心理測量學

心理測量學(粵音:sam1 lei5 caak1 loeng4 hok6;英文:psychometrics),又叫心理統計學,係心理學一個子領域,專門研究點樣設計心理測驗以及心理測驗背後嘅理論:喺嚴格嘅心理學上,心理測驗係指攞嚟量度心理變數嘅架生,即係用嚟量度智能同性格嘅架生,冚唪唥都屬心理測量學嘅範疇[1][2];同一般坊間嗰啲心理測驗唔同嘅係,心理測量學上嘅心理測驗會俾心理學家用嚴謹嘅方法評定佢哋嘅信度同效度—評定完覺得掂,先會俾人採用[3][4]。
舉個簡化嘅例子,想像以下嘅研究:研究者想整一個心理測驗攞嚟做社科研究,呢個心理測驗要
心理測量學設計嘅架生相當有用:呢啲架生喺第啲心理學子領域上可以用嚟度想研究嘅變數[5],又有各種嘅應用價值,例如智商測驗喺教育上就可以用嚟評估一個學生應該要點教[6]。因為噉,心理測量學俾好多人認為係心理學嘅一個重要貢獻[1]。
基礎
[編輯]
心理測量學建基於兩點:
喺社科當中,量度[歐 1]可以定義為「按照某啲規則,將數值加落去物件或者事件之上」,用嚟描述件物件或者事件嘅某啲特性,即係例如物理學上一個溫度計會對每一個佢量度到嘅熱度俾一個相應嘅數值(溫度),心理測量上嘅量度(心理測驗)同一道理會用數值描述心理變數嘅每個可能數值,例如係用智商[歐 2]數值嚟描述一個個體嘅智能[7]。
量度層次[歐 3]係量度上嘅一個重要概念,意思係指量度可以分做四大層次[7][8]:
- 名目[歐 4],指一啲淨係俾到「類別」呢種資訊嘅量度方法,冇得比較大細,更加唔可以攞嚟做算術上嘅運算,例:語言(廣東話、普通話同英文等);
- 次序[歐 5],喺名目量度之上,冇得計加減,但有一定嘅順序或者大細,例:一場運動比賽之中選手嘅名次(第一、第二、第三等等);
- 等距[歐 6],喺次序量度之上,冇得計乘除,但量度到嘅數值有一個恆定嘅計量單位,即係話數值之間嘅差距可以比較大細(例如 0.5 同 0.6 之間嘅距離等同 0.6 同 0.7 之間嘅距離),所以可以計加減,例:攝氏溫度-「攝氏 100 度同 50 度之間嘅差距等如攝氏 50 同 0 度之間嘅差距」係一句有意義嘅嘢;同埋
- 等比[歐 7],喺等距量度之上,有一個特定嘅零值,做到乘除嘅運算,例:攝氏溫度就算個數值係 0 都唔等如「冇熱度」,相反「蘋果嘅數量」(假設研究者對蘋果呢隻詞有明確定義)就係一個等比量度,因為「0 個蘋果」真係表示冇蘋果,攝氏 100 度唔係真係攝氏 50 度兩倍咁熱-前者同絕對零度嘅差距並唔等如後者同絕對零度嘅差距嘅兩倍,而兩斤蘋果真係等如一斤蘋果嘅兩倍咁多咁重。
一般嚟講,研究者會想自己用嘅量度方法嘅層次有咁高(接近等比)得咁高[7]。
心理測量學嘅英文名 psychometrics 係 psycho- 同 metrics 嘅結合,前者源自古希臘文當中嘅 psykho-,意思係「心靈」或者「精神」噉解,而後者係指「用嚟做量度嘅系統」-所以心理測量學嘅英文名可以理解為「量度心靈同精神嘅特性」嘅學問,直譯就係心理測量學[9]。
重要概念
[編輯]古典測試理論
[編輯]古典測試理論[歐 8]係描述量度過程嘅一個基本理論:古典測試理論主張,每當一個研究者想
而根據古典測試理論,一個量度方法嘅信度[歐 12]()可以由以下嘅數值反映:
當中
可以睇埋將古典測試理論廣義化嘅項目反應理論[歐 14]-項目反應理論係一系列嘅數學模型,會好似古典測試理論噉,將心理測驗上嘅分數表達成心理測驗量度緊嘅嘢嘅函數,
- ,
當中函數 嘅款可以好複雜,解釋潛在特徵[歐 15]同實際觀察到嘅數據(心理測驗上嘅分數)之間嘅關係[12]。
因素分析
[編輯]
因素分析[歐 16]係一系列用嚟將大量變數轉化成少量因素[歐 17]嘅統計方法。因素分析有好多種做,不過做法一般都係由若干個直接觀察到嘅變數嗰度推想一個能夠解釋呢啲變數嘅變化嘅因素出嚟,而最後得出呢個因素能夠一定程度上反映嗰柞變數嘅變化[13]。舉個基於古典測試理論嘅例子說明:
