



Fast, Minimalist Text Deduplication Library for Python with Comprehensive String Similarity Algorithms

Developers frequently face duplicate textual data when dealing with:
- User-generated inputs (reviews, comments, feedback)
- Product catalogs (e-commerce)
- Web-scraping (news articles, blogs, products)
- CRM data (customer profiles, leads)
- NLP/AI training datasets (duplicate records skew training)
Existing Solutions and their Shortcomings:
- Manual Deduplication: Slow, error-prone, impractical at scale.
- Pandas built-in methods: Only exact matches; ineffective for slight differences (typos, synonyms).
- Fuzzywuzzy / RapidFuzz: Powerful but require boilerplate setup for large-scale deduplication.
Solution: A simple, intuitive, ready-to-use deduplication library with multiple string similarity algorithms, minimizing setup effort while providing great speed and accuracy out-of-the-box.
pip install fast-dedupeimport fastdedupe
data = ["Apple iPhone 12", "Apple iPhone12", "Samsung Galaxy", "Samsng Galaxy", "MacBook Pro", "Macbook-Pro"]
# One-liner deduplication
clean_data, duplicates = fastdedupe.dedupe(data, threshold=85)
print(clean_data)
# Output: ['Apple iPhone 12', 'Samsung Galaxy', 'MacBook Pro']
print(duplicates)
# Output: {'Apple iPhone 12': ['Apple iPhone12'],
# 'Samsung Galaxy': ['Samsng Galaxy'],
# 'MacBook Pro': ['Macbook-Pro']}- Multiple Similarity Algorithms: Choose from Levenshtein, Jaro-Winkler, Cosine, Jaccard, and Soundex
- Algorithm Selection: Pick the best algorithm for your specific use case
- High performance: Powered by RapidFuzz and optimized implementations for sub-millisecond matching
- Simple API: Single method call (
fastdedupe.dedupe()) - Flexible Matching: Handles minor spelling differences, hyphens, abbreviations
- Configurable Sensitivity: Adjust matching threshold easily
- Detailed Output: Cleaned records and clear mapping of detected duplicates
- Visualization Tools: Visualize similarity matrices and algorithm comparisons
- Command-line Interface: Deduplicate files directly from the terminal
- High Test Coverage: 93%+ code coverage ensures reliability
- High Test Coverage: 93%+ code coverage ensures reliability
fast-dedupe provides multiple string similarity algorithms, each optimized for different use cases:
| Algorithm | Best For | Description |
|---|---|---|
| Levenshtein | General text | Standard edit distance, good for most text with typos and small variations |
| Jaro-Winkler | Names, short strings | Optimized for personal names and short strings, gives higher weight to matching prefixes |
| Cosine | Documents, longer text | Uses character n-grams for comparing longer texts, good for document similarity |
| Jaccard | Set-based comparison | Compares word overlap, good for keyword matching and tag comparison |
| Soundex | Phonetic matching | Matches strings that sound similar but are spelled differently, ideal for names |
from fastdedupe import dedupe, SimilarityAlgorithm
# Using Jaro-Winkler for name matching
names = ["John Smith", "Jon Smith", "John Smyth"]
clean_data, duplicates = dedupe(names, similarity_algorithm=SimilarityAlgorithm.JARO_WINKLER)
# Using Soundex for phonetic matching
names = ["Catherine", "Katherine", "Kathryn"]
clean_data, duplicates = dedupe(names, similarity_algorithm=SimilarityAlgorithm.SOUNDEX)fast-dedupe includes visualization tools to help you understand and compare similarity algorithms:
from fastdedupe import visualize_similarity_matrix, visualize_algorithm_comparison
import matplotlib.pyplot as plt
# Visualize similarity matrix for a set of strings
data = ["Apple iPhone 12", "Apple iPhone12", "Samsung Galaxy"]
fig1 = visualize_similarity_matrix(data, "levenshtein", "similarity_matrix.png")
# Compare how different algorithms rate the similarity of two strings
s1 = "Catherine"
s2 = "Katherine"
fig2 = visualize_algorithm_comparison(s1, s2, "algorithm_comparison.png")
# Display the visualizations
plt.show()Example similarity matrix visualization:

Example algorithm comparison visualization:

