More Web Proxy on the site http://driver.im/「型の理論」と証明支援システム -- COQの世界
- 3. はじめに
現在、HoTT(Homotopy Type Theory)と呼
ばれる新しい型の理論とそれを基礎付ける
Univalent Theoryと呼ばれる新しい数学理論
が、熱い関心を集めている。
Univalent Theoryは、数学者のVladimir
Voevodskyが、論理学者Per Martin-Löfの型
の理論を「再発見」したことに始まる。
この新しい分野は、21世紀の数学とコンピュ
ータサイエンスの双方に、大きな影響を与え
ていくだろう。
- 7. Part I
「型の理論」をふりかえる
型の理論 ~1910
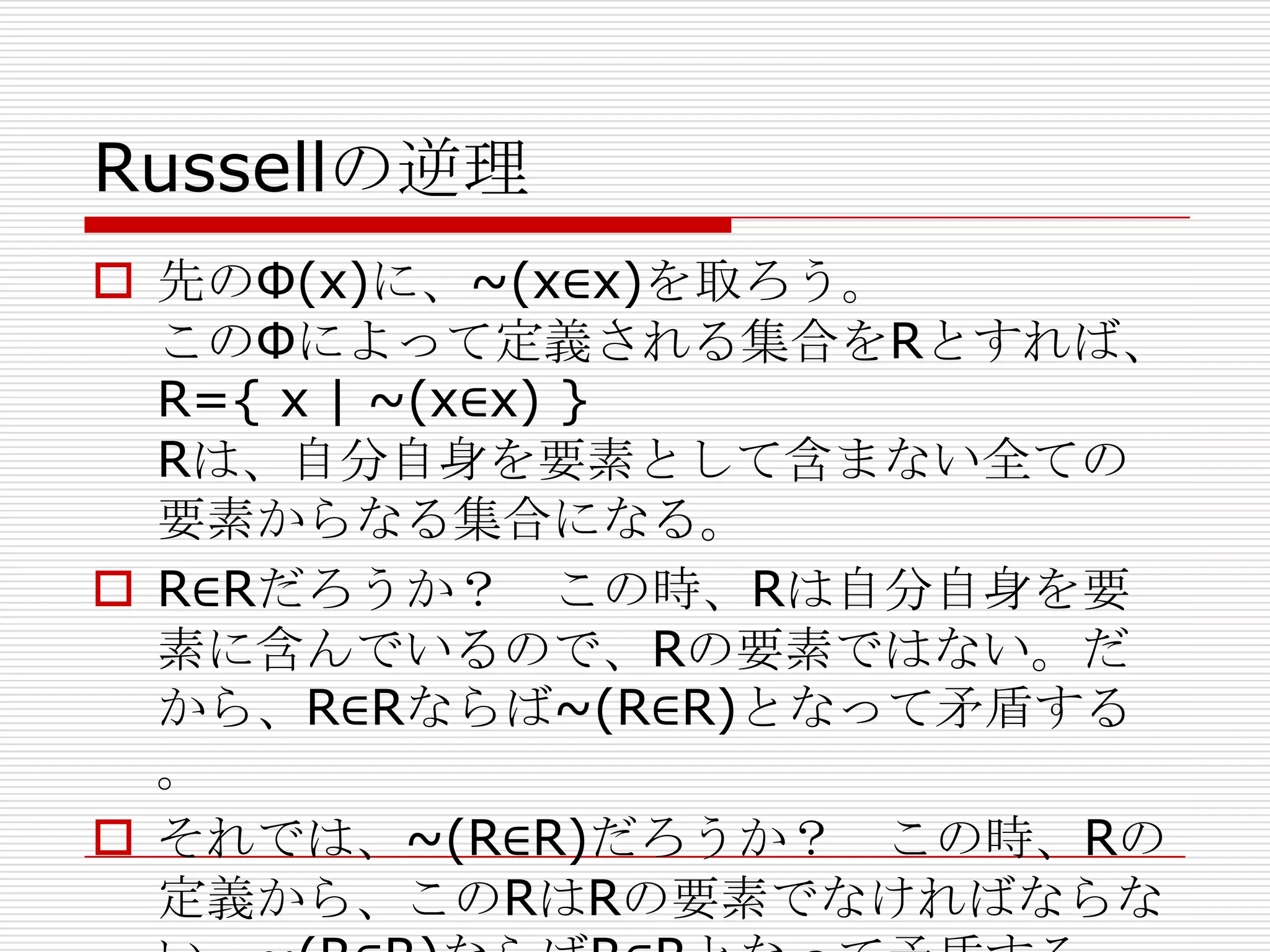
Russell 集合論の逆理と型の理論
計算可能性の原理 〜1930
Church 型のないラムダ計算
型を持つラムダ計算 Church 1940年
型付きラムダ計算と論理との対応
Curry-Howard
Dependent Type Theory
Martin-Löf
1970~
Homotopy Type Theory
Voevodsky
- 12. Russellの型の理論
全ての個体は型 i を持つ。
述語 P(x1,x2,...xn)は、x1,x2,...xn がそれぞ
れ持つ型 i1,i2,...inに応じて、型 (i1,i2,...in)
を持つ。
ある型を持つ述語Pは、この型の階層構造の中
で、その型以下の型を持つ個体に対してのみ
適用出来る。
「全て」を表す全称記号は、その型以下の型
を持つ個体の上を走る。
- 18. 関数の表記としてのλ記法
t = x2+y としよう。このtを、
xの関数としてみることを λx.t で表し、
yの関数としてみることを λy.t で表わそう。
これは、普通の関数で考えると、
λx.t は、 f(x)=x2+y
λy.t は、 g(y)=x2+y
と表記することに相当する。
t = x2+y は、また、xとyの二つの変数の関
数とみることが出来る。これを λxy.t と表そ
う。
λxy.t は、 h(x, y)=x2+y
- 19. 抽象化としてのλ表記
λ記法を使うことによって、上記の f, g, h のよ
うな関数の具体的な名前を使わなくても、関数
のある特徴を抽象的に示すことが出来る。
これをλによる抽象化と呼ぶ。
λによる抽象化の例
λx.(x2 + ax +b) :xの関数としてみた x2 + ax +b
λa.(x2 + ax +b) :aの関数としてみた x2 + ax +b
λb.(x2 + ax +b) :bの関数としてみた x2 + ax +b
λxa.(x2 + ax +b) :xとaの関数としてみた x2 + ax +b
λxab.(x2 + ax +b) :xとaとbの関数としてみた x2 + ax
+b
- 20. 関数の値の計算
関数の値の計算をλ表記で考えよう。
t = x2+y を
xの関数とみた時、x=2の時のtの値は 4+y
yの関数とみた時、y=1の時のtの値は x2+1
x,yの関数とみた時、x=2, y=1の時の値は、5
λで抽象化されたλx.t, λy.tが、例えば、x=2,
y=1の時にとる値は、それぞれ、4+y, x2+1と
いった関数を値として返す関数であることに注
意しよう。
λxy.tの時、二つの変数 x, yに値を与えると、
この関数は、はじめて具体的な値をとる。
- 21. λ式での値の適用
λ式 tに、ある値 sを適用することを、λ式 tの後
ろに、値 sを並べて、t sのように表す。
例えば、次のようになる。
λx.t 2 = λx.(x2+y) 2 = 22+y = 4+y
λy.t 1 = λy.(x2+y) 1 = x2+1
λxy.t 2 1 = λxy.(x2+y) 2 1 = 22+1 = 5
- 22. 変数への値の代入
関数 f(x) が、x = aの時にとる値は、f(x)の
中に現れる x に、x = aの値を代入すること
で得ることが出来る。これは、通常、f(a)と
表わされる。
名前のないλ式 tでの変数 xへの値aの代入に
よる関数の値の計算を、次のように表現する
。
t [x:=a]
もっとも単純なλ式である、x自体が変数であ
る時、代入は次のようになる。
x [x:=a] = a
- 23. 適用と代入
もう尐し、適用と代入の関係を見ておこう。
λ式 λx.tへの、aの適用 (λx.t) aとは、代入
t[x:= a]を計算することである。
(λx.t) a = t[x:=a]
先の例での値の適用の直観的な説明は、代入
を用いると、次のように考えることが出来る
。
λx.t 2 = λx.(x2+y) 2
= (x2+y) [x:=2] = 22+y = 4+y
λy.t 1 = λy.(x2+y) 1
= (x2+y)[y:=1]=x2+1
- 27. ちょっと変わったλ式 1
λ式 Ω := (λx.xx) (λx.xx) を考えよう。
これを計算してみる。
(λx.xx) (λx.xx)
= (λx.xx) (λy.yy)
= xx[x:=λy.yy]
= (λy.yy) (λy.yy)
= (λx.xx) (λx.xx)
となって、同じλ式が現れ、計算が終わらない
。
- 28. ちょっと変わったλ式 2
Y := λg.(λx.g (x x)) (λx.g (x x))とする。
このとき、Y gを計算してみよう。
Yg
= λg.(λx.g (x x)) (λx.g (x x)) g
= λf.(λx.f (x x)) (λx.f (x x)) g
= (λx.g (x x)) (λx.g (x x))
= (λy.g (y y)) (λx.g (x x))
= g (y y)[y:=(λx.g (x x))]
= g ((λx.g (x x)) (λx.g (x x)))
=g(Yg)
すなわち、Y g = g ( Y g )となって、Y gは
、gの不動点を与える。
- 30. ラムダ計算への型の導入
型σから型τへの関数は、型 σ → τ を持つ。
あるλ式 eが型τを持つことを、e : τ と表す。
α, β, ηの変換ルールは同じものとする
この表記の下で、λ式の型の定義を次のように行
う。
1. 単純な変数 vi は型を持つ。 vi : τ
2. e1 : ( σ → τ )で、e2 : σ なら、 (e1 e2) : τ
3. x : σ で e : τ なら、(λxσ.e) : ( σ → τ )
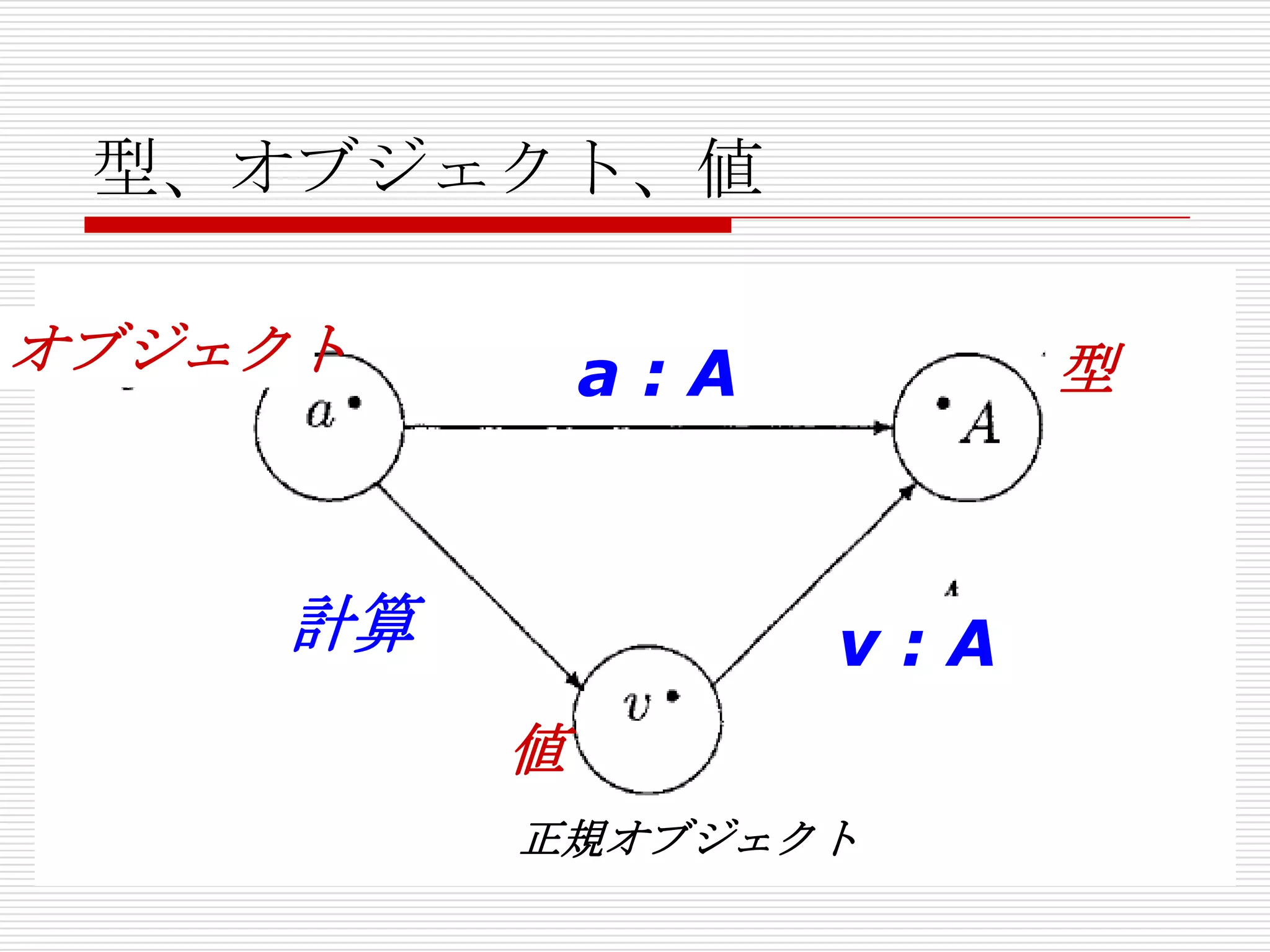
- 33. 型を持つラムダ計算での計算
あるオブジェクト aがある型 Aを持つとい
う判断を、 a : A と表わそう。
型を持つラムダ計算の理論では、計算は、
次の形をしている。
関数 λx:A.b[x] を、型Aに属するオブジ
ェクトaを適用して b[a]を得る。
計算の下で、全てのオブジェクトはユニー
クな値を持つ。また、計算で等しいオブジ
ェクトは、同一の値を持つ。
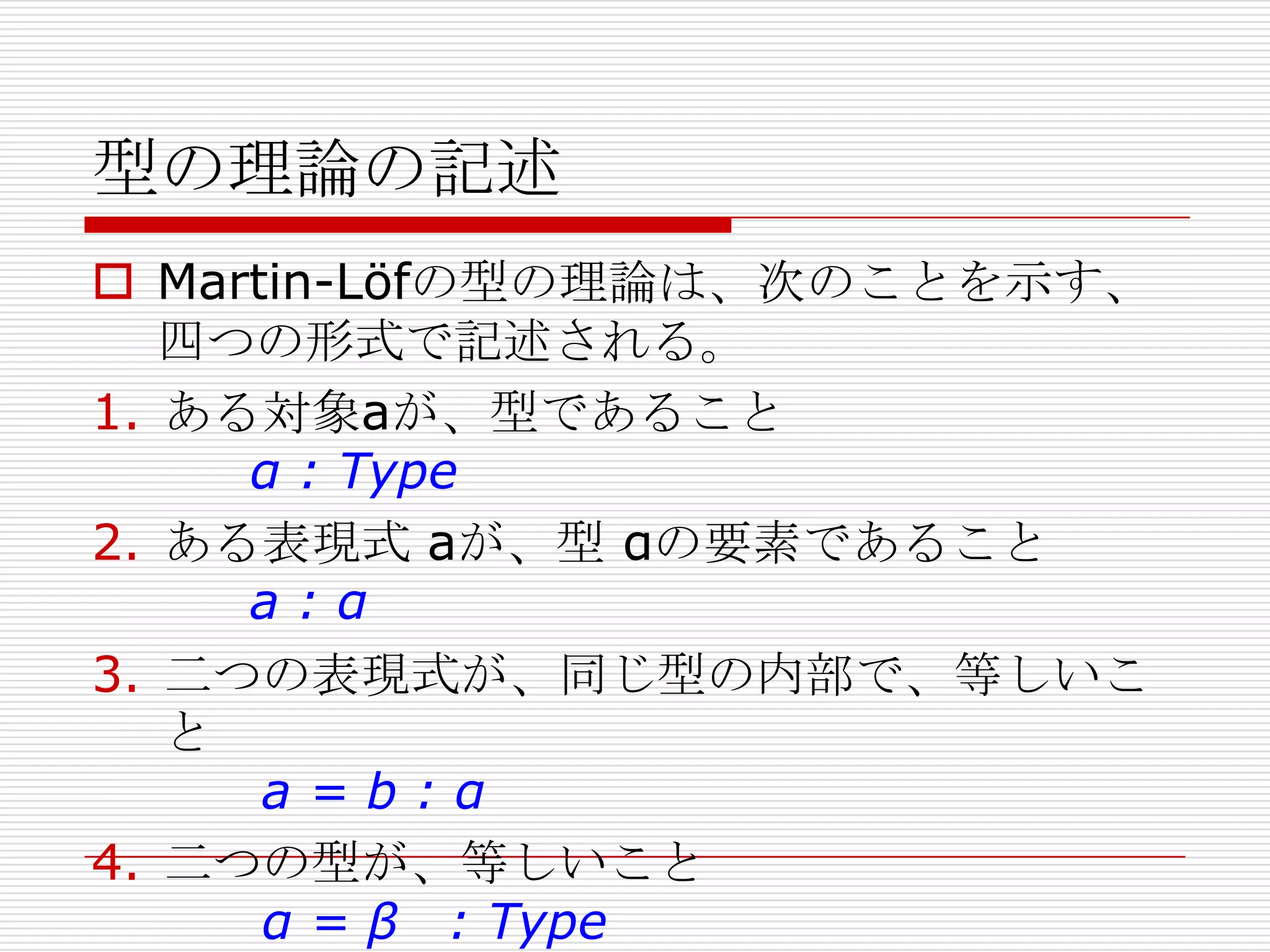
- 39. “Propositions as Types”
“Proofs as Terms”
Howardの洞察は、”Propositions as
Types”, “Proofs as Terms” (これを、PAT
というらしい)として、次にみるMartin-Löf
の型の理論に大きな影響を与えた。
同時に、Curry-Howard対応は、型付きラム
ダ計算をプログラムと見なせば、”Proof as
Program”としても解釈出来る。
こうした観点は、今日のCoq等の証明支援言
語の理論的基礎になっている。
- 42. 同一性への型の付与
Martin-Löf は、式 a = b にも型を与える。
a =A b : Id(A a b)
型 Id(A a b) を持つ式は、a と b は等しいと
いう意味を持つ。
a =A b のAは、型Aの中での同一性であるこ
とを表している。すなわち、a : A で b : Aで
、かつa = bの時にはじめて、a =A b は型
Id(A a b)
を持つ。
ここでは式の同一性について述べたが、式の
同一性と型の同一性は、異なるものである。
- 44. Dependent Type
これまで、A∧B, A → B, A∨B といった、元
になる型 A, B を指定すると新しい型が決ま
るといったスタイルで型を導入してきた。
これとは異なる次のようなスタイル、型Aそ
のものではなく型Aに属する要素 a : Aに応じ
て新しい型 B(a)が変化するような型の導入が
可能である。
例えば、実数R上のn次元のベクトル
Vec(R,n)とn+1次元のベクトルVec(R,n+1)
は、別の型を持つのだが、これは nに応じて
型が変わると考えることが出来る。
- 45. Dependent Type
こうした型をDependent Typeと呼び、次の
ように表す。
Π(x:A).B(x)
Dependent Typeは、ある型Aの値aにディペ
ンドして変化する型である。
先の例のベクトルの型は、次のように表され
る。
Π(x:N).Vec(R,n)
これは、全てのnについてVec(R,n)を考える
ことに対応している。
