Project for the "Cloud Computing" class (2022-23) at Pisa University.
Group work carried out by the students: Luca Arduini, Angelo De Marco, Marco Pardini.
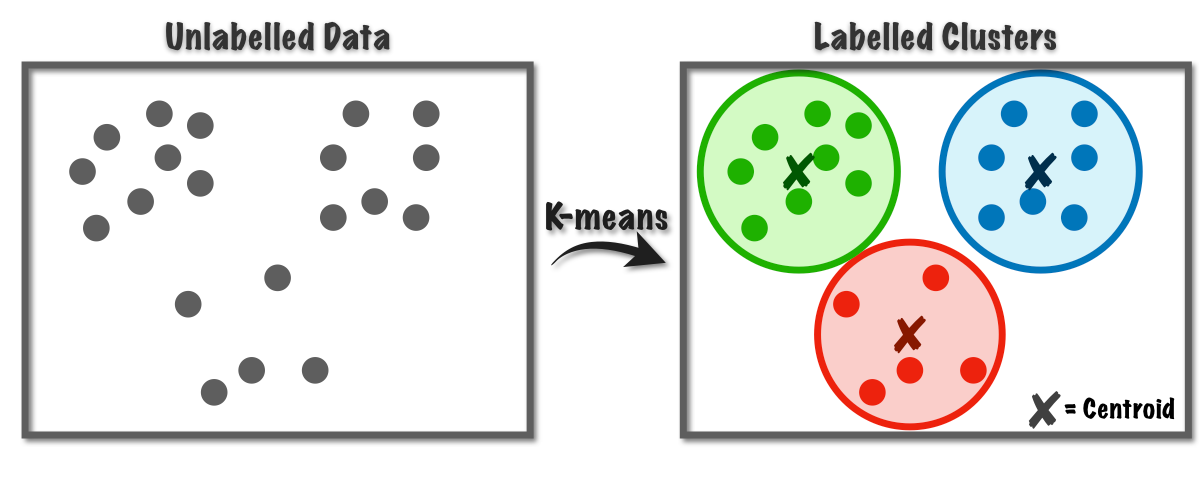
Our project for the Cloud Computing course focuses on implementing the k-means algorithm using the distributed computing paradigm through the use of Hadoop. The main objective of the study was to develop and evaluate the implementation of the k-means algorithm in a distributed environment. To achieve this objective we utilized the Hadoop framework, which provides a distributed processing environment for handling large datasets.
After completing the implementation, we shifted our focus to performance evaluation. We conducted several tests, varying the input parameters such as the number of clusters, dataset size, and number of algorithm iterations. Through these evaluations, we were able to study the impact of these parameters on the overall performance of the k-means algorithm in a distributed environment.