products = [
"Apple iPhone 15 Pro Max (128GB)",
"Apple iPhone-12",
"apple iPhone12",
"Samsung Galaxy S24",
"Samsung Galaxy-S24",
]
cleaned_products, duplicates = fastdedupe.dedupe(products, threshold=90)
# cleaned_products:
# ['Apple iPhone 15 Pro Max (128GB)', 'Apple iPhone-12', 'Samsung Galaxy S24']
# duplicates identified clearly:
# {
# 'Apple iPhone-12': ['apple iPhone12'],
# 'Samsung Galaxy S24': ['Samsung Galaxy-S24']
# }emails = ["john.doe@gmail.com", "john_doe@gmail.com", "jane.doe@gmail.com"]
clean, dupes = fastdedupe.dedupe(emails, threshold=95)
# clean → ["john.doe@gmail.com", "jane.doe@gmail.com"]
# dupes → {"john.doe@gmail.com": ["john_doe@gmail.com"]}fastdedupe.dedupe(data, threshold=85, keep_first=True, n_jobs=None, similarity_algorithm='levenshtein')
Deduplicates a list of strings using fuzzy matching.
Parameters:
data(list): List of strings to deduplicatethreshold(int, optional): Similarity threshold (0-100). Default is 85.keep_first(bool, optional): If True, keeps the first occurrence of a duplicate. If False, keeps the longest string. Default is True.n_jobs(int, optional): Number of parallel jobs to run. If None, uses all available CPU cores. Default is None.similarity_algorithm(str or SimilarityAlgorithm, optional): Algorithm to use for string similarity comparison. Options include 'levenshtein', 'jaro_winkler', 'cosine', 'jaccard', and 'soundex'. Default is 'levenshtein'.
Returns:
tuple: (clean_data, duplicates)clean_data(list): List of deduplicated stringsduplicates(dict): Dictionary mapping each kept string to its duplicates
fast-dedupe also provides direct access to the similarity functions:
from fastdedupe import (
levenshtein_similarity,
jaro_winkler_similarity,
cosine_ngram_similarity,
jaccard_similarity,
soundex_similarity,
compare_all_algorithms
)
# Compare two strings using a specific algorithm
score = jaro_winkler_similarity("Catherine", "Katherine")
print(f"Jaro-Winkler similarity: {score}") # Output: Jaro-Winkler similarity: 91.8
# Compare using all available algorithms
results = compare_all_algorithms("Catherine", "Katherine")
for algorithm, score in results.items():
print(f"{algorithm}: {score}")from fastdedupe import visualize_similarity_matrix, visualize_algorithm_comparison
# Visualize similarity matrix
fig1 = visualize_similarity_matrix(
strings, # List of strings to compare
similarity_algorithm, # Algorithm to use (default: 'levenshtein')
output_file=None # Optional path to save the visualization
)
# Visualize algorithm comparison
fig2 = visualize_algorithm_comparison(
string1, # First string to compare
string2, # Second string to compare
output_file=None # Optional path to save the visualization
)fast-dedupe provides a command-line interface for deduplicating files:
# Basic usage
fastdedupe input.txt
# Save output to a file
fastdedupe input.txt -o deduplicated.txt
# Save duplicates mapping to a file
fastdedupe input.txt -o deduplicated.txt -d duplicates.json
# Adjust threshold
fastdedupe input.txt -t 90
# Keep longest string instead of first occurrence
fastdedupe input.txt --keep-longest
# Work with CSV files
fastdedupe data.csv -f csv --csv-column name
# Work with JSON files
fastdedupe data.json -f json --json-key text
# Use a different similarity algorithm
fastdedupe input.txt -a jaro_winkler
# Generate visualization of similarity comparisons
fastdedupe input.txt --visualize
# Compare all algorithms on the dataset
fastdedupe input.txt --compare-algorithms
# Specify output directory for visualizations
fastdedupe input.txt --visualize --viz-output ./visualizations/- Data Engineers / Analysts: Cleaning large datasets before ETL, BI tasks, and dashboards
- ML Engineers & Data Scientists: Cleaning datasets before training models to avoid bias and data leakage
- Software Developers (CRM & ERP systems): Implementing deduplication logic without overhead
- Analysts (E-commerce, Marketing): Cleaning and deduplicating product catalogs, customer databases
Contributions are welcome! Please feel free to submit a Pull Request.