型の理論では、全称記号は、Dependent
- 46. Dependent Typeと
Polymorphism
Dependent Typeの例を、もう一つあげよう
。
n次元のベクトルは、自然数 N、整数 Z、実
数 R、複素数 C上でも定義出来る。
{ N, Z, R, C } : T とする時、次のように定
義されるDependent Typeを考えよう。
Π( x : T)Vec(x,n)
これは、次元nは同じだが、定義された領域が
異なる別の型
Vec(N,n),Vec(Z,n),Vec(R,n), Vec(C,n)を
考えることに相当する。
- 50. 新しい型の理論 HoTT
Homotopy Type Theory (HoTT) は、数学
者Voevodsky が中心となって構築した、新
しい型の理論である。
HoTTは、数学の一分野であるホモトピー論や
ホモロジー代数と、論理学・計算機科学の一
分野である型の理論とのあいだに、深い結び
つきがあるという発見に端を発している。
ここで取り上げられている型の理論は、
Martin-LöfのDependent Type Theoryであ
る。
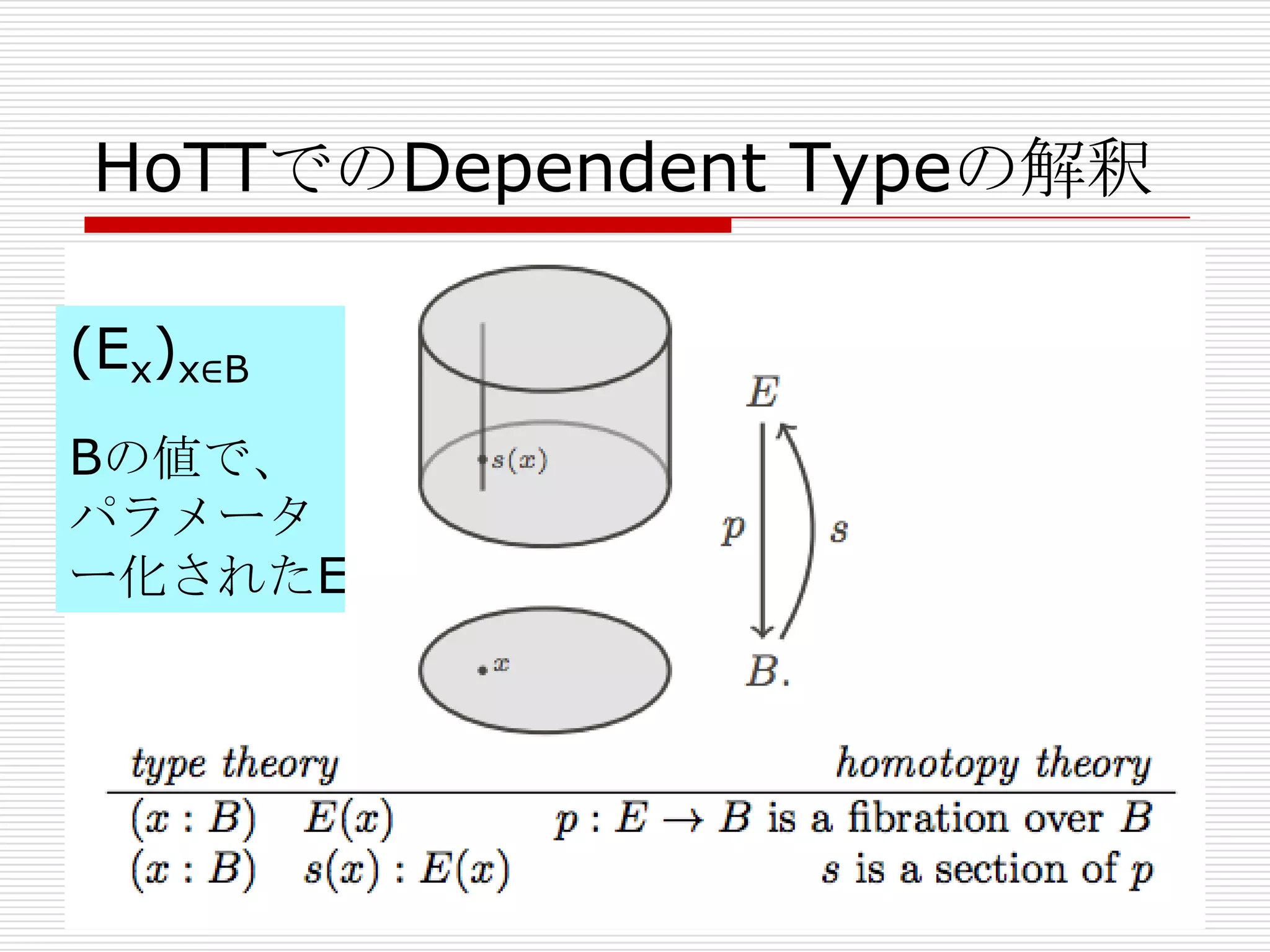
- 51. HoTTでの a : A の解釈
論理=数学的には、 a : A には、様々な解釈がある
。ここでは、他の解釈と比較して、HoTTでの a : A
の解釈を見てみよう。
1. 集合論: Russellの立場
Aは集合であり、aはその要素である。
2. 構成主義: Kolmogorovの立場
Aは問題であり、aはその解決である
3. PAT: Curry & Howardの立場
Aは命題であり、aはその証明である。
4. HoTT: Voevodskyの立場
Aは空間であり、aはその点である。
- 56. Part II
“Proposition as Type”
Curry-Howard対応について
論理式の意味を考える
証明について考える
Propositions as Types and
Proofs as Terms (PAT)
命題とその証明のルール
型とその要素のルール
QuantifierとEquality
- 61. 論理式の意味を考える
Due to Per Martin-Lof
“ON THE MEANINGS OF THE LOGICAL
CONSTANTS AND THE JUSTIFICATIONS OF
THE LOGICAL LAWS”
http://docenti.lett.unisi.it/files/4/1/1/6/mar
tinlof4.pdf
- 69. 証明の解釈
Kolmogorovは、命題 a → bの証明に、「命
題 aの証明を命題 bの証明に変換する方法を
構築すること」という解釈を与えた。
このことは、a → bの証明を、aの証明からb
の証明への関数と見ることが出来るというこ
とを意味する。
このことは、同時に、命題をその証明と同一
視出来ることを示唆する。
型はこうした証明の集まりを表現し、そうし
た証明の一つは、対応する型の、一つの項と
見なすことが出来る。
- 71. 命題の証明は、何から構成されるか
?
形式的に
⊥
A∧B
A∨B
A→B
(∀x)B(x)
(∃x)B(x)
none
Aの証明であるaと、
Bの証明であるbのペア(a,b)
Aの証明であるi(a)、あるいは、
Bの証明であるj(b)
Aの証明であるaに対して、
Bの証明b(a)を与える(λx)b(x)
任意のaに対して
Bの証明b(a)を与える(λx)b(x)
あるaと、B(a)の証明であるbのペア
(a,b)
- 72. Propositions as Types and
Proofs as Terms (PAT)
Due to Simon Thompson
“Type Theory & Functional Programming”
1999
- 77. ∧ を含む命題の証明のルール
Formationルール
A は命題である
B は命題である
(∧F)
(A∧B) は命題である
Introductionルール
p:A
q:B
(∧I)
(p,q) : (A∧B)
Eliminationルール
r : (A∧B) (∧E ) r : (A∧B)
1
(∧E2)
fst r : A
snd r : B
- 79. → を含む命題の証明のルール
Aが命題であり、Bが命題であれば、A→Bは
命題になる。
xが命題Aの証明だと仮定して、eが命題Bの証
明だとしよう。この時、命題A→Bの証明は、
x:Aであるxの関数としてみたe、 (λx:A).eで
ある。
qが命題A→Bの証明で、aが命題Aの証明だと
すれば、関数qにaを適用した(q a)は、命題B
の証明である。
この時、((λx:A).e) a = e[a/x] (eの中
のxを全てaで置き換えたもの) になる。
- 83. ∨ を含む命題の証明のルール
その上で、qが命題Aの証明であれば、inl qが
命題A∨Bの証明を、rがBの証明であれば、inr
rが命題A∨Bの証明を与えると考える。
このことは、命題A∨Bが証明されるのは、命
題Aまたは命題Bのどちらかが証明される場合
に限ることになる。
例えば、命題A∨~Aが証明されるのは、命題A
または命題~Aのどちらかが証明された場合だ
けということになる。この体系では、一般に
「排中律」はなりたたない。
- 85. ∨ を含む命題の証明のルール
Formationルール
A は命題である
B は命題である
(∨F)
(A∨B) は命題である
Introductionルール
q:A
r:B
(∨I1)
(∨I2)
inl q : (A∨B)
inr r : (A∨B)
Eliminationルール
p : (A∨B) f : (A→C) g : (B→C
(∨E)
)
cases p f g : C
- 93. ∧ を含む型のルール
Formationルール
A は型である
B は型である
(∧F)
(A∧B) は型である
Introductionルール
p:A
q:B
(∧I)
(p,q) : (A∧B)
Eliminationルール
r : (A∧B) (∧E ) r : (A∧B)
1
(∧E2)
fst r : A
snd r : B
- 96. → を含む要素の型のルール
Aが型であり、Bが型であれば、A→Bは型に
なる。
xが型Aの要素だと仮定して、eが型Bの要素だ
としよう。この時、型A→Bの要素は、x:Aで
あるxの関数としてみたe、 (λx:A).eである
。
qが型A→Bの要素で、aが型Aの要素だとすれ
ば、関数qにaを適用した(q a)は、型Bの要素
である。
この時、((λx:A).e) a = e[a/x] (eの中
のxを全てaで置き換えたもの) になる。
- 100. ∨ を含む型の要素のルール
Aが型であり、Bが型であれば、A∨Bは型にな
る。
qが型Aの要素であれば、qは型A∨Bの要素を
、rが型Bの要素であれば、rも型A∨Bの要素を
与えるように見える。
ここで、qに「qは∨で結ばれた型の左の型の
型である」という情報を付け加えたものを、
inl qとし、同様に、rに「rは∨で結ばれた型の
右の型の要素である」という情報を付け加え
たものを、inr rと表すことにしよう。
- 101. ∨ を含む型の要素のルール
その上で、qが型Aの要素であれば、inl qが型
A∨Bの要素を、rが型Bの証明であれば、inr r
が型A∨Bの要素を与えると考える。
このことは、型A∨Bが要素を持つのは、型Aま
たは型Bのどちらかが要素を持つ場合に限る
ことになる。
例えば、型A∨~Aが要素を持つのは、型Aまた
は型~Aのどちらかが要素を持つ場合だけとい
うことになる。この体系では、一般に「排中
律」はなりたたない。
- 103. ∨ のルール
Formationルール
A は型である
B は型である
(∨F)
(A∨B) は型である
Introductionルール
q:A
r:B
(∨I1)
(∨I2)
inl q : (A∨B)
inr r : (A∨B)
Eliminationルール
p : (A∨B) f : (A→C) g : (B→C
(∨E)
)
cases p f g : C
- 105. ∨ を含む型のルール
型A∨Bは、型Aと型Bの直和である。
通常のプログラム言語では、値に名前のタグ
がつけられたレコード型と考えてよい。
Eliminationルールは、その名前による場合分
けに相当する。
Computationルールは、pにAのタグがつい
ていれば、f p を計算してCの要素を求め、p
にBのタグがついていれば、 g pを計算して、
Cの要素を求めることを表している。
- 114. 等号 =A を含む型のルール
I(A, a, b) a =A b
Formationルール
Aは型である
a:A b:A
(IF)
I(A, a, b)は型である
Introductionルール
a:A
r(a) : I(A, a, a)
(II)
- 115. 等号 =A を含む型のルール
Eliminationルール
c : I(A, a, b) d : C(a, a, r(a))
(IE)
J(c, d) : C(a, b, c)
Computationルール
J(r(a)、d) = d
- 117. Part III
Coq入門
数学の証明とコンピュータ
Coqとはどんな言語か?