- 想像家陣手上個數據庫有若干個被觀察咗[歐 18]嘅隨機變數 ,而呢柞變數嘅平均值係 。
- 想像有 個冇被觀察到[歐 19](數值冇直接被紀錄落去數據庫嗰度)嘅隨機變數 ,(呢柞 係所謂嘅因素)[註 1];
- 喺做因素分析前, 嘅數值係未知,而因素分析嘅目的就係要搵出以下呢啲式當中嘅參數:
因素分析喺心理測量學上極之常用:一個心理測驗會有若干條題目,而設計個測驗嘅人一般會嘗試用統計模型模擬個測驗嘅因素結構[歐 20];舉個例說明,而家有一個智商測驗,測驗有 50 條題目,當中頭 25 條題目量度邏輯能力,而尾嗰 25 條題目量度語言能力,即係話呢個測驗理論上有兩個因素-邏輯能力同語言能力;而頭嗰 25 條題目理論上應該會係邏輯能力()嘅函數而非語言能力()嘅函數-由量度邏輯能力嗰 25 條題目當中是但攞一條嘅分數 嚟睇,
- ,
而 ,當中 同 係數值有方法估計嘅系數[歐 21][15][16]。
卡隆巴系數
[編輯]卡隆巴系數[歐 22]()係心理測量學上成日用嚟衡量一個心理測驗嘅信度(睇下面)嘅數值。想像家陣有個心理測驗,有 咁多條題目,而呢 條題目冚唪唥都係量度緊一個因素(例如 10 條題目量度邏輯能力),研究者搵人做個測驗攞到數據之後,個測驗嘅卡隆巴系數()條式如下[17][18]:
如果卡隆巴系數數值大(接近 1)嘅話,就表示呢柞題目嘅變異數主要源自佢哋之間嘅協方差,簡單講就係表示「呢柞題目之間嘅變異數主要係由佢哋之間嘅相關引起嘅」而唔係源於佢哋各自獨立嘅變異-所以如果一柞題目嘅卡隆巴系數數值大,研究者就更有理由相信呢柞題目係量度緊同一個隱藏因素[17]。喺實際應用上,一般數值超過 0.65 嘅卡隆巴系數算係「可以當呢柞變數係量度同一個隱藏因素」,而高過 0.8 嘅就會當係量度同一個隱藏因素[17]。有關變異數同相關等嘅概念,可以睇吓基本嘅統計學。
舉個簡單例子,家陣有個心理測驗得四條題目,、、 同 ,四條題目都預佢哋量度緊同一個因素,而附表 1 係攞咗數據之後得到嘅協方差矩陣[歐 24]-協方差矩陣係一種數據表達方法,用一個矩陣表達每對變數之間嘅協方差,例如附表 1 嗰個矩陣就顯示 同 之間嘅協方差係 ,而對角線當中嘅係每個變數嘅變異數,例如附表就顯示 嘅變異數係 。用附表 1 嗰個矩陣嘅數據計嘅話,呢個四條題目嘅心理測驗嘅卡隆巴系數係:
適合度
[編輯]適合度[歐 25]喺統計學上係指一個統計模型有幾合乎觀察到嘅數據:用返頭先嗰個 50 條題目兩個因素嘅智商測驗嚟做例子,喺設計好啲題目之後,個設計者就要收數據(搵受試者做個測驗),收完做因素分析,睇吓啲受試者喺個測驗上嘅得分係咪真係好似佢預想嘅噉,望落似係由兩個隱藏因素話事-要睇吓「個測驗有兩個因素,當中頭嗰 25 條題目反映第一個因素,尾嗰 25 條題目反映第二個因素」呢一個統計模型嘅適合度如何[19]。
適合度指標[歐 26]就係指一啲用嚟衡量一個統計模型嘅適合度嘅指標數值;廿一世紀嘅統計學界有好多種適合度指標,而用統計技術做研究嘅人會按照自己嘅情況選擇用乜嘢指標衡量手上嘅統計模型[20]。
心理測驗
[編輯]
設計流程
[編輯]設計一個心理測驗[歐 27]嘅基本步驟如下[21][22]:
- 定義要量度啲咩建構[歐 28]:一個建構會包含指一拃頗此之間相關嘅行為,例如「答啱數學問題」同「答啱語言問題」都係智能嘅體現。
- 諗吓呢個建構可以點樣量度:一般心理學同社科上都會係俾一拃題目受試者答,啲題目可以來自前人整嘅心理測驗,或者係來自面試研究。研究者亦有可能會搵啲專家返嚟評吓啲題目,例如有個心理測驗想要管理上用嚟量度啲員工嘅諗法,可能會請啲真係有管理經驗嘅管理者返嚟評題目[23]。呢個階段會評個測驗嘅內容效度同表面效度(下面),亦會攞走或者改吓啲引起受試者誤解嘅題目[24]。