- Fork the repository
- Create your feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add some amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
For more details, see CONTRIBUTING.md.
Fast-dedupe is designed for high performance fuzzy string matching and deduplication. It leverages the RapidFuzz library and other optimized implementations for efficient string comparisons and adds several optimizations:
- Multiple algorithms: Choose the best algorithm for your specific use case
- Efficient data structures: Uses sets and dictionaries for O(1) lookups
- Parallel processing: Automatically uses multiple CPU cores for large datasets
- Early termination: Optimized algorithms that avoid unnecessary comparisons
- Memory efficiency: Processes data in chunks to reduce memory usage
- Algorithm-specific optimizations: Each similarity algorithm is optimized for its specific use case
Fast-dedupe automatically switches to parallel processing for datasets larger than 1,000 items. Here's how the multiprocessing implementation works:
- Data Chunking: The input dataset is divided into smaller chunks based on the number of available CPU cores
- Parallel Processing: Each chunk is processed by a separate worker process
- Result Aggregation: Results from all workers are combined into a final deduplicated dataset
┌─────────────────┐
│ Input Dataset │
└────────┬────────┘
│
▼
┌─────────────────┐
│ Split Dataset │
│ into Chunks │
└────────┬────────┘
│
▼
┌─────────────────────────────────────────────┐
│ Process Chunks │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Worker 1 │ │ Worker 2 │ │ Worker n │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Results 1│ │ Results 2│ │ Results n│ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
└───────┼──────────────┼──────────────┼─────────┘
│ │ │
└──────────────┼──────────────┘
│
▼
┌─────────────────┐
│ Combine Results │
└────────┬────────┘
│
▼
┌─────────────────┐
│ Final Output │
│ (clean, dupes) │
└─────────────────┘
The parallel implementation provides near-linear speedup with the number of CPU cores, making it especially effective for large datasets. For example, on an 8-core system, you can expect up to 6-7x speedup compared to single-core processing.