関数型プログラム言語としてのCoq
ListをCoqでプログラムする
証明支援システムとしてのCoq
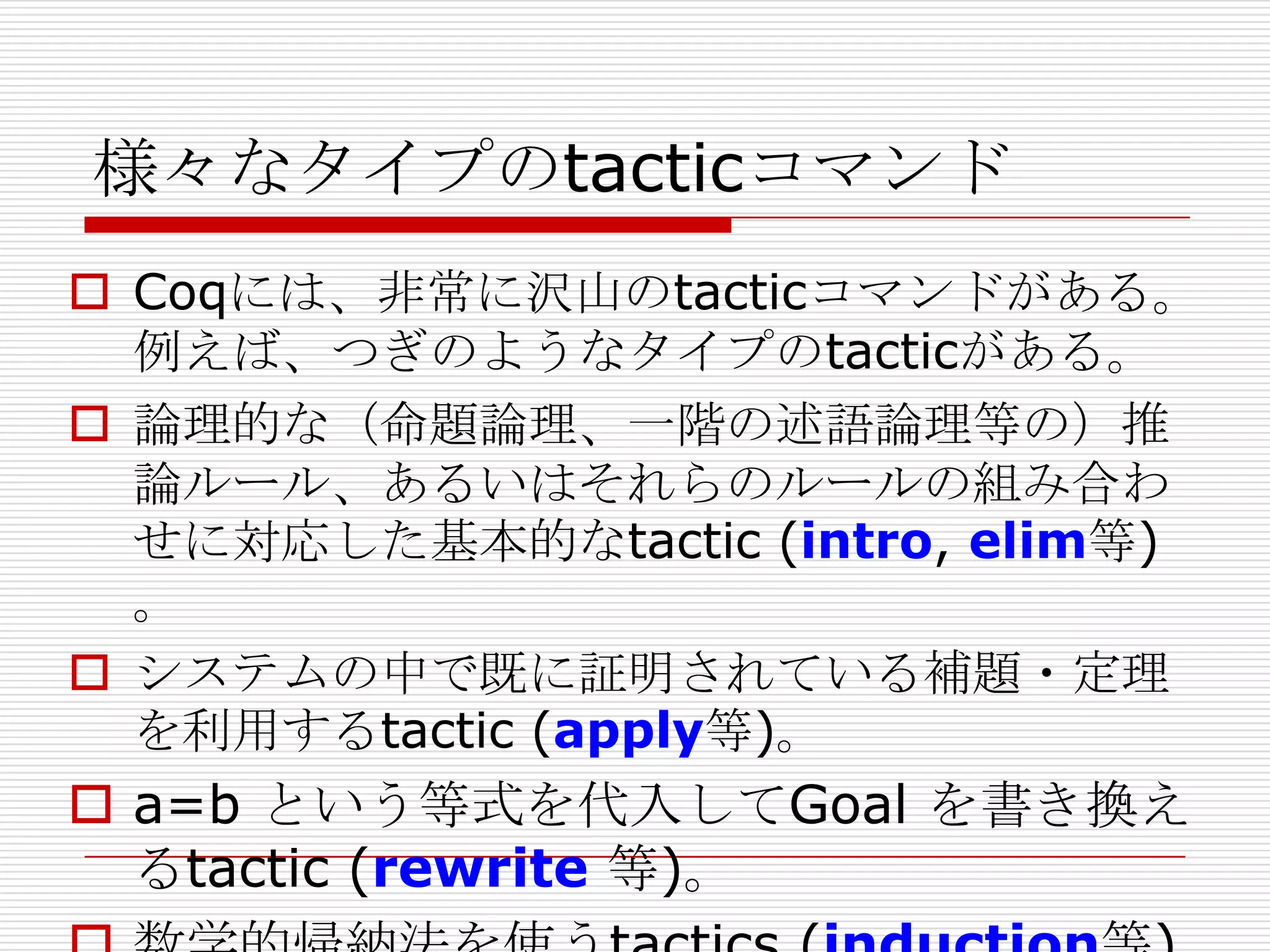
基本的なtacticについて
tacticを使って見る
n x m = m x n を証明する
証明に必要な情報を見つける
二分木についての定理の証明
Coqからのプログラムの抽出
あらためて、p : P (証明 : 命題) を考える
- 122. 「四色問題」のコンピュータによる
解決
1974年、 イリノイ大学のKenneth Appelと
Wolfgang Hakenは、当時の最先端のコンピ
ュータを使って、「四色問題」を解いた。
コンピュータの稼働時間は、1200時間に及び
、夜間の空き時間しか利用が認められなかっ
たので半年がかりの計算だったと言う。
コンピュータが人手にはあまる膨大な計算を
行ったのは事実だが、当時、その計算の正し
さの検証しようのないことを理由に、こうし
た「証明」を疑問視する声も一部にはあった
。
- 126. Coq言語の開発
Coqの開発は、Thierry Coquand とGérard
Huetによって1984年から、INRIA(Institut
National de Recherche en Informatique
et en Automatique フランス国立情報学自
動制御研究所)で開始された。その後、
Christine Paulin-Mohringが加わり、40人以
上の協力者がいる。
最初の公式のリリースは、拡張された素朴な
帰納タイプのCoC 4.10で1989年。1991年
には、Coqと改名された。
- 128. Award 授賞理由
Coq証明支援システムは、 機械でチェックさ
れた形式的推論に対して、豊かなインタラク
ティブな開発環境を与えている。
Coqは、プログラム言語とシステムの研究に
深いインパクトを与え、その基礎へのアプロ
ーチをそれまで全く予想もされなかった規模
と確実さのレベルへと拡大し、そして、それ
らを現実のプログラミング言語とツールにま
で押し広げた。
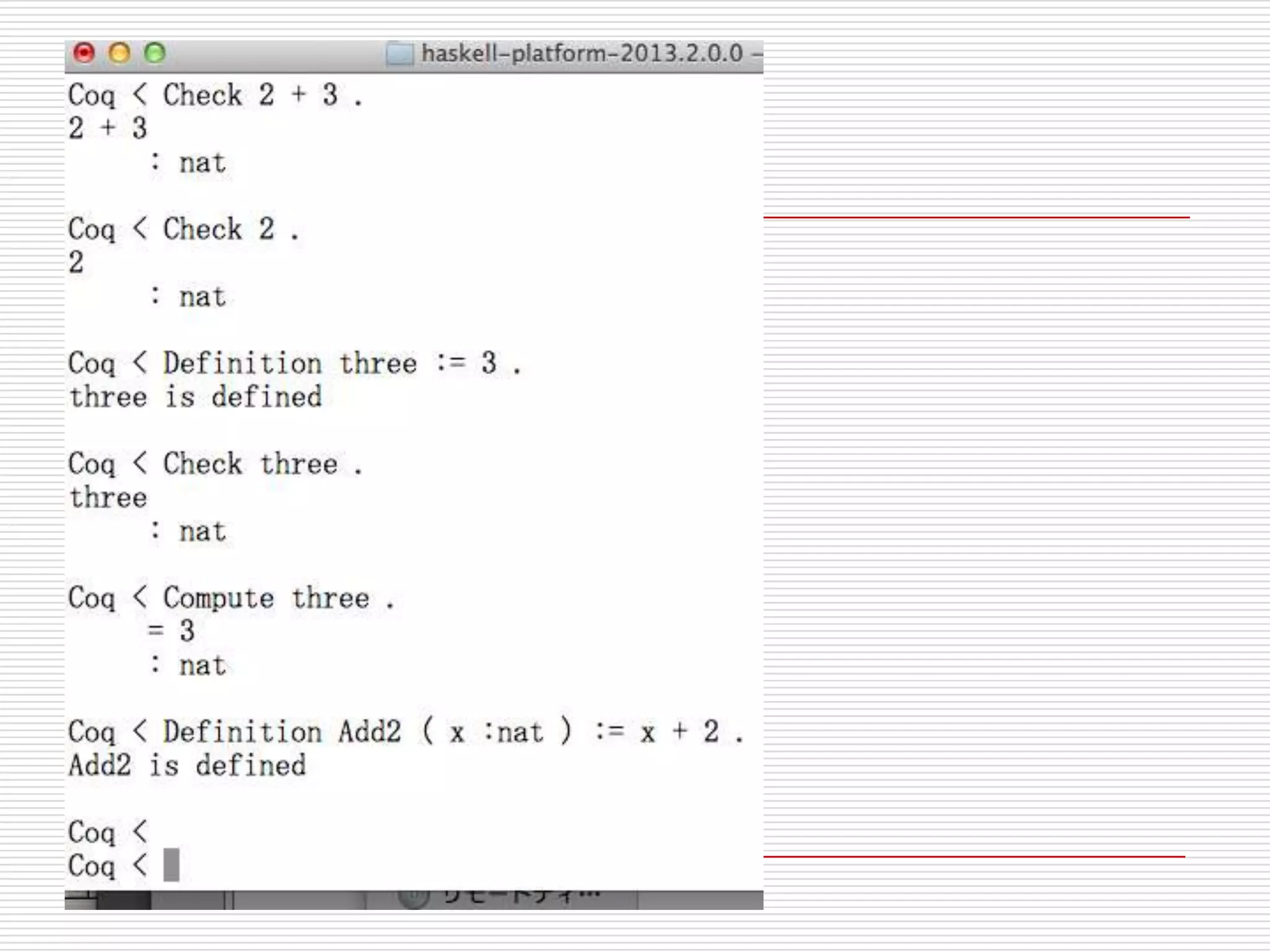
- 136. 型のチェックと定義
Coq < Check 2 + 3.
2 + 3 : nat
Coq < Check 2.
2 : nat
Coq < Check (2 + 3) + 3.
(2 + 3) + 3 : nat
Coq < Definition three := 3.
three is defined
- 137. 型のチェックと定義
Coq < Definition add3 (x : nat) := x + 3.
add3 is defined
Coq < Check add3.
add3 : nat -> nat
Coq < Check add3 + 3.
Error the term "add3" has type "nat -> nat"
while it is expected to have type "nat”
Coq < Check add3 2.
add3 2 : nat
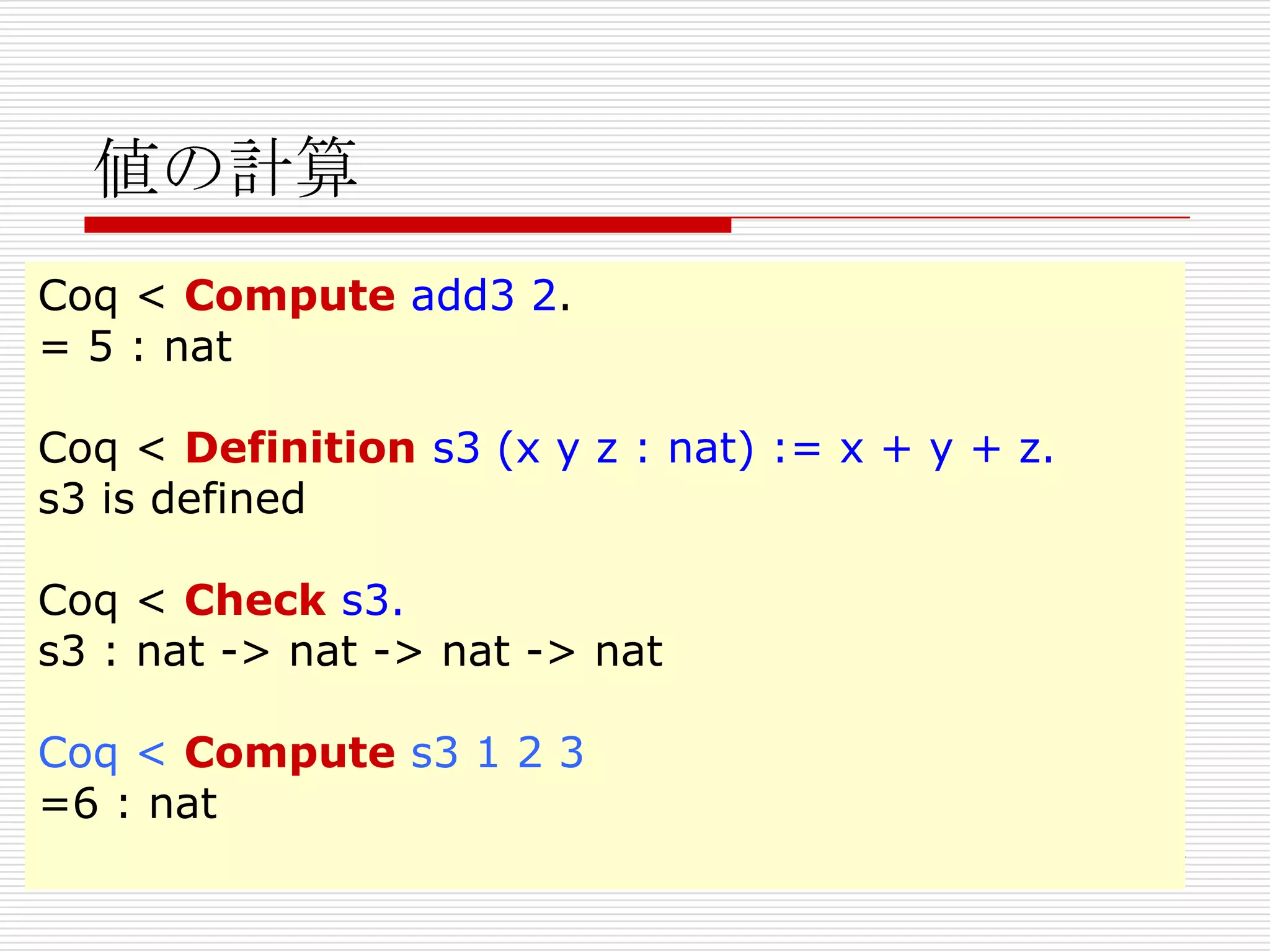
- 138. 値の計算
Coq < Compute add3 2.
= 5 : nat
Coq < Definition s3 (x y z : nat) := x + y + z.
s3 is defined
Coq < Check s3.
s3 : nat -> nat -> nat -> nat
Coq < Compute s3 1 2 3
=6 : nat
- 139. 関数の定義と引数
Coq < Definition rep2 (f : nat -> nat)(x:nat) := f (f x).
rep2 is defined
Coq < Check rep2.
rep2 : (nat -> nat) -> nat -> nat
Coq < Definition rep2on3 (f : nat -> nat) := rep2 f 3.
rep2on3 is defined
Coq < Check rep2on3.
rep2on3 : (nat -> nat) -> nat
- 140. 無名関数の定義
Coq < Check fun (x : nat) => x + 3.
fun x : nat => x + 3 : nat -> nat
Coq < Compute (fun x:nat => x+3) 4.
= 7 : nat
Coq < Check rep2on3 (fun (x : nat) => x + 3).
rep2on3 (fun x : nat => x + 3) : nat
Coq < Compute rep2on3 (fun (x : nat) => x + 3) .
= 9 : nat
- 144. パターン・マッチングによる定義
Definition tail (A : Type) (l:list A) :=
match l with
| x::tl => tl
| nil => nil
end.
Definition isempty (A : Type) (l : list A) :=
match l with
| nil => true
| _ :: _ => false
end.
- 145. パターン・マッチングによる定義
Definition has_two_elts (A : Type) (l : list A) :=
match l with
| _ :: _ :: nil => true
| _ => false
end.
Definition andb b1 b2 :=
match b1, b2 with
| true, true => true
| _, _ => false
end.
- 146. リカーシブな定義
Fixpoint plus n m :=
match n with
| O => m
| S n' => S (plus n' m)
end.
Notation : n + m for plus n m
1+1 = S(O+1)=S(1)=S(S(O))
- 147. リカーシブな定義
Fixpoint minus n m := match n, m with
| S n', S m' => minus n' m'
| _, _ => n
end.
Notation : n - m for minus n m
3-2=2-1=1-0=1
2-3=1-2=0-1=0
- 148. リカーシブな定義
Fixpoint mult (n m :nat) : nat :=
match n with
| 0 => 0
| S p => m + mult p m
end.