- 實際攞數據:搵班受試者返嚟,要佢哋答個測驗嘅問題[註 3][25];攞到數據之後就做因素分析同計卡隆巴系數(睇上面),睇吓受試者喺啲題目上嘅得分係咪真係好似預想中嘅因素結構;例如整一個智商測試量度智能,攞完數據之後做因素分析,睇吓啲得分係咪真係成預想中「測試邏輯能力嘅題目分數成一個因素、測試語言能力嘅題目分數成一個因素...」噉嘅因素結構。
- 按照呢啲統計分析嘅結果,執靚個測驗佢,如果有某條題目唔靚—例如統計分析發現佢因素負荷量等嘅指標唔掂[註 4][26]。噉就將條題目由個測驗嗰度攞走。
- 研究者亦有可能要度吓啲因素要改咩名好[27]。
- 用其他方法評估個測驗嘅信度同效度(下面),尤其係聚合效度同效標效度。
- 如果個測驗達標—卡隆巴系數夠靚,而且過到嗮其他信度同效度測試... 等等,噉就攞去發表。
評估方法
[編輯]廿一世紀心理測量學嘅兩個重要概念係信度同效度:信度同效度係兩種用嚟衡量一種量度方法掂唔掂嘅基準;喺設計一個心理測驗嗰陣,研究者實要用各種方法評估個測驗嘅信度同效度-心理測量學者做嘅研究基本上多數都係噉,用各種方法評估個心理測驗嘅信度同效度[1][28]。
信度
[編輯]信度[歐 29]指用一個量度方法對一個現象用嗰個方法進行重複觀察之後,係咪可以得到相同嘅數值;正路嚟講,如果一個量度方法係可信嘅,噉無論何時何地何人用嗰個方法量度同一樣嘢,都理應會得到相同嘅數值[2][3]。常用嘅信度指標有以下呢啲[29]:
- 評分者間信度[歐 30]:用嚟評估一個量度有幾受做量度嘅人影響;例如有一個俾教育家用嚟評估細路學習進度嘅方法,但做完研究發現,五位教育家分別噉用同一個方法評估同一班細路,五個得到完全唔同嘅數值,噉呢個量度方法嘅評分者間信度就低[30]。
- 重測試信度[歐 31]:用嚟評估一個量度方法有幾受時間影響;例如有一個俾心理學家用嚟量度智商嘅測驗,做研究,搵班受試者返嚟做個測驗,得到一柞分數 ,然後過咗一個月之後,搵返班受試者返嚟又做過,得到另一柞分數 ;一般認為智商冇乜可能會喺一個月之內改變嘅,如果 同 差異好大,就表示呢個測驗嘅重測試信度低。
- 內部一致度[歐 32]:指一個有多條題目嘅量度方法有幾「係量度緊同一樣嘢」;例如有一個智商測驗,有 50 條題目,理論上,呢啲題目冚唪唥都係量度緊智商,所以彼此之間理應喺得分上有返咁上下正相關,但研究發現,嗰 50 條題目當中有 5 條零舍係同其餘嗰啲題目有負相關,噉心理學家就好可能會要求攞走嗰 5 條題目(佢哋似乎唔係量度緊智商,所以唔應該擺喺一個智商測驗入面),變成一個 45 條題目嘅測驗。睇返卡隆巴系數。
等等。
效度
[編輯]效度[歐 33]指一個量度方法有幾量度到佢理應要量度嗰樣嘢;一個有效嘅量度方法真係量度緊研究者想佢量度嗰個變數;例如如果一個方法信度高、但效度低,就表示個量度方法能夠準確噉量度某個變數,但佢所量度嗰個變數並唔係研究者想佢量度嗰個[2][3]。常用嘅效度指標有以下呢啲:
- 建構效度[歐 34]:指一個概念嘅量度有幾合乎理論上嘅定義;例如理論上,智商測驗係量度智能嘅,而智能理論一般認為,智能包含一個個體解難嘅能力,所以一個智商測驗理應會考驗受試者嘅解難能力;建構效度嘅評估一般都係比較理論化嘅[31]。
- 效標效度[歐 35]:通常用嚟評估心理測驗嘅效度嘅一個指標,指個測驗嘅分數同俾人認為代表要量度嗰個變數有幾強相關;例如一個設計嚟量度一個人有幾外向嘅心理測驗,研究者搵咗班受試者返實驗室做個測驗,知道每位受試者嘅分數,然後喺實驗室入面觀察每位受試者有幾常主動同人講嘢或者互動(呢啲行為反映外向程度),再做一個相關嘅分析,睇吓測驗分數係咪真係同受試者做外向行為嘅次數有正相關。
- 分歧效度[歐 36]:指一個量度方法有幾「唔量度到理應唔啦更嘅變數」;例如一個智商測驗理應係量度緊智商,而唔係身高,如果一個一個智商測驗入面其中一條題目同個人嘅身高有正相關而且同身高嘅相關強過同其餘題目嘅相關,噉就似乎表示呢條題目量度身高多過量度智商,分歧效度低。