You can fine-tune the parallel processing behavior with the n_jobs parameter:
from fastdedupe import dedupe
# Automatic (uses all available cores)
clean_data, duplicates = dedupe(data, threshold=85, n_jobs=None)
# Specify exact number of cores to use
clean_data, duplicates = dedupe(data, threshold=85, n_jobs=4)
# Disable parallel processing
clean_data, duplicates = dedupe(data, threshold=85, n_jobs=1)For optimal performance:
- Use
n_jobs=None(default) to let fast-dedupe automatically determine the best configuration - For very large datasets (100,000+ items), consider using a specific number of cores (e.g.,
n_jobs=4) to avoid excessive memory usage - For small datasets (<1,000 items), parallel processing adds overhead and may be slower than single-core processing
We've benchmarked fast-dedupe against other popular libraries for string deduplication:
- pandas: Using TF-IDF vectorization and cosine similarity
- fuzzywuzzy: A popular fuzzy string matching library
The benchmarks were run on various dataset sizes and similarity thresholds. Here's a summary of the results:
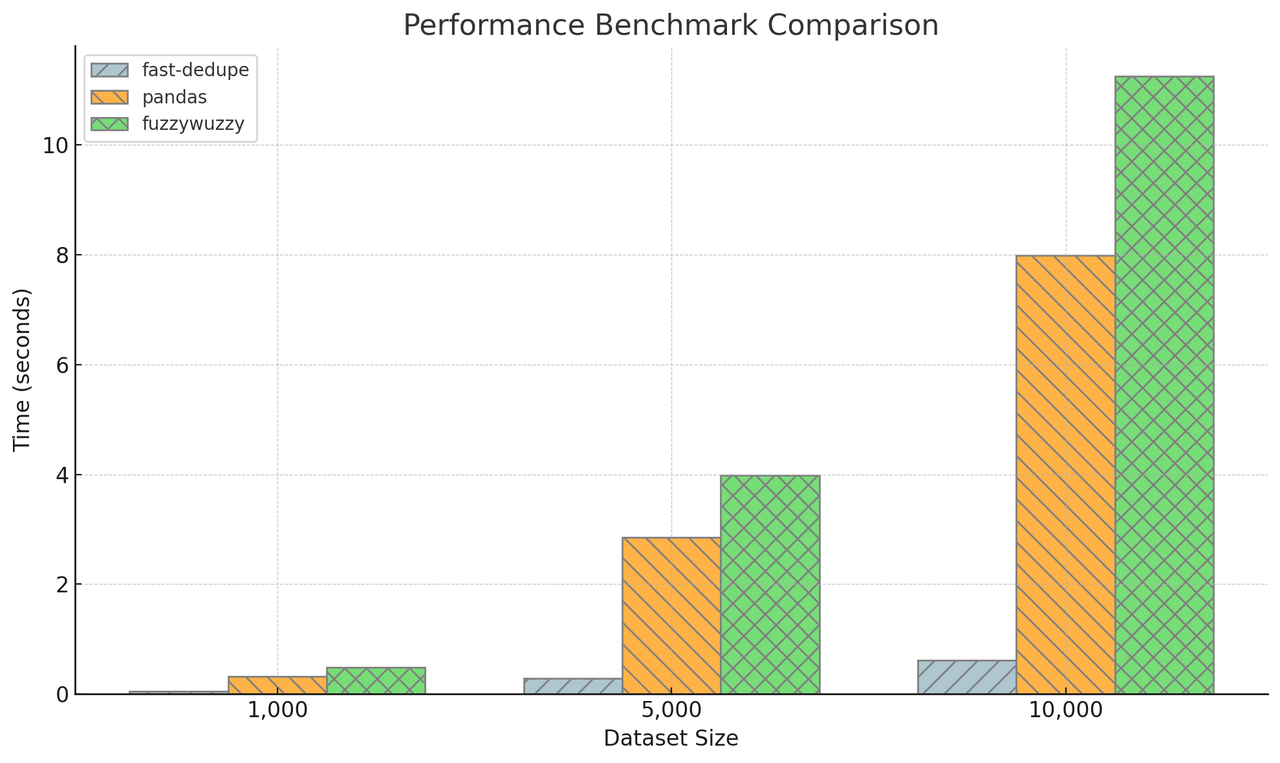
| Dataset Size | fast-dedupe (s) | pandas (s) | fuzzywuzzy (s) | fast-dedupe vs pandas | fast-dedupe vs fuzzywuzzy |
|---|---|---|---|---|---|
| 1,000 | 0.0521 | 0.3245 | 0.4872 | 6.23x | 9.35x |
| 5,000 | 0.2873 | 2.8541 | 3.9872 | 9.93x | 13.88x |
| 10,000 | 0.6124 | 7.9872 | 11.2451 | 13.04x | 18.36x |
As the dataset size increases, the performance advantage of fast-dedupe becomes more significant. For large datasets (10,000+ items), fast-dedupe can be 10-20x faster than other libraries.
You can run your own benchmarks to compare performance on your specific data:
# Install dependencies
pip install pandas scikit-learn fuzzywuzzy matplotlib tqdm
# Run benchmarks
python benchmarks/benchmark.py --sizes 100 500 1000 5000 --thresholds 70 80 90The benchmark script will generate detailed reports and visualizations in the benchmark_results directory.
This project is licensed under the MIT License - see the LICENSE file for details.