Notation : n * m for mult n m
3*2=2+2*2=2+2+2*1=2+2+2+2*0
- 150. list型の定義
listの基本的な定義は、次のものである。
Inductive list (A : Type) : Type :=
| nil : list A
| cons : A -> list A -> list A.
ここで、listは、A : Type なる任意の型に対して
定義されていることに注意しよう。(Polymorphism)
constructor consに対して次の記法を導入する。
infix “::” := cons (at level 60, ....)
- 156. 判断 Γ
|- A
いくつかの命題の集りΓ を仮定すれば、あ
る命題Aが結論として導かれるという判断
を次のように表現しよう。
Γ
|-
A
例えば、次の表現は、命題 P / Q と命題
〜Q から、命題 R → R ∧ Pが導かれるこ
とを表現している。
- 157. 推論ルール
ある判断の集まり Γ1 |- A1, Γ2 |- A2, ...
Γn |- Anから、別の判断 Γ |- Bが導かれる
時、それを推論ルールと呼び、次のように
表す。
Γ1 |- A1 Γ2 |- A2 ... Γn |- An
Γ |- B
例えば、次の表現は、一つの推論ルールで
ある。
- 160. Coqでの演繹ルールの適用 tactic
GoalからSub Goalの導出は、与えられた推
論ルールの(後ろ向きの)適用に基づくのだ
が、Coqでは、その操作をtacticを適用する
という。
tacticには、いろいろな種類があり、それぞ
れのtacticsが、Coqのインタラクティブな証
明支援システムの中で、証明を進める為のコ
マンドとして機能する。
Coqでの証明とは、あるGoalに対して、全て
のSub Goalがなくなるような、一連のtactic
コマンドを与えることである。
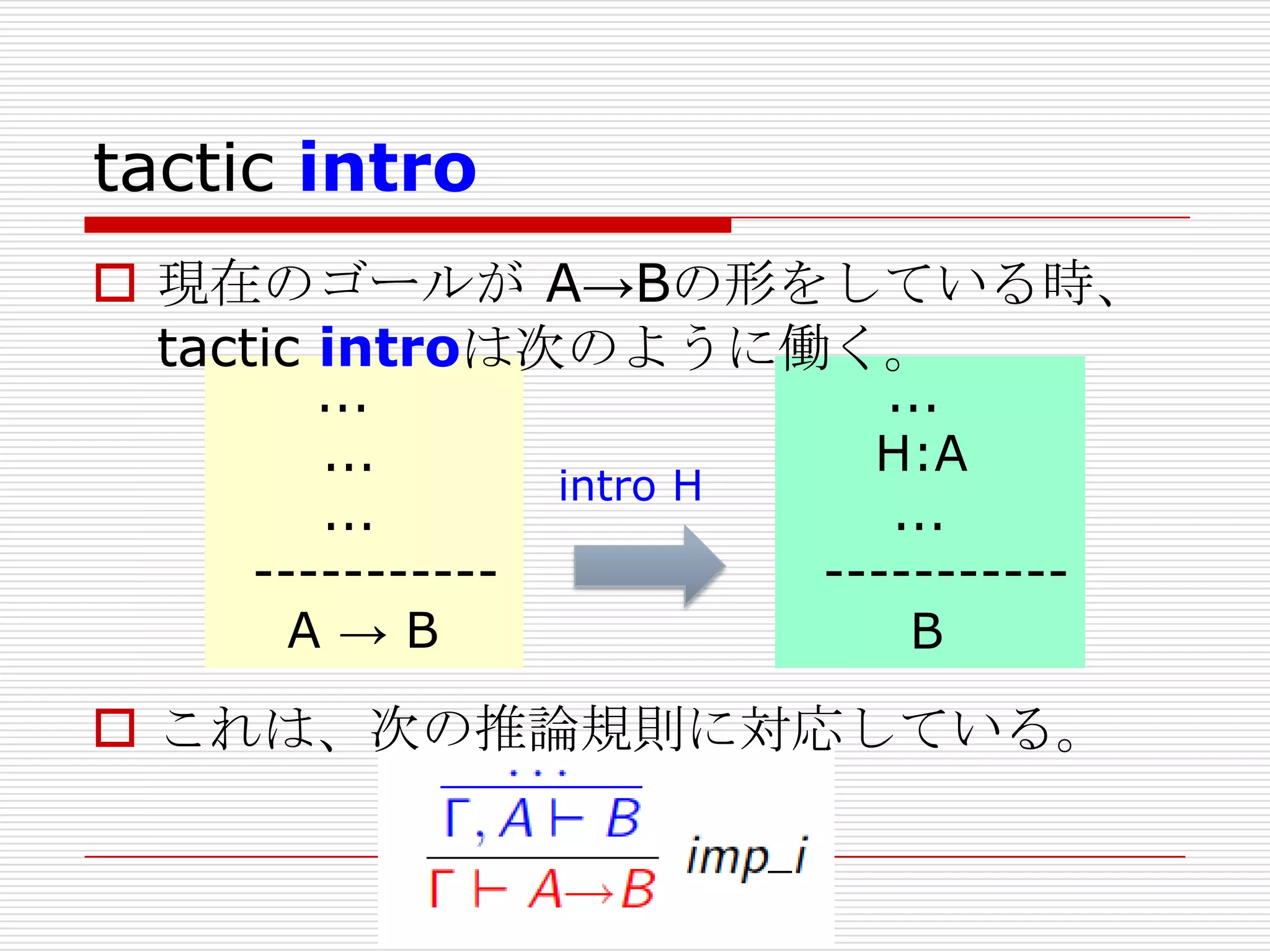
- 164. tactic intro
現在のゴールが A→Bの形をしている時、
tactic introは次のように働く。
...
...
...
----------A→B
intro H
...
H:A
...
----------B
これは、次の推論規則に対応している。
- 166. tactic apply
より一般に、apply Hはn個のサブゴールを生
み出す。
...
...
...
H: A1→A2→...An→ A
H: A1→...
H: An→...
apply H
...
...
...
--------------------------- ... ----------A
A1
An
対応する推論規則は。
- 170. 1 subgoal:
introとapplyのサンプル
P : Prop
Q : Prop
R : Prop
T : Prop
H:P→Q→R
H0 : P → Q
p:P
-----------------------Q
apply H0;assumption.
Proof completed
Qed.
imp dist is dened
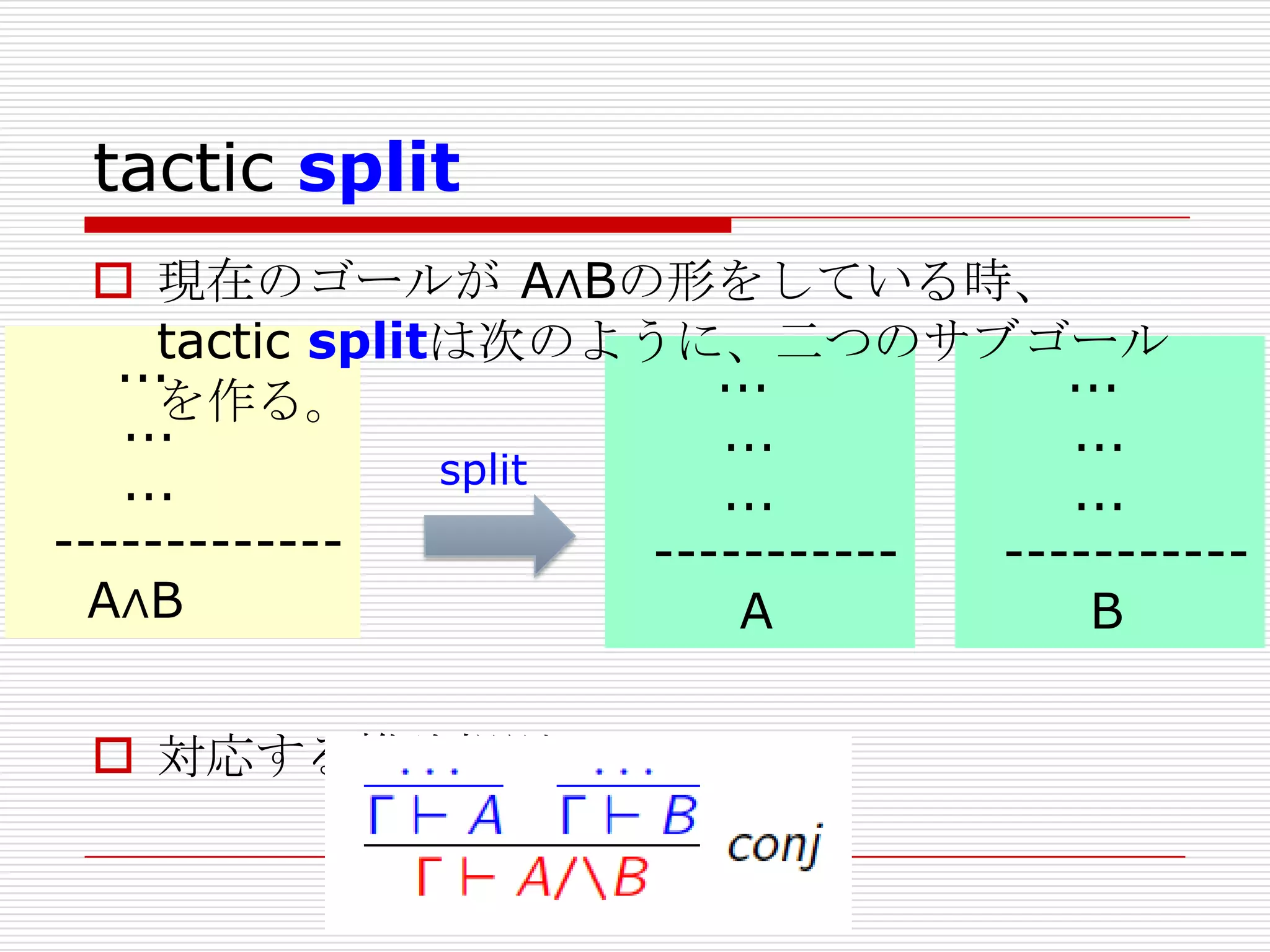
- 171. tactic split
現在のゴールが A∧Bの形をしている時、
tactic splitは次のように、二つのサブゴール
...
...
...
を作る。
...
...
...
split
...
...
...
--------------------------------A∧B
A
B
対応する推論規則は。
- 175. destruct H as [H1 H2].
1 subgoal
P : Prop
Q destructとsplitのサンプル
: Prop
H1 : P
H2 : Q
-----------------------Q∧P
split.
2 subgoals
P : Prop
Q : Prop
H1 : P
H2 : Q
-----------------------Q
subgoal 2 is:
P
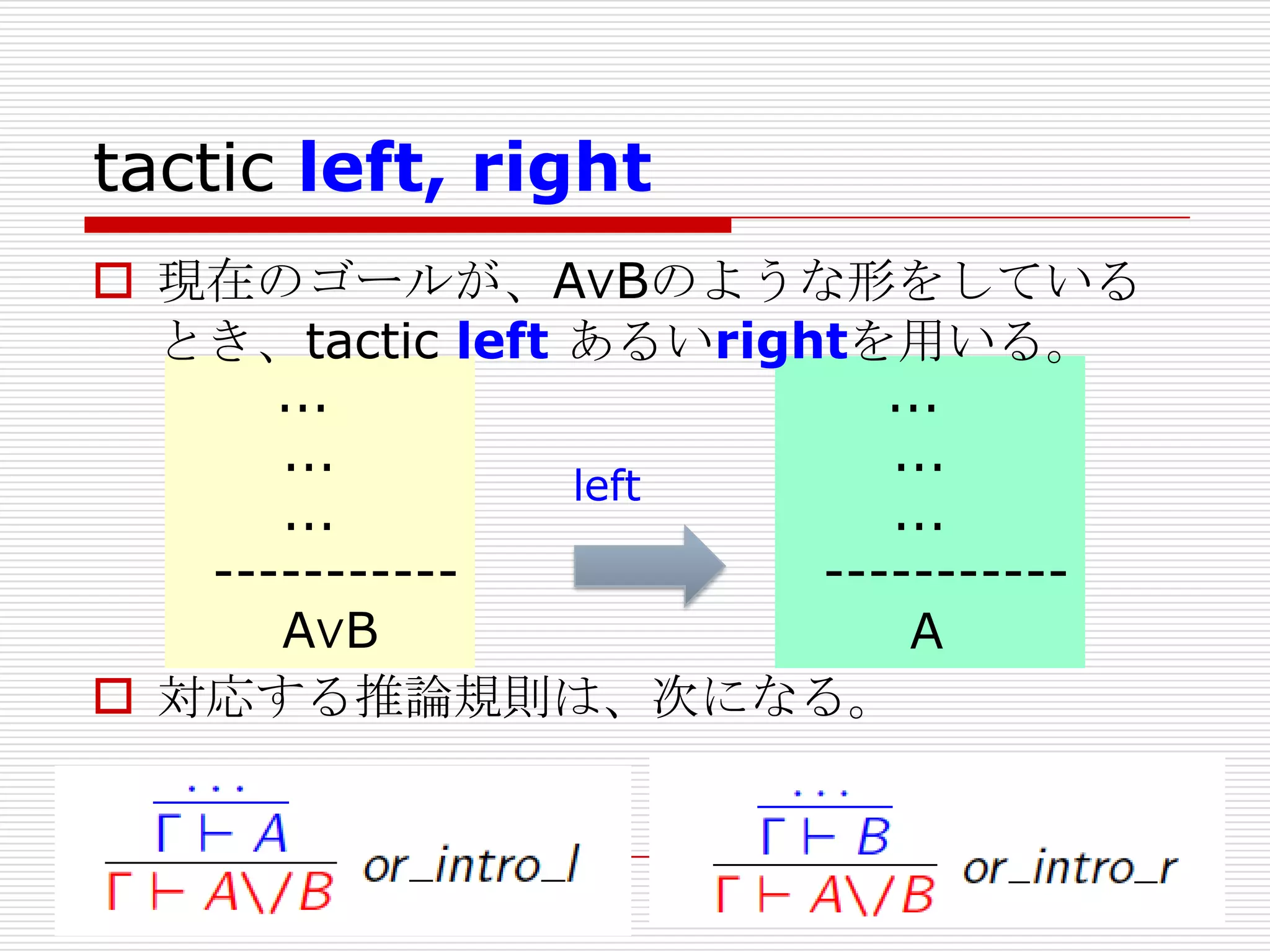
- 176. tactic left, right
現在のゴールが、A∨Bのような形をしている
とき、tactic left あるいrightを用いる。
...
...
...
...
left
...
...
--------------------A∨B
A
対応する推論規則は、次になる。
- 177. tactic destruct
現在の仮定が A∨Bの形をしている時、tactic
destructは、二つのサブゴールを作る。
...
destruct H
A∨B
as [H1 H2]
...
------------C
対応する推論規則は。
...
H1: A
...
----------C
...
H2: B
...
----------C
- 179. destruct H as [H0 | H0].
two subgoals
P : Prop
Q : Prop
H:P∨Q
H0 : P
-----------------------Q∨P
subgoal 2 is :
Q∨P
right; assumption.
left; assumption.
Qed.
- 181. 例1
A -> (A->B) ->B の証明
Coq < Lemma S1 : forall A B :Prop, A ->(A->B) ->B.
1 subgoal
============================
forall A B : Prop, A -> (A -> B) -> B
Goalから、forallを消す。
S1 < intros. →の前提部分を仮説に移す。
1 subgoal
introsは、複数のintroを同時に適用する。
A : Prop
B : Prop
Γ1 新しい仮定
H:A
H0 : A -> B
============================
B
新しいゴール
- 182. S1 < apply H0.
1 subgoal
H0 A->B を利用する。
Aをゴールに移す。
A : Prop
B : Prop
Γ2 新しい仮定
H:A
H0 : A -> B
============================
A
新しいゴール
S1 < assumption. 仮定には、既にAが含まれている
No more subgoals.
S1 < Qed. 証明終わり
intros.
apply H0.
assumption.