- 內容效度[歐 37]:指一個量度方法有幾能夠涵蓋嗮佢要量度嗰樣嘢嘅各個方面;例如智能一般包括邏輯同語言等多種嘅認知能力,所以一個理想嘅智商測驗理應要量度嗮以上嘅各種認知能力。
- 聚合效度[歐 38]:指一個量度方法有冇同一啲理論上同佢有相關嘅嘢有預期中嘅相關;例如智能理論上會同時影響一個人嘅邏輯能力同語言能力,所以邏輯能力同語言能力理論上應該會有返咁上下正相關[32]。
- 表面效度[歐 39]:指一個量度方法就噉望落有幾合乎佢理應要量度嘅嘢,通常話「一個量度方法有表面效度」喺正式科研上唔會俾人接受[33]。
等等。
| 射箭比喻[34] | ||||||
|---|---|---|---|---|---|---|
|



智商測驗
[編輯]智商測驗[歐 40]係量度智能嘅心理測驗。喺嚴格嘅認知科學上,智能嘅定義有些少含糊,包括思考、對邏輯嘅運用、理解、自我意識、理性、計劃、創意同解難等等嘅認知功能都俾人認定係量度智能嘅重要指標。而喺最廣義上嚟講,智能可以定義為「一個智能體感知同推斷資訊、將呢啲資訊儲起同化為知識、並且運用知識適應環境嘅能力」[35][36]。廿世紀同廿一世紀初嘅智商測驗一般做法係,要求受試者答若干條考驗各種認知功能嘅題目,並且靠搵出受試者喺呢啲題目上嘅分數(智商),表示每一位受試者嘅智能有幾高[37][38]。
喺呢個數列入面嘅下一個數字應該係乜? 37, 34, 31, 28, // 一般嚟講,正確答案係 25,因為呢個數列係「每個數字係之前嗰個減 3」
因為一般認為「能夠搵出事物之間嘅法則」係智能嘅體現,所以「答啱呢條題目」嘅行為可以反映「智能」呢一個心理建構[39]。
實證嘅智商研究帶出咗一般智能因素[歐 41]嘅概念:研究表明,一個個體喺唔同認知作業上嘅表現有明顯嘅正相關-即係話喺某個認知功能上勁過平均嘅人,傾向(但唔一定)會喺第啲認知功能上都勁過平均,而喺某個認知功能上弱過平均嘅人,傾向(但唔一定)會喺第啲認知功能上都弱過平均;於是有心理學家提出,一個心靈會具有一個「一般智能因素」,呢個因素獨力主宰住一個認知系統喺認知能力上嘅普遍表現。而及後嘅心理測量研究發現,人與人之間嘅唔同認知能力差異平均大約有成 40 至 50% 嘅都係源自一般智能因素上嘅差異嘅。呢柞研究確立咗個諗法-人心靈當中的確有某個因素單獨反映個人「有幾聰明」嘅[40][41]。
|
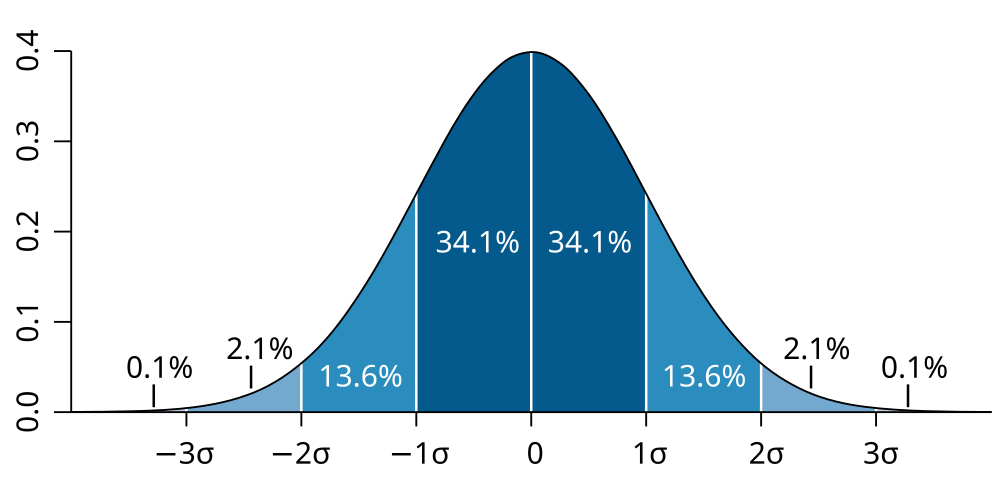
智商嘅概念仲同鐘形曲線[歐 42]息息相關。鐘形曲線係統計學上常用嘅一個概念,指一條反映常態分佈[歐 43]嘅曲線:是但攞一個變數 嚟睇,如果話 係跟常態分佈,意思係話出現得最頻密嘅 數值會係個平均數(),而離平均數愈遠嘅數值就愈少會出現;常見可以用常態分佈模擬嘅變數有人嘅智商-多數人嘅智商數值都傾向於平均數(100),而愈極端嘅數值(極高或者極低)就愈少出現。而如果將一個常態分佈畫做圖,當中 X 軸表示 嘅每個可能數值,而 Y 軸表示嗰個數值嘅出現頻率,就會形成一條鐘噉形嘅線[42]。
性格測驗
[編輯]
性格測驗[歐 44]係指量度性格嘅心理測驗。喺嚴格心理學上,性格係指一個個體特有(即係同第啲個體唔同)嘅行為、情緒或者認知特性:想像一個人,佢可以想像成一個會由刺激俾反應嘅系統,而人係有個體差異嘅生物物種;就算接收嘅刺激完全一樣,唔同人都可能會有唔同反應[43][44],例如外向度高嘅人喺見到新朋友(刺激)嗰陣,比較有可能會作出「主動行埋去結識」嘅反應,而外向度低嘅人喺同一個情況下會「主動行埋去結識」嘅機會就比較低[45]。
廿世紀性格測驗嘅常見做法係用李卡特量表[歐 45],指每一條題目都係一句句子,而受試者要做嘅係睇每條題目,用數字答自己有幾同意嗰句句子講嘅嘢[46]。例如量度一個人有幾性格衝動嘅李卡特量表,會有以下噉嘅題目:
我做親決定,都唔會點諗長遠後果。 我唔多在意幾年後先會發生嘅事。 如果有一樣嘢做咗會好爽但有長遠後果,我都會照樣去做。 ...
每一條題目受試者都係要填返一個 1 至 5 嘅數字,當中 1 分表示好唔同意嗰句句子,5 分表示好同意,3 分表示中立。
假設多數受試者都係願意同有能力俾準確資訊嘅話,呢個性格測驗上嘅分數理應會一定程度上噉反映[註 5]一個人幾容易驚。呢類性格測驗雖然話唔係完全靠得住,但經已相當有用-例如有個能夠「多數時候都準確噉量度」到外向度嘅問卷,而研究又發現外向度喺某啲情況下能夠預測一個員工嘅工作表現,噉呢個問卷就會喺管理上就有可能可以攞嚟幫手度請員工上嘅考量[47]。
唔靠自我報告
[編輯]廿世紀嘅心理測量學好依賴受試者答問題:廿世紀嘅智商測驗同性格測驗都需要俾人量度佢心理特性嗰個人答研究者問嘅問題,而研究者會用受試者喺呢啲問題上嘅得分評估佢;呢種方法被指有漏洞-要受試者答問題係假設咗(例如)受試者願意同有能力同研究者合作,呢個假設喺一般情況下能夠大致成立,但如果研究者想研究嘅係(例如)人嘅反社會行為(指傷害其他人或者忽視其他人利益嘅行為),研究者就有理由相信受試者會因為唔想俾人知佢哋做嘅衰嘢而唔老實作答[48]。因為呢啲噉嘅原因,廿一世紀嘅心理測量學界開始多咗嘗試用唔使靠受試者作答嘅方法做心理測量[49],例子可以睇運算心理測量[歐 46]呢種會用大數據技術嚟量度受試者性格嘅心理測量技術[25]。
喺廿一世紀嘅心理學上,心理測量可以靠量度受試者對強化同懲罰嘅反應嚟做。例如係廿一世紀初常用嚟量度一個人有幾衝動嘅埃奧華賭錢遊戲[歐 47]噉:喺呢個遊戲最基礎嗰個諗頭當中,受試者會俾研究者要求佢哋睇住四疊咭牌,每一張咭牌都會獎或者罰若干量嘅虛擬錢,而四疊咭牌各有唔同嘅獎罰機會;每位受試者有若干次機會去由四疊咭牌當中揀一疊,再由嗰疊咭嗰度抽一張,佢哋嘅目標係要盡可能賺最多嘅虛擬錢;研究發現,一般嘅受試者抽咗 40 至 50 次之後就會識得淨係由獎勵機率高嘅咭疊嗰度抽,不過杏仁核[歐 48](主管情緒嘅一個腦區)有病變嘅人似乎會唔識喺抽到「罰」嘅咭嗰陣驚,搞到佢哋唔能夠學識「唔好由懲罰機率高嘅咭疊度抽」呢點[50][51]-量度受試者嘅一樣外顯行為(抽咭)能夠得到資訊得知佢哋嘅心理特性(杏仁核功能)。
順帶一提,呢種行為「有幾能夠攞嚟做心理測量」就視乎呢種行為同嗰個心理特性之間有幾勁嘅統計相關。亦都可以睇埋相互資訊嘅概念[52]。
|

喺社科上,非自我報告測驗可以係靠受過訓嘅研究員做觀察。舉個簡單例子,想像一個教育心理學家,研究者想量度「學生喺課堂上花幾多時間做老師要佢哋做嘅作業」,佢可以首先定義好乜嘢係「做緊老師要佢哋做嘅作業」,然後請研究員幫手去課室實際觀察學生嘅行為,數住每個受觀察嘅學生「花幾多時間做老師要佢哋做嘅作業」-喺成個過程入面,研究者做到量度啲學生(受試者)嘅行為(心理特性),而且由始至終都冇要求啲學生答研究者嘅問題[53][54]。
非人心理測量
[編輯]
動物
[編輯]實證嘅研究表明咗,喺人以外嘅動物當中都有「同一物種嘅個體之間有個體差異」嘅現象,而呢啲個體差異都有可能會影響一隻動物嘅適應能力:想像而家擺五隻老鼠喺一個箱入面,然後研究員播放貓嘅叫聲俾佢哋聽;正常嘅老鼠會出現戰鬥定逃走反應[歐 51],但唔同嘅個體會有差異-有啲老鼠喺聽到貓叫聲會即刻走佬,有啲要喺貓叫聲大啲嗰陣先會走佬... 等等[55],因為噉,心理測量學界就有咗個諗頭,想將心理測量呢家嘢廣義化去人以外嘅動物嗰度[56]。
對動物認知[歐 52]嘅研究有思考點樣將智商測試廣義化去非人動物嗰度:比較心理學等嘅領域會有興趣比較唔同物種嘅行為,所以會想(例如)諗出一套可以喺任何動物物種身上使用嘅智能量度方法,用嚟比較唔同動物物種嘅智能;不過,人以外嘅動物唔會曉好似人噉答問題,所以呢類研究一般會採用行為量度嘅方法,使用操作制約[歐 53]嘅方法,睇吓動物喺有充足動機嘅情況下,能唔能夠學識解決複雜嘅問題,例如係擺隻動物喺一個實驗室入面,俾個掣同一盞燈佢哋,佢哋要喺每次盞燈著嗰陣都即刻撳個掣先會有嘢食(嘢食係動機),靠好似噉嘅方法評估動物嘅學習能力;如果用返一般智能因素嘅邏輯嚟思考嘅話,一隻動物喺唔同學習作業上嘅表現(以成功過關攞到嘢食嘅機會率量度)理應會有統計相關[57][58],而呢一個假說喺多個物種當中經已得到實證嘅研究支撐[59][60]。
