifying the feature that you want to tackle and we'll take the discussion there!
Apache 2.0 (c) 2017 Frederic Charette