S1 is defined
- 183. 例3
(P / Q) / ~Q) -> ( R -> R /P)の証明
Coq < Lemma S3: forall P Q R : Prop,
(P / Q) / ~Q -> ( R -> R /P).
1 subgoal
============================
forall P Q R : Prop, (P / Q) / ~ Q -> R -> R / P
S3 < intros.
1 subgoal
Goalから、forallを消す。
→の前提部分を仮説に移す。
P : Prop
Q : Prop
R : Prop
Γ1 新しい仮定
H : (P / Q) / ~ Q
H0 : R
============================
R / P
新しいゴール
- 184. S3 < split.
2 subgoals
ゴールのR∧Pを、二つの
サブゴールに分割する
P : Prop
Q : Prop
Γ1 仮定
R : Prop
H : (P / Q) / ~ Q
H0 : R
============================
新しいゴール
R
subgoal 2 is: もう一つの新しいゴール。
P
仮定部分は表示されていない
S3 < assumption.
ゴールのRは、既に仮定に含まれている。
これで、一つのゴールの証明は終わり、
証明すべきゴールは、一つになった。
- 185. 1 subgoal
P : Prop
Q : Prop
Γ1 仮定
R : Prop
H : (P / Q) / ~ Q
H0 : R
============================
新しいゴール
P
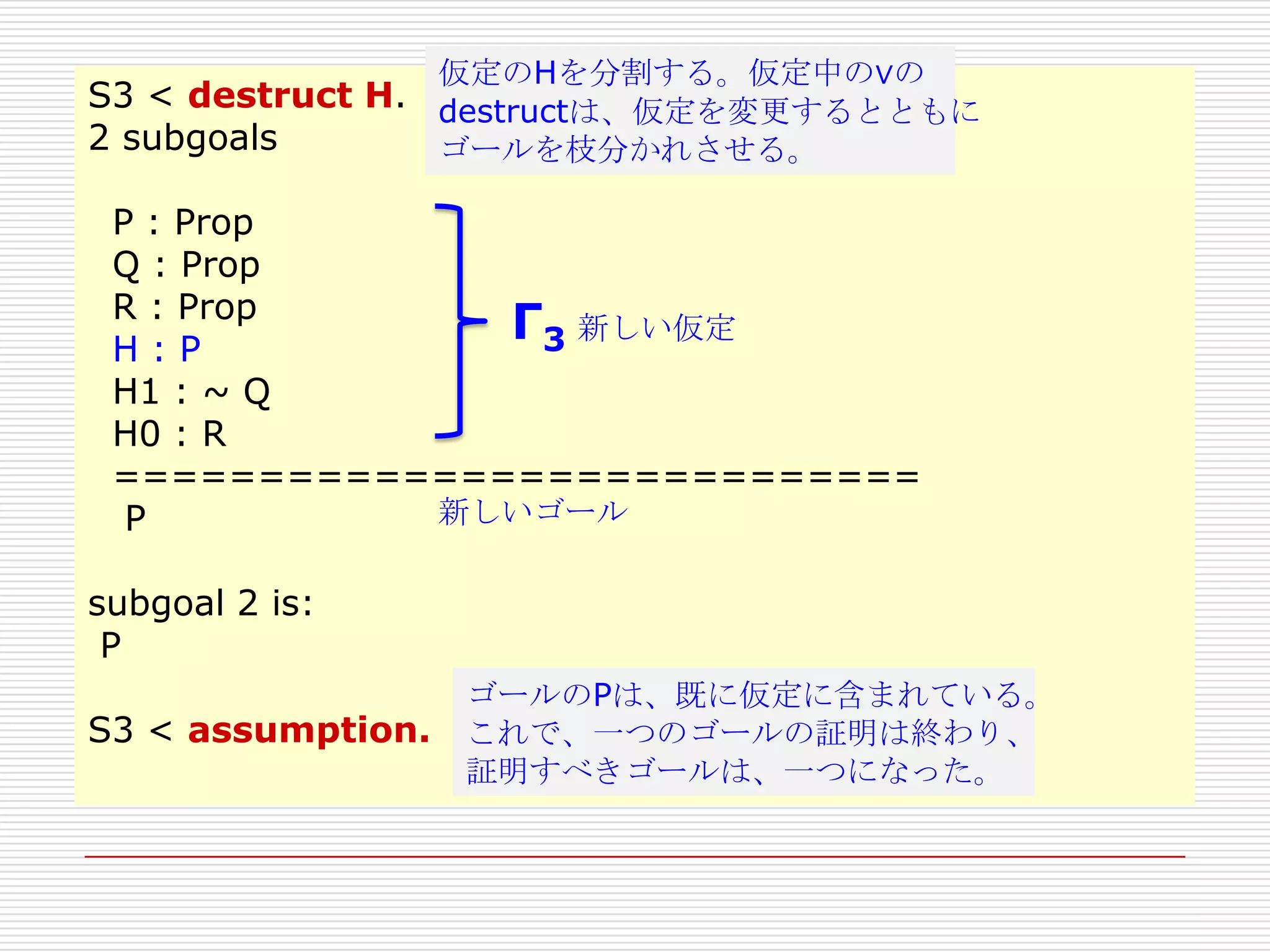
S3 < destruct H. 仮定のHを分割する。仮定中の∧の
destructは、仮定を変更する。
1 subgoal
P : Prop
Q : Prop
R : Prop
Γ2 新しい仮定
H : P / Q
H1 : ~ Q
H0 : R
============================
新しいゴール
P
- 186. 仮定のHを分割する。仮定中の∨の
S3 < destruct H. destructは、仮定を変更するとともに
2 subgoals
ゴールを枝分かれさせる。
P : Prop
Q : Prop
R : Prop
Γ3 新しい仮定
H:P
H1 : ~ Q
H0 : R
============================
新しいゴール
P
subgoal 2 is:
P
S3 < assumption.
ゴールのPは、既に仮定に含まれている。
これで、一つのゴールの証明は終わり、
証明すべきゴールは、一つになった。
- 187. 1 subgoal
P : Prop
Q : Prop
R : Prop
Γ4 新しい仮定
H:Q
H1 : ~ Q
H0 : R
============================
新しいゴール
P
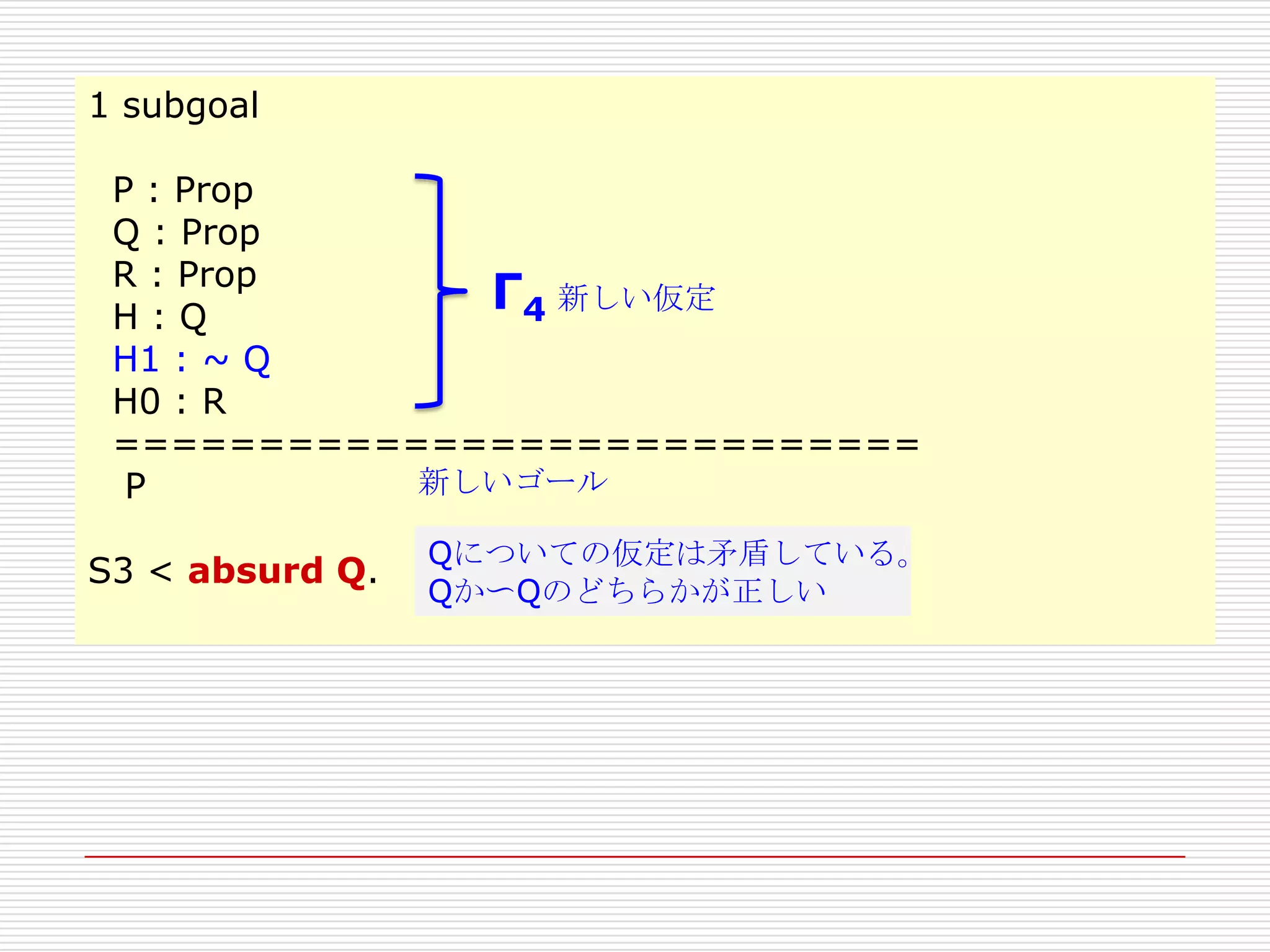
S3 < absurd Q.
Qについての仮定は矛盾している。
Qか〜Qのどちらかが正しい
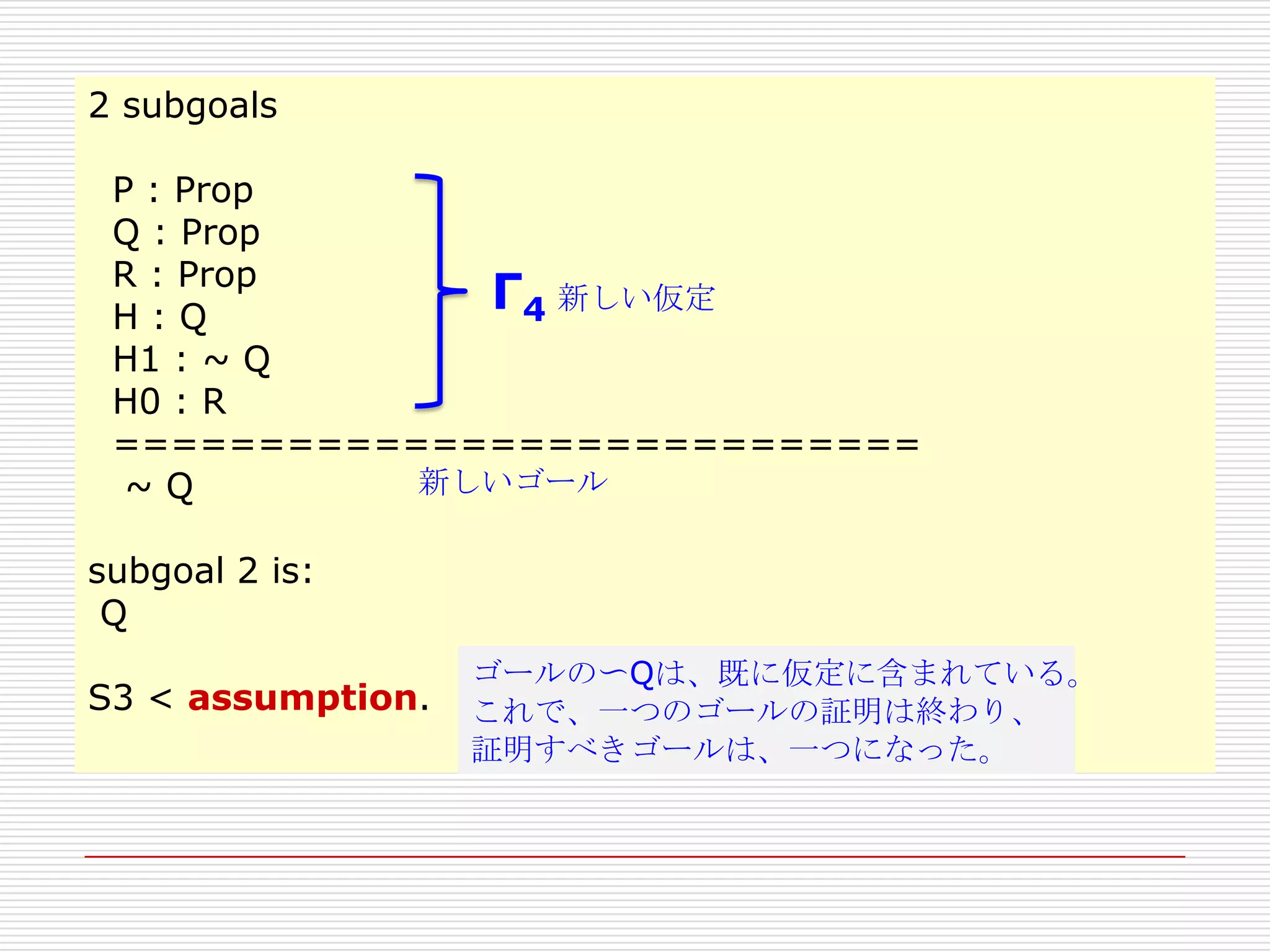
- 188. 2 subgoals
P : Prop
Q : Prop
R : Prop
Γ4 新しい仮定
H:Q
H1 : ~ Q
H0 : R
============================
新しいゴール
~Q
subgoal 2 is:
Q
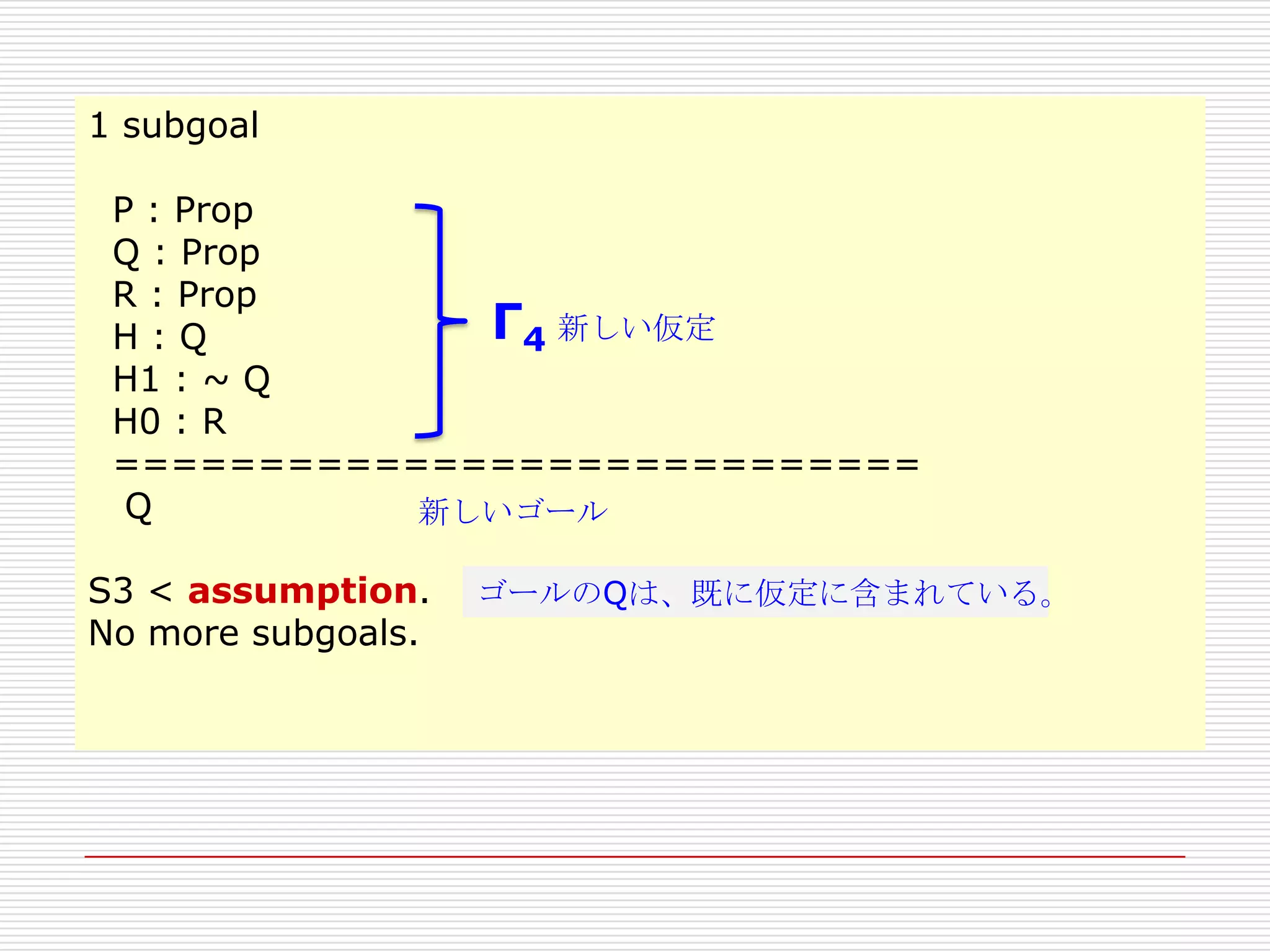
S3 < assumption.