機械
[編輯]人工智能[歐 54]泛指由機械所展示嘅智能,相對於人同第啲動物所展示嘅自然智能[歐 55]。人工智能相關嘅研究會嘗試教機械做推理、知識表示、計劃、學習、自然語言處理以及郁同操控物體等嘅作業,呢啲研究嘅其中一個終極目標係想創造出強人工智能[歐 56]-即係能夠展現出同人無異嘅智能嘅 AI [61]。有廿一世紀初嘅人工智能領域嘅科學家提出咗通用心理測量[歐 57]嘅諗頭,指可以用嚟量度任何智能體(包括人嘅心靈同人工智能等)嘅認知特性嘅測量方法[62]。
以下嘅概念都被指可以攞嚟做通用心理測量嘅指標:
- 圖靈測試[歐 58]:即係攞個人工智能同一個人類受試者,再加一個人類評判,睇吓評判喺睇唔到兩個受試者嘅情況下,能唔能夠用對答嘅型式分辨邊一個係人邊一個係人工智能。一般認為,如果一個人工智能做到以假亂真,就算係達到同人類智能無異。原則上,圖靈測試可以攞嚟比較兩個人或者兩隻動物都得[63]。
- 強化學習[歐 59]:即係要個人工智能程式係噉同佢周圍嘅環境互動(個環境可以係現場,又可以係一個模擬嘅環境)-喺每個時間點 ,程式會產生一個用數字表示嘅動作(例如 0 代表企喺度唔郁同 1 代表向前行呀噉),而跟住佢周圍個環境會俾 feedback-簡單講就係話返俾個程式聽,佢個動作啱唔啱(例如個地下有個窿,向前行會跌得好痛)。而個程式跟手會用機械學習演算法改變自己嘅行為[64]。原則上,「攞個受試者喺一個環境入面,睇吓佢點樣學識適應個環境」喺人同第啲動物身上都可以做[62]。
- 複雜度嘅預測:例如擺一隻動物喺一個實驗室入面,有 個掣俾佢撳,而呢 個掣會首先以一啲特定規律閃,閃完之後隻動物要撳「按嗰個規律,下一個會閃嘅掣」先可以有嘢食-例:想像
L表示左邊嗰個掣,R表示右邊嗰個掣,如果家陣啲掣以LRLRLRLR(左掣閃完到右掣閃,重複)嘅規律閃,下一個閃嘅掣應該會係左掣,而如果家陣啲掣以LLRLLRLL(左掣閃兩吓到右掣閃一吓,重複)嘅規律閃,下個閃嘅掣應該會係右掣... 如此類推;喺呢種實驗入面,隻動物需要了解啲掣閃嘅規律同埋預測下一個會閃嘅掣係乜;掣閃規律嘅複雜度可以由實驗者輕易噉控制同量化(可以睇吓演算法熵[歐 60]),而類似噉嘅測試喺人同人工智能身上都有可能做[65]。
等等。

歷史背景
[編輯]
心理測量學呢個領域背景源於 19 世紀嘅英國同德國[66]。
喺英國嘅心理測量學研究係受達爾文[歐 61]嘅研究啟發嘅。喺 1859 年,達爾文出版咗佢嗰本名作《物種起源》[歐 62],喺書入面提出物競天擇嘅概念,指出喺一個族群嘅生物當中會有個體差異,因為(例如)強壯啲或者聰明啲而比較擅長生存繁殖嘅個體會比較大機會能夠將自己身上(令擁有者強壯聰明)嘅基因傳俾下一代,於是個生物族群嘅基因庫(指個族群當中有嘅基因)就會一代代噉有變化-即係個族群會進化[67][68]。物競天擇呢個諗頭包含「同一個生物物種內部會有個體差異」而呢點刺激咗同達爾文同年代嘅心理學家法蘭西斯·高爾頓[歐 63](亦係達爾文嘅半表弟)嘅思考,令高爾頓開始諗人同人之間嘅個體差異,以及係呢啲差異要點量度[66]。
高爾頓佢做研究並且寫書分享佢嘅研究所得。佢指出,人與人之間喺智能同體能等方面有個體差異,而呢點令佢哋當中有啲比較適合生存同繁殖,而佢所研究嘅某啲變數,例如係反應時間,成為咗現代心理學研究上嘅重要工具;佢仲作出咗多項嘗試,想製作出能夠有效噉量度智能嘅架生-係現代智商測試嘅先驅,吸引咗第啲心理學家仿傚同幫手擴充佢嘅研究,而高爾頓亦都因而俾人稱為「心理測量學之父」[66][69]。