ゴールの〜Qは、既に仮定に含まれている。
これで、一つのゴールの証明は終わり、
証明すべきゴールは、一つになった。
- 189. 1 subgoal
P : Prop
Q : Prop
R : Prop
Γ4 新しい仮定
H:Q
H1 : ~ Q
H0 : R
============================
Q
新しいゴール
S3 < assumption.
No more subgoals.
ゴールのQは、既に仮定に含まれている。
- 192. n x m = m x nの
nについての帰納法での証明
n=0 の時
0xm=mx0
0 = 0 となり、成り立つ。
n x m = m x n が成り立つと仮定して、
(n + 1) x m = m x (n + 1) を証明する。
左辺 = n x m + m
右辺 = m x n + m
帰納法の仮定より、n x m = m x n なので
、これを左辺に代入すると、左辺=右辺とな
る。
- 193. ただ、先の証明には、いくつかの前
提がある
補題1 0 x m = 0
補題2 m x 0 = 0
補題3 (n + 1) x m = n x m + m
補題4 m x (n +1) = m x n + m
これらの補題を使って
定理 n x m = m x n
を証明する。
- 194. 次の補題が証明されたとしよう
Lemma lemma1:
forall n:nat, 0 * n = 0.
Lemma lemma2 :
forall n:nat, n * 0 = 0.
Lemma lemma3:
forall n m:nat, S n * m = n * m + m.
Lemma lemma4:
forall n m:nat, m * S n = m * n + m.
- 195. この時、定理の証明は次のように進
む
Coq < Theorem Mult_Commute : forall n m:nat, n * m = m * n.
1 subgoal
============================
forall n m : nat, n * m = m * n
Mult_Commute < intros.
1 subgoal
forallを消す。
n : nat
m : nat
============================
n*m=m*n
- 196. Mult_Commute < induction n. nについての帰納法で証明する。
2 subgoals
m : nat
============================
0*m=m*0
n = 0の場合。
subgoal 2 is:
Sn*m=m*Sn
Mult_Commute < simpl.
2 subgoals
nで成り立つと仮定して、n+1で
成り立つことを示す。
0 * m = 0 は、定義からすぐに
言えるので、単純化する。
m : nat
============================
0=m*0
subgoal 2 is:
Sn*m=m*Sn
Mult_Commute < auto.
単純な式は、autoでも証明出来る。
- 197. 1 subgoal
n : nat
m : nat
IHn : n * m = m * n
============================
Sn*m=m*Sn
Mult_Commute < rewrite lemma4.
1 subgoal
lemma4 : m * S n = m * n + m を
使って、ゴールを書き換える。
n : nat
m : nat
IHn : n * m = m * n
============================
Sn*m=m*n+m
- 198. Mult_Commute < rewrite lemma3.
1 subgoal
lemma3 : (S n) * m = n * m + m を
使って、ゴールを書き換える。
n : nat
m : nat
IHn : n * m = m * n
============================
n*m+m=m*n+m
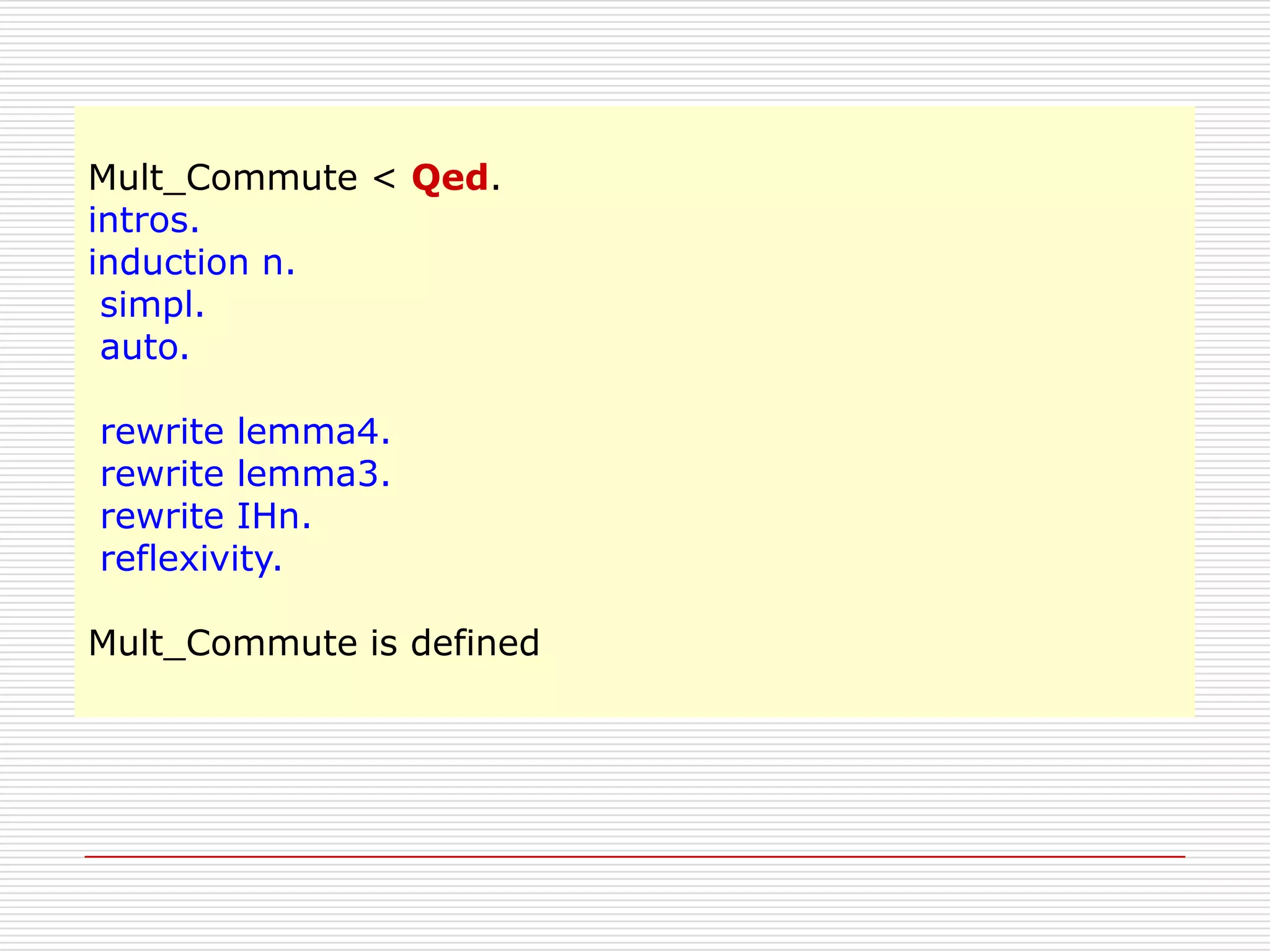
Mult_Commute < rewrite IHn.
1 subgoal
IHn : n * m = m * n を
使って、ゴールを書き換える。
n : nat
m : nat
IHn : n * m = m * n
============================
m*n+m=m*n+m
Mult_Commute < reflexivity.
No more subgoals.
左辺と右辺は等しい
- 200. 補題1の証明
Coq < Lemma lemma1: forall n:nat, 0 * n = 0.
1 subgoal
============================
forall n : nat, 0 * n = 0
lemma1 < intros.
1 subgoal
n : nat
============================
0*n=0
- 201. lemma1 < induction n.
2 subgoals
============================
0*0=0
subgoal 2 is:
0*Sn=0
lemma1 < simpl.
2 subgoals
============================
0=0
subgoal 2 is:
0*Sn=0
- 202. lemma1 < reflexivity.
1 subgoal
n : nat
IHn : 0 * n = 0
============================
0*Sn=0
Fixpoint mult (n m :nat) : nat :=
lemma1 < constructor.
No more subgoals.
lemma1 < Qed.
intros.
induction n.
simpl.
reflexivity.
constructor.
lemma1 is defined
match n with
| 0 => 0
| S p => m + mult p m
end.
という定義を考えよう。この時。コンストラクタ
0が、この式が成り立つことを示している。
先の証明で、simpl. auto. で証明したのも
同じことである。
- 203. lemma1 < induction n.
2 subgoals
============================
0*0=0
subgoal 2 is:
0*Sn=0
lemma1 < simpl.
2 subgoals
============================
0=0
subgoal 2 is:
0*Sn=0
- 204. lemma1 < reflexivity.
1 subgoal
n : nat
IHn : 0 * n = 0
============================
0*Sn=0
lemma1 < constructor.
No more subgoals.
lemma1 < Qed.
intros.
induction n.
simpl.
reflexivity.
constructor.
lemma1 is defined
- 205. 補題2の証明
Coq < Lemma lemma2: forall n:nat, n * 0 = 0.
intros.
単純な式は、autoでも証明出来る。
auto with arith.
こちらは、もっとキチンとした書き方。
Qed.
- 206. 補題3の証明
Coq < Lemma lemma3: forall n m:nat, S n * m = n * m + m.
1 subgoal
============================
forall n m : nat, S n * m = n * m + m
lemma3 < intros.
1 subgoal
n : nat
m : nat
============================
Sn*m=n*m+m
- 207. lemma3 < simpl.
1 subgoal
n : nat
m : nat
============================
m+n*m=n*m+m
plus_comm : forall n m : nat,
lemma3 < apply plus_comm. n + m = m + n
で。和の可換性を示す補題。
No more subgoals.
既に証明されたものとして、証明中で
利用出来る。
lemma3 < Qed.
intros.
simpl.
apply plus_comm.
lemma3 is defined
- 208. 補題4の証明
Coq < Lemma lemma4: forall n m:nat, m * S n = m * n + m.
1 subgoal
============================
forall n m : nat, m * S n = m * n + m
lemma4 < intros.
1 subgoal
n : nat
m : nat
============================
m*Sn=m*n+m
- 209. lemma4 < symmetry.
1 subgoal
n : nat
m : nat
============================
m*n+m=m*Sn
lemma4 < apply mult_n_Sm.
No more subgoals.
lemma4 < Qed.
intros.
symmetry.
apply mult_n_Sm.
lemma4 is defined
mult_n_Sm : forall n m : nat,
n*m+n=n*Sm
を利用する。この補題は、意外と証明が
難しい。
- 211. 証明に必要な定理・補題を見つける
Search
Coqは、証明に利用出来る定理・補題のデ
ータベースを持っている。
Search コマンドを使うと、それらの名前
と型が検索出来る。
Coq < Search le.
le_S: forall n m : nat, n <= m -> n <= S m
le_n: forall n : nat, n <= n
plus_le_reg_l: forall n m p : nat, p + n <= p + m -> n <= m
plus_le_compat_r: forall n m p : nat, n <= m -> n + p <= m + p
plus_le_compat_l: forall n m p : nat, n <= m -> p + n <= p + m
plus_le_compat: forall n m p q : nat, n <= m -> p <= q -> n + p <= m + q
nth_le:
forall (P Q : nat -> Prop) (init l n : nat),
P_nth P Q init l n -> init <= l
......
- 212. 文字列を使って検索する
SearchAbout
Coq < SearchAbout "comm".
Bool.orb_comm: forall b1 b2 : bool, (b1 || b2)%bool = (b2 || b1)%bool
Bool.andb_comm: forall b1 b2 : bool, (b1 && b2)%bool = (b2 && b1)%bool
Bool.xorb_comm: forall b b' : bool, xorb b b' = xorb b' b
app_comm_cons:
forall (A : Type) (x y : Datatypes.list A) (a : A),
a :: x ++ y = (a :: x) ++ y
and_comm: forall A B : Prop, A / B <-> B / A
or_comm: forall A B : Prop, A / B <-> B / A
Max.max_comm: forall n m : nat, max n m = max m n
Min.min_comm: forall n m : nat, min n m = min m n
mult_comm: forall n m : nat, n * m = m * n
plus_comm: forall n m : nat, n + m = m + n
Relation_Definitions.commut:
forall A : Type,
Relation_Definitions.relation A -> Relation_Definitions.relation A -> Prop
....
....l
- 213. パターンを使って検索する
SearchPattern
Coq < SearchPattern (_ + _ = _ + _).
plus_permute_2_in_4: forall n m p q :
nat, n + m + (p + q) = n + p + (m + q)
plus_permute: forall n m p : nat, n + (m + p) = m + (n + p)
plus_comm: forall n m : nat, n + m = m + n
plus_assoc_reverse: forall n m p : nat, n + m + p = n + (m + p)
plus_assoc: forall n m p : nat, n + (m + p) = n + m + p
plus_Snm_nSm: forall n m : nat, S n + m = n + S m
....
....
先の mult_n_Smは、次のような検索で
見つけることが出来る。
Coq < SearchPattern (_ + _ = _ * _).
mult_n_Sm: forall n m : nat, n * m + n = n * S m
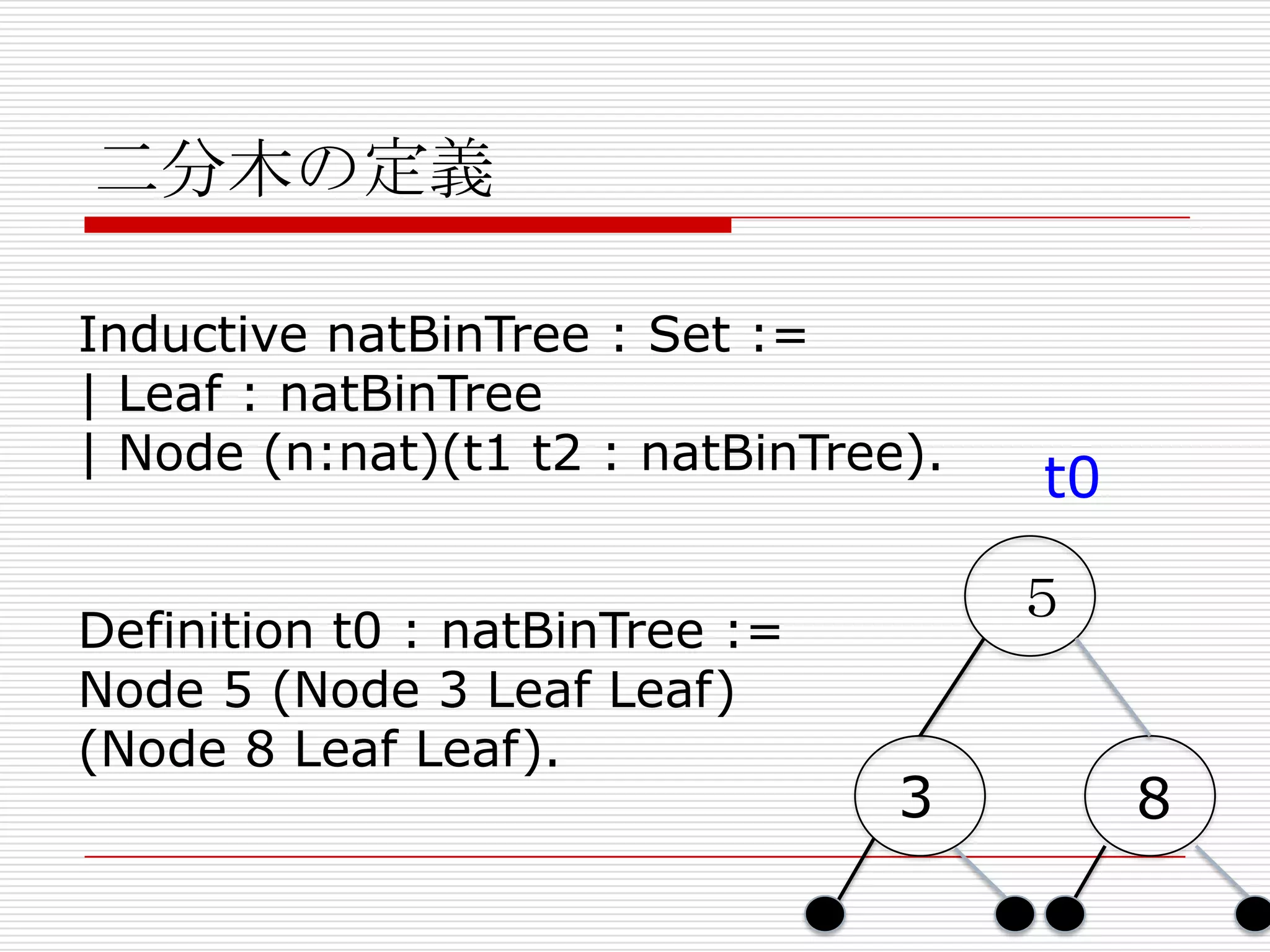
- 216. 二分木の定義
Inductive natBinTree : Set :=
| Leaf : natBinTree
| Node (n:nat)(t1 t2 : natBinTree).
Definition t0 : natBinTree :=
Node 5 (Node 3 Leaf Leaf)
(Node 8 Leaf Leaf).
t0
5
3
8
- 217. Fixpoint tree_size (t:natBinTree): nat :=
match t with
| Leaf =>
| Node _ t1 t2 => 1 + tree_size t1
+ tree_size t2
end.
Require Import Max.
Fixpoint tree_height (t: natBinTree) : nat :=
match t with
| Leaf => 1
| Node _ t1 t2 => 1 + max (tree_height t1)
(tree_height t2)
end.
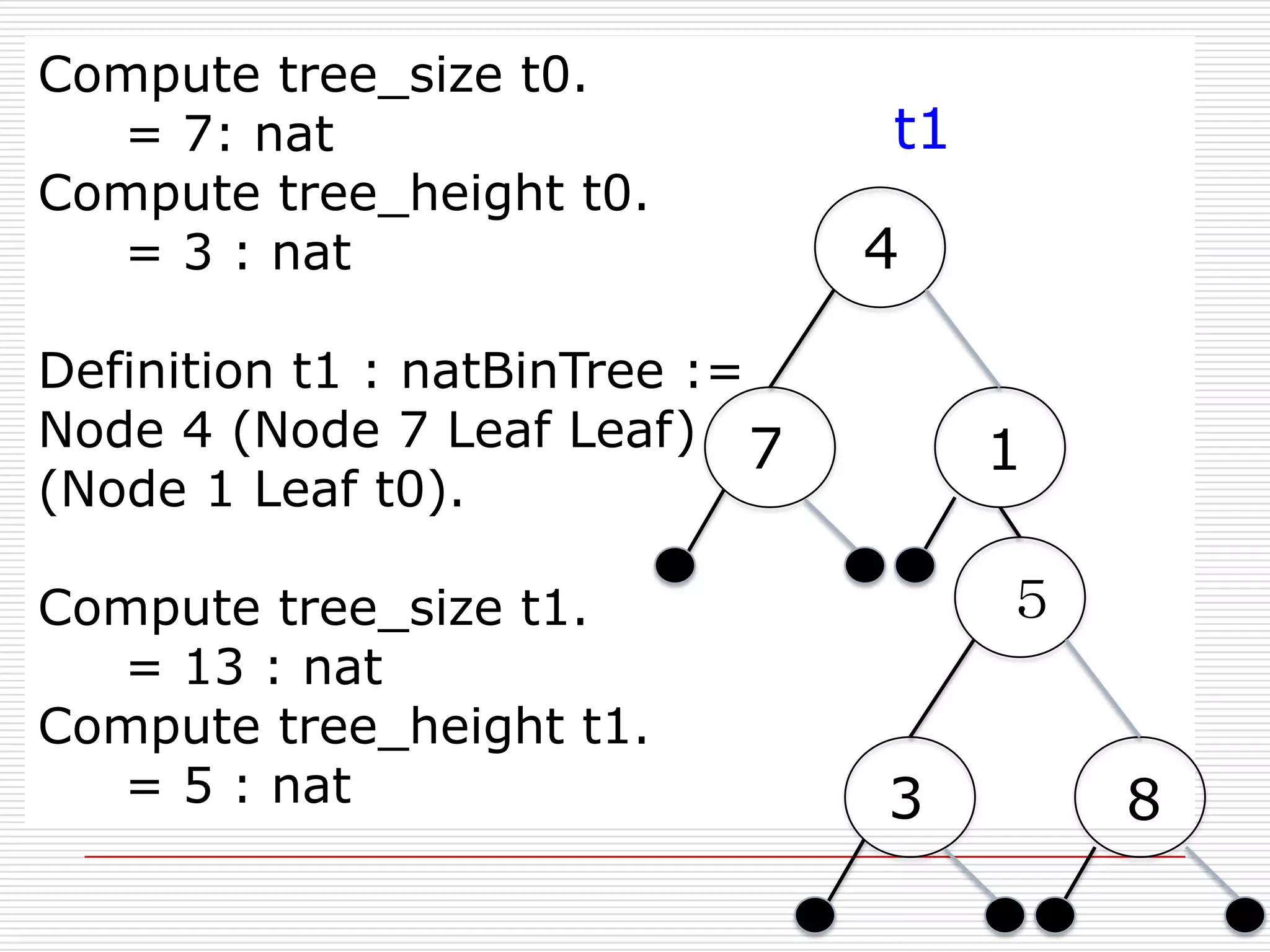
- 218. Compute tree_size t0.
= 7: nat
Compute tree_height t0.
= 3 : nat
t1
4
Definition t1 : natBinTree :=
Node 4 (Node 7 Leaf Leaf) 7
(Node 1 Leaf t0).
Compute tree_size t1.
= 13 : nat
Compute tree_height t1.
= 5 : nat
1
5
3
8
- 219. Require Import List.
Fixpoint labels (t: natBinTree) : list nat :=
match t with
| Leaf => nil
| Node n t1 t2 => labels t1 ++ (n :: labels t2)
end.
Compute labels (Node 9 t0 t0).
= 3 :: 5 :: 8 :: 9 :: 3 :: 5 :: 8 :: nil
: list nat
9
5
3
5
8
3
8
- 221. Coq < Lemma tree_decompose : forall t, tree_size t <> 1 ->
exists n:nat, exists t1:natBinTree,
exists t2:natBinTree,
t = Node n t1 t2.
============================
forall t : natBinTree,
tree_size t <> 1 ->
exists (n : nat) (t1 t2 : natBinTree), t = Node n t1 t2
tree_decompose < Proof.
tree_decompose < intros t H.
1 subgoal
t : natBinTree
H : tree_size t <> 1
============================
exists (n : nat) (t1 t2 : natBinTree), t = Node n t1 t2
tree_decompose < destruct t as [ | i t1 t2]
- 222. 2 subgoals
H : tree_size Leaf <> 1
============================
exists (n : nat) (t1 t2 : natBinTree), Leaf = Node n t1 t2
subgoal 2 is:
exists (n : nat) (t3 t4 : natBinTree), Node i t1 t2 = Node n t3 t4
tree_decompose < destruct H.
2 subgoals
============================
tree_size Leaf = 1
subgoal 2 is:
exists (n : nat) (t3 t4 : natBinTree), Node i t1 t2 = Node n t3 t4
tree_decompose < reflexivity.
- 223. 1 subgoal
i : nat
t1 : natBinTree
t2 : natBinTree
H : tree_size (Node i t1 t2) <> 1
============================
exists (n : nat) (t3 t4 : natBinTree), Node i t1 t2 = Node n t3 t4
tree_decompose < exists i.
1 subgoal
i : nat
t1 : natBinTree
t2 : natBinTree
H : tree_size (Node i t1 t2) <> 1
============================
exists t3 t4 : natBinTree, Node i t1 t2 = Node i t3 t4
tree_decompose < exists t1.
- 224. 1 subgoal
i : nat
t1 : natBinTree
t2 : natBinTree
H : tree_size (Node i t1 t2) <> 1
============================
exists t3 : natBinTree, Node i t1 t2 = Node i t1 t3
tree_decompose < exists t2.
1 subgoal
i : nat
t1 : natBinTree
t2 : natBinTree
H : tree_size (Node i t1 t2) <> 1
============================
Node i t1 t2 = Node i t1 t2
tree_decompose < reflexivity.
No more subgoals.
- 225. tree_decompose < Qed.
intros t H.
destruct t as [| i t1 t2].
destruct H.
reflexivity.
exists i.
exists t1.
exists t2.
reflexivity.
tree_decompose is defined
Coq <
- 227. Coq < Extraction Language Haskell.
Coq < Require Import List.
Coq < Print length.
length =
fun A : Type =>
fix length (l : Datatypes.list A) : nat :=
match l with
| Datatypes.nil => 0
| _ :: l' => S (length l')
end
: forall A : Type, Datatypes.list A -> nat
Argument A is implicit
Argument scopes are [type_scope list_scope]
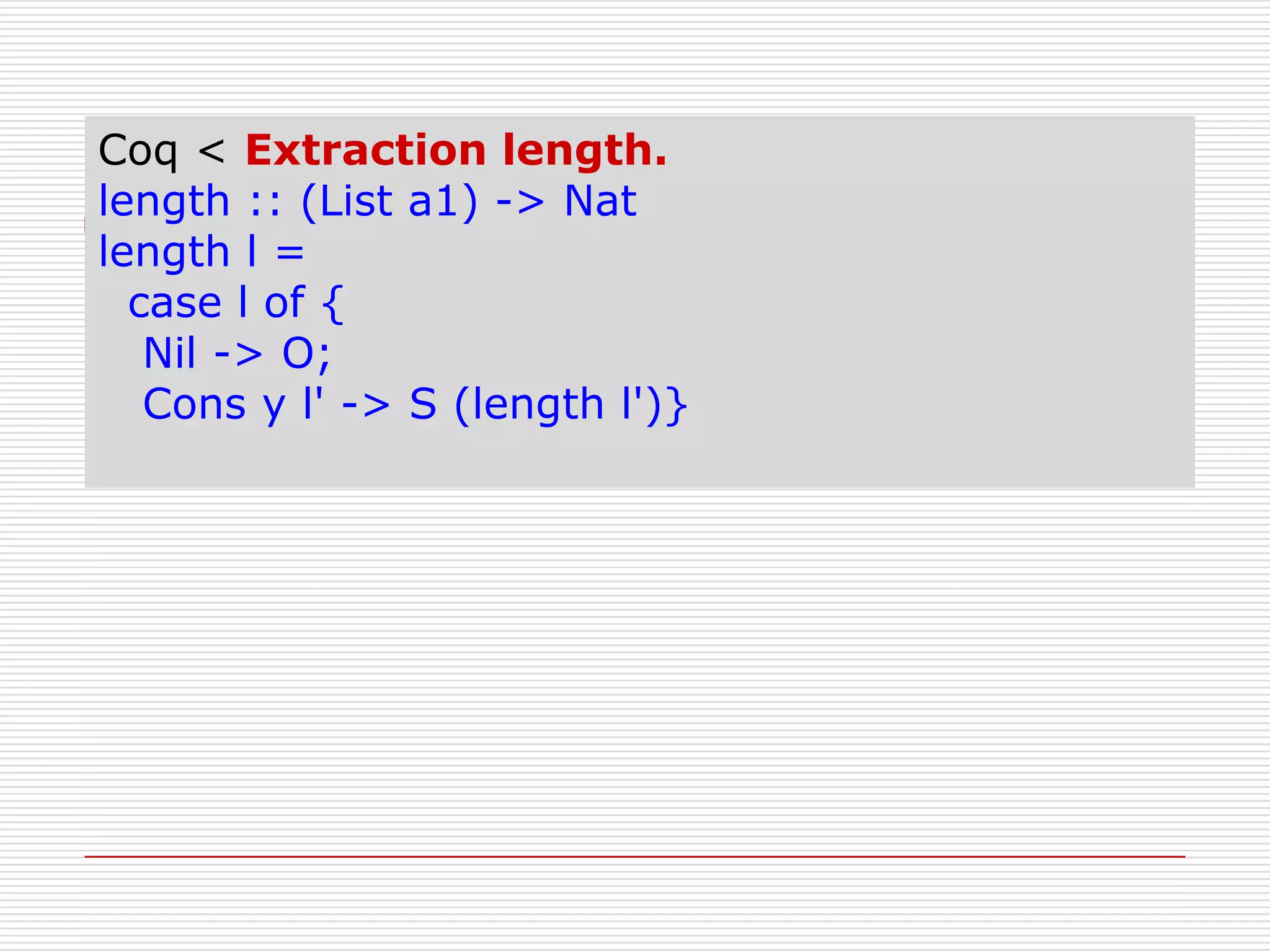
- 228. Coq < Extraction length.
length :: (List a1) -> Nat
length l =
case l of {
Nil -> O;
Cons y l' -> S (length l')}
- 229. Coq < Print app.
app =
fun A : Type =>
fix app (l m : Datatypes.list A) {struct l} :
Datatypes.list A :=
match l with
| Datatypes.nil => m
| a :: l1 => a :: app l1 m
end
: forall A : Type,
Datatypes.list A -> Datatypes.list A ->
Datatypes.list A
Argument A is implicit
Argument scopes are [type_scope list_scope
list_scope]
- 230. Coq < Extraction app.
app :: (List a1) -> (List a1) -> List a1
app l m =
case l of {
Nil -> m;
Cons a l1 -> Cons a (app l1 m)}
- 231. Coq < Extraction Language Ocaml.
Coq < Extraction length.
(** val length : 'a1 list -> nat **)
let rec length = function
| Nil -> O
| Cons (y, l') -> S (length l')
Coq < Extraction app.
(** val app : 'a1 list -> 'a1 list -> 'a1 list **)
let rec app l m =
match l with
| Nil -> m
| Cons (a, l1) -> Cons (a, (app l1 m))
- 232. Coq < Extraction Language Scheme.
Coq < Extraction length.
(define length (lambda (l)
(match l
((Nil) `(O))
((Cons y l~) `(S ,(length l~))))))
Coq < Extraction app.
(define app (lambdas (l m)
(match l
((Nil) m)
((Cons a l1) `(Cons ,a ,(@ app l1 m))))))
- 234. 証明の関数としての表現
Coq < Print S1.