另一方面,心理物理學[歐 64]研究喺 19 世紀嘅德國進行得如火如荼。心理物理學係心理學嘅一個子領域,專門研究刺激嘅物理性質(例如係光嘅亮度同聲嘅頻率呀噉)會點樣影響呢啲刺激所造成嘅感受同體驗,例如一個心理物理學家會嘗試要佢嘅受試者聽幾個頻率唔同嘅聲,並且睇吓個受試者對呢幾個聲嘅體驗以及俾嘅反應有乜嘢唔同[70]。心理物理學上嘅研究引起咗「心理體驗係有可能客觀噉量度」嘅諗法,而且心理物理學上嘅理論仲有啟發心理測量方面嘅諗頭,例如有心理測量學研究者認為量度受試者對唔同物理特性嘅刺激嘅反應(心理物理學用嘅分析方法)可以幫手做心理測量[66]。
常用分析
[編輯]睇吓
[編輯]註釋
[編輯]歐詞
[編輯]- ↑ measurement
- ↑ IQ
- ↑ levels of measurement
- ↑ nominal
- ↑ ordinal
- ↑ interval
- ↑ ratio
- ↑ classical test theory
- ↑ true score
- ↑ error
- ↑ observed score
- ↑ reliability
- ↑ variance
- ↑ item response theory
- ↑ latent trait
- ↑ factor analysis
- ↑ factor,可以作粵拼:fek1 taa4
- ↑ observed
- ↑ latent
- ↑ factor structure
- ↑ coefficient
- ↑ Cronbach's alpha
- ↑ covariance
- ↑ covariance matrix
- ↑ goodness of fit / model fit
- ↑ fit indices
- ↑ psychological test
- ↑ construct
- ↑ reliability
- ↑ inter-rater reliability
- ↑ test-retest reliability
- ↑ internal consistency
- ↑ validity
- ↑ construct validity
- ↑ criterion validity
- ↑ discriminant validity
- ↑ content validity
- ↑ convergent validity
- ↑ face validity
- ↑ IQ test
- ↑ g-factor
- ↑ bell curve
- ↑ normal distribution
- ↑ personality test
- ↑ Likert scale
- ↑ computational psychometrics
- ↑ Iowa gambling task
- ↑ amygdala
- ↑ agent
- ↑ interpreter
- ↑ fight-or-flight response
- ↑ animal cognition
- ↑ operant conditioning
- ↑ artificial intelligence,AI
- ↑ natural intelligence
- ↑ strong AI
- ↑ universal psychometrics
- ↑ Turing test
- ↑ reinforcement learning
- ↑ algorithmic entropy
- ↑ Darwin
- ↑ On the Origin of Species
- ↑ Francis Galton
- ↑ psychophysics
引咗
[編輯]- ↑ 1.0 1.1 1.2 Furr, R. M. (2017). Psychometrics: an introduction. Sage Publications.
- ↑ 2.0 2.1 2.2 Carmines, E. G., & Zeller, R. A. (1979). Reliability and validity assessment (Vol. 17). Sage publications.
- ↑ 3.0 3.1 3.2 American Educational Research Association, Psychological Association, & National Council on Measurement in Education. (1999). Standards for Educational and Psychological Testing. Washington, DC: American Educational Research Association.
- ↑ Robert F. DeVellis (2016). Scale Development: Theory and Applications. SAGE Publications.
- ↑ Meier, S. T., & Davis, S. R. (1990). Trends in reporting psychometric properties of scales used in counseling psychology research. Journal of Counseling Psychology, 37(1), 113.
- ↑ Resnick, L. B. (1979). The future of IQ testing in education. Intelligence, 3(3), 241-253.
- ↑ 7.0 7.1 7.2 Stevens, S. S. (1946). On the theory of scales of measurement. Science, New Series, Vol. 103, No. 2684 (Jun. 7, 1946), pp. 677-680.
- ↑ Kirch, Wilhelm, ed. (2008). "Level of Measurement". Encyclopedia of Public Health. Springer. pp. 851–852.
- ↑ Psychometric 互聯網檔案館嘅歸檔,歸檔日期2020年10月25號,.. Online Etymology Dictionary.
- ↑ Novick, M.R. (1966). The axioms and principal results of classical test theory Journal of Mathematical Psychology Volume 3, Issue 1, February 1966, Pages 1-18
- ↑ Crocker, L., & Algina, J. (1986). Introduction to classical and modern test theory. Holt, Rinehart and Winston, 6277 Sea Harbor Drive, Orlando, FL 32887.
- ↑ Embretson, Susan E.; Reise, Steven P. (2000). Item Response Theory for Psychologists. Psychology Press.
- ↑ Thompson, B.R. (2004). Exploratory and Confirmatory Factor Analysis: Understanding Concepts and Applications. American Psychological Association.
- ↑ Child, Dennis (2006), The Essentials of Factor Analysis (3rd ed.), Continuum International.
- ↑ Mayes, S. D., Calhoun, S. L., Bixler, E. O., & Zimmerman, D. N. (2009). IQ and neuropsychological predictors of academic achievement. Learning and Individual Differences, 19(2), 238-241.
- ↑ Kline, P. (2014). An easy guide to factor analysis. Routledge.
- ↑ 17.0 17.1 17.2 Cho, E. (2016). Making reliability reliable: A systematic approach to reliability coefficients. Organizational Research Methods, 19(4), 651–682.
- ↑ Green, S. B., & Yang, Y. (2009). Commentary on coefficient alpha: A cautionary tale. Psychometrika, 74(1), 121-135.
- ↑ Singh, R. (2009). Does my structural model represent the real phenomenon?: a review of the appropriate use of Structural Equation Modelling (SEM) model fit indices. The Marketing Review, 9(3), 199-212.
- ↑ Singh, R. (2009). Does my structural model represent the real phenomenon?: a review of the appropriate use of Structural Equation Modelling (SEM) model fit indices. The Marketing Review, 9(3), 199-212.
- ↑ Churchill, G. A., Jr. (1979). A paradigm for developing better measures of marketing constructs (PDF). Journal of Marketing Research, 16, 64-73.
- ↑ Kumar, V., & Nayak, J. K. (2018). Destination personality: Scale development and validation. Journal of Hospitality & Tourism Research, 42(1), 3-25.
- ↑ Holt, D. T., Armenakis, A. A., Feild, H