S1 =
fun (A B : Prop) (H : A) (H0 : A -> B) => H0 H
: forall A B : Prop, A -> (A -> B) -> B
Argument scopes are [type_scope type_scope _ _]
Coq < Print S2.
S2 =
fun (P Q : Prop) (H : forall P0 : Prop, (P0 -> Q) -> Q)
(H0 : (P -> Q) -> P) =>
H0 (fun _ : P => H (P -> Q) (H P))
: forall P Q : Prop,
(forall P0 : Prop, (P0 -> Q) -> Q) -> ((P -> Q) -> P) -> P
Argument scopes are [type_scope type_scope _ _]
- 235. Coq < Print S3.
S3 =
fun (P Q R : Prop) (H : (P / Q) / ~ Q) (H0 : R) =>
conj H0
match H with
| conj (or_introl H3) _ => H3
| conj (or_intror H3) H2 =>
False_ind P
((fun H4 : Q =>
(fun H5 : ~ Q => (fun (H6 : ~ Q) (H7 : Q) =>
H6 H7) H5) H2 H4) H3)
end
: forall P Q R : Prop, (P / Q) / ~ Q -> R -> R / P
Argument scopes are [type_scope type_scope type_scope _ _]
- 236. Coq < Print lemma1.
lemma1 =
fun n : nat =>
nat_ind (fun n0 : nat => 0 * n0 = 0) eq_refl
(fun (n0 : nat) (_ : 0 * n0 = 0) => eq_refl) n
: forall n : nat, 0 * n = 0
Coq < Print lemma2.
lemma2 =
fun n : nat =>
nat_ind (fun n0 : nat => n0 * 0 = 0) eq_refl
(fun (n0 : nat) (IHn : n0 * 0 = 0) => IHn) n
: forall n : nat, n * 0 = 0
Argument scope is [nat_scope]
- 237. Coq < Print lemma3.
lemma3 =
fun n m : nat => plus_comm m (n * m)
: forall n m : nat, S n * m = n * m + m
Argument scopes are [nat_scope nat_scope]
Coq < Print lemma4.
lemma4 =
fun n m : nat => eq_sym (mult_n_Sm m n)
: forall n m : nat, m * S n = m * n + m
- 238. Coq < Print mult_n_Sm.
mult_n_Sm =
fun n m : nat =>
nat_ind (fun n0 : nat => n0 * m + n0 = n0 * S m) eq_refl
(fun (p : nat) (H : p * m + p = p * S m) =>
let n0 := p * S m in
match H in (_ = y) return (m + p * m + S p = S (m + y)) with
| eq_refl =>
eq_ind (S (m + p * m + p)) (fun n1 : nat => n1 = S (m + (p * m + p)))
(eq_S (m + p * m + p) (m + (p * m + p))
(nat_ind (fun n1 : nat => n1 + p * m + p = n1 + (p * m + p))
eq_refl
(fun (n1 : nat) (H0 : n1 + p * m + p = n1 + (p * m + p)) =>
f_equal S H0) m)) (m + p * m + S p)
(plus_n_Sm (m + p * m) p)
end) n
: forall n m : nat, n * m + n = n * S m
Argument scopes are [nat_scope nat_scope]



















![変数への値の代入
関数 f(x) が、x = aの時にとる値は、f(x)の
中に現れる x に、x = aの値を代入すること
で得ることが出来る。これは、通常、f(a)と
表わされる。
名前のないλ式 tでの変数 xへの値aの代入に
よる関数の値の計算を、次のように表現する
。
t [x:=a]
もっとも単純なλ式である、x自体が変数であ
る時、代入は次のようになる。
x [x:=a] = a](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-22-2048.jpg)
![適用と代入
もう尐し、適用と代入の関係を見ておこう。
λ式 λx.tへの、aの適用 (λx.t) aとは、代入
t[x:= a]を計算することである。
(λx.t) a = t[x:=a]
先の例での値の適用の直観的な説明は、代入
を用いると、次のように考えることが出来る
。
λx.t 2 = λx.(x2+y) 2
= (x2+y) [x:=2] = 22+y = 4+y
λy.t 1 = λy.(x2+y) 1
= (x2+y)[y:=1]=x2+1](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-23-2048.jpg)

![λ計算の形式的定義
次の三つのルールを利用して、λ式を(基本的に
は単純なものに)変換することをλ計算という。
1. α-conversion:
抽象化に用いる変数の名前は、自由に変更出来
る。例えば、
λx.(x2+1) => λy.(y2+1) => λz.(z2+1)
2. β-reduction:
代入による計算ルール (λx.t) a => t[x:=a]
3. η-conversion:
λx.(f x) => f
xで抽象化されたf(x)は、fに等しいということ](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-25-2048.jpg)
![β-reductionと代入ルール
実際のλ計算で、大きな役割を果たすのはβreductionである。その元になっている代入
ルールを尐し詳しく見ておこう。
1. x[x := N]
≡N
2. y[x := N]
≡ y, if x ≠ y
3. (M1 M2)[x := N] ≡ (M1[x := N]) (M2[x
:= N])
4. (λx.M)[x := N] ≡ λx.M
5. (λy.M)[x := N] ≡ λy.(M[x := N]), if x ≠
y, provided y ∉ FV(N)](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-26-2048.jpg)
![ちょっと変わったλ式 1
λ式 Ω := (λx.xx) (λx.xx) を考えよう。
これを計算してみる。
(λx.xx) (λx.xx)
= (λx.xx) (λy.yy)
= xx[x:=λy.yy]
= (λy.yy) (λy.yy)
= (λx.xx) (λx.xx)
となって、同じλ式が現れ、計算が終わらない
。](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-27-2048.jpg)
![ちょっと変わったλ式 2
Y := λg.(λx.g (x x)) (λx.g (x x))とする。
このとき、Y gを計算してみよう。
Yg
= λg.(λx.g (x x)) (λx.g (x x)) g
= λf.(λx.f (x x)) (λx.f (x x)) g
= (λx.g (x x)) (λx.g (x x))
= (λy.g (y y)) (λx.g (x x))
= g (y y)[y:=(λx.g (x x))]
= g ((λx.g (x x)) (λx.g (x x)))
=g(Yg)
すなわち、Y g = g ( Y g )となって、Y gは
、gの不動点を与える。](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-28-2048.jpg)




![型を持つラムダ計算での計算
あるオブジェクト aがある型 Aを持つとい
う判断を、 a : A と表わそう。
型を持つラムダ計算の理論では、計算は、
次の形をしている。
関数 λx:A.b[x] を、型Aに属するオブジ
ェクトaを適用して b[a]を得る。
計算の下で、全てのオブジェクトはユニー
クな値を持つ。また、計算で等しいオブジ
ェクトは、同一の値を持つ。](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-33-2048.jpg)










































![→ を含む命題の証明のルール
Aが命題であり、Bが命題であれば、A→Bは
命題になる。
xが命題Aの証明だと仮定して、eが命題Bの証
明だとしよう。この時、命題A→Bの証明は、
x:Aであるxの関数としてみたe、 (λx:A).eで
ある。
qが命題A→Bの証明で、aが命題Aの証明だと
すれば、関数qにaを適用した(q a)は、命題B
の証明である。
この時、((λx:A).e) a = e[a/x] (eの中
のxを全てaで置き換えたもの) になる。](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-79-2048.jpg)
![→ を含む命題の証明のルール
Formationルール
A は命題である
B は命題である
(→F)
(A→B) は命題である
Introductionルール
[x : A]
…
e:B
(→I)
(λx:A).e : (A→B)](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-80-2048.jpg)
![→ を含む命題の証明のルール
Eliminationルール
q : (A→B)
a:A
(→E)
(q a) : B
Computationルール
((λx:A).e) a → e[a/x]](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-81-2048.jpg)














![→ を含む要素の型のルール
Aが型であり、Bが型であれば、A→Bは型に
なる。
xが型Aの要素だと仮定して、eが型Bの要素だ
としよう。この時、型A→Bの要素は、x:Aで
あるxの関数としてみたe、 (λx:A).eである
。
qが型A→Bの要素で、aが型Aの要素だとすれ
ば、関数qにaを適用した(q a)は、型Bの要素
である。
この時、((λx:A).e) a = e[a/x] (eの中
のxを全てaで置き換えたもの) になる。](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-96-2048.jpg)
![→ を含む型のルール
Formationルール
A は型である
B は型である
(→F)
(A→B) は型である
Introductionルール
[x : A]
…
e:B
(→I)
(λx:A).e : (A→B)](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-97-2048.jpg)
![→ を含む型のルール
Eliminationルール
q : (A→B)
a:A
(→E)
(q a) : B
Computationルール
((λx:A).e) a → e[a/x]](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-98-2048.jpg)











![∀ を含む命題の証明のルール
Formationルール
[x : A]
…
Aは命題である
Pは命題である
(∀F)
(∀x:A).P は命題である
Introductionルール
[x : A]
…
p:P
(λx:A).p : (∀x:A) P
(∀I)](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-110-2048.jpg)
![∀ を含む命題の証明のルール
Eliminationルール
a:A
f : (∀x:A) P
f a : P[a/x]
Computationルール
((λx : A) . p) a = p[a/x]
(∀E)](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-111-2048.jpg)
![∃ を含む命題の証明のルール
Formationルール
[x : A]
…
Aは命題である
Pは命題である
(∃F)
(∃x:A).P は命題である
Introductionルール
a:A
p : P[a/x]
(a,p) : (∃x:A) .P
(∃I)](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-112-2048.jpg)





















































![tactic destruct
現在の仮定とゴールが次のような形をしてい
るとき、tactic destruct を用いる。
...
...
H1: A
destruct H
H: A∧B
H2: B
as [H1 H2]
...
...
--------------------C
C
対応する推論規則。](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-172-2048.jpg)


![destruct H as [H1 H2].
1 subgoal
P : Prop
Q destructとsplitのサンプル
: Prop
H1 : P
H2 : Q
-----------------------Q∧P
split.
2 subgoals
P : Prop
Q : Prop
H1 : P
H2 : Q
-----------------------Q
subgoal 2 is:
P](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-175-2048.jpg)
![tactic destruct
現在の仮定が A∨Bの形をしている時、tactic
destructは、二つのサブゴールを作る。
...
destruct H
A∨B
as [H1 H2]
...
------------C
対応する推論規則は。
...
H1: A
...
----------C
...
H2: B
...
----------C](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-177-2048.jpg)

![destruct H as [H0 | H0].
two subgoals
P : Prop
Q : Prop
H:P∨Q
H0 : P
-----------------------Q∨P
subgoal 2 is :
Q∨P
right; assumption.
left; assumption.
Qed.](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-179-2048.jpg)

































![Coq < Lemma tree_decompose : forall t, tree_size t <> 1 ->
exists n:nat, exists t1:natBinTree,
exists t2:natBinTree,
t = Node n t1 t2.
============================
forall t : natBinTree,
tree_size t <> 1 ->
exists (n : nat) (t1 t2 : natBinTree), t = Node n t1 t2
tree_decompose < Proof.
tree_decompose < intros t H.
1 subgoal
t : natBinTree
H : tree_size t <> 1
============================
exists (n : nat) (t1 t2 : natBinTree), t = Node n t1 t2
tree_decompose < destruct t as [ | i t1 t2]](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-221-2048.jpg)



![tree_decompose < Qed.
intros t H.
destruct t as [| i t1 t2].
destruct H.
reflexivity.
exists i.
exists t1.
exists t2.
reflexivity.
tree_decompose is defined
Coq <](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-225-2048.jpg)

![Coq < Extraction Language Haskell.
Coq < Require Import List.
Coq < Print length.
length =
fun A : Type =>
fix length (l : Datatypes.list A) : nat :=
match l with
| Datatypes.nil => 0
| _ :: l' => S (length l')
end
: forall A : Type, Datatypes.list A -> nat
Argument A is implicit
Argument scopes are [type_scope list_scope]](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-227-2048.jpg)
![Coq < Print app.
app =
fun A : Type =>
fix app (l m : Datatypes.list A) {struct l} :
Datatypes.list A :=
match l with
| Datatypes.nil => m
| a :: l1 => a :: app l1 m
end
: forall A : Type,
Datatypes.list A -> Datatypes.list A ->
Datatypes.list A
Argument A is implicit
Argument scopes are [type_scope list_scope
list_scope]](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-229-2048.jpg)




![証明の関数としての表現
Coq < Print S1.
S1 =
fun (A B : Prop) (H : A) (H0 : A -> B) => H0 H
: forall A B : Prop, A -> (A -> B) -> B
Argument scopes are [type_scope type_scope _ _]
Coq < Print S2.
S2 =
fun (P Q : Prop) (H : forall P0 : Prop, (P0 -> Q) -> Q)
(H0 : (P -> Q) -> P) =>
H0 (fun _ : P => H (P -> Q) (H P))
: forall P Q : Prop,
(forall P0 : Prop, (P0 -> Q) -> Q) -> ((P -> Q) -> P) -> P
Argument scopes are [type_scope type_scope _ _]](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-234-2048.jpg)
![Coq < Print S3.
S3 =
fun (P Q R : Prop) (H : (P / Q) / ~ Q) (H0 : R) =>
conj H0
match H with
| conj (or_introl H3) _ => H3
| conj (or_intror H3) H2 =>
False_ind P
((fun H4 : Q =>
(fun H5 : ~ Q => (fun (H6 : ~ Q) (H7 : Q) =>
H6 H7) H5) H2 H4) H3)
end
: forall P Q R : Prop, (P / Q) / ~ Q -> R -> R / P
Argument scopes are [type_scope type_scope type_scope _ _]](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-235-2048.jpg)
![Coq < Print lemma1.
lemma1 =
fun n : nat =>
nat_ind (fun n0 : nat => 0 * n0 = 0) eq_refl
(fun (n0 : nat) (_ : 0 * n0 = 0) => eq_refl) n
: forall n : nat, 0 * n = 0
Coq < Print lemma2.
lemma2 =
fun n : nat =>
nat_ind (fun n0 : nat => n0 * 0 = 0) eq_refl
(fun (n0 : nat) (IHn : n0 * 0 = 0) => IHn) n
: forall n : nat, n * 0 = 0
Argument scope is [nat_scope]](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-236-2048.jpg)
![Coq < Print lemma3.
lemma3 =
fun n m : nat => plus_comm m (n * m)
: forall n m : nat, S n * m = n * m + m
Argument scopes are [nat_scope nat_scope]
Coq < Print lemma4.
lemma4 =
fun n m : nat => eq_sym (mult_n_Sm m n)
: forall n m : nat, m * S n = m * n + m](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-237-2048.jpg)
![Coq < Print mult_n_Sm.
mult_n_Sm =
fun n m : nat =>
nat_ind (fun n0 : nat => n0 * m + n0 = n0 * S m) eq_refl
(fun (p : nat) (H : p * m + p = p * S m) =>
let n0 := p * S m in
match H in (_ = y) return (m + p * m + S p = S (m + y)) with
| eq_refl =>
eq_ind (S (m + p * m + p)) (fun n1 : nat => n1 = S (m + (p * m + p)))
(eq_S (m + p * m + p) (m + (p * m + p))
(nat_ind (fun n1 : nat => n1 + p * m + p = n1 + (p * m + p))
eq_refl
(fun (n1 : nat) (H0 : n1 + p * m + p = n1 + (p * m + p)) =>
f_equal S H0) m)) (m + p * m + S p)
(plus_n_Sm (m + p * m) p)
end) n
: forall n m : nat, n * m + n = n * S m
Argument scopes are [nat_scope nat_scope]](https://image.slidesharecdn.com/coq-140305210716-phpapp01/75/COQ-238-2048.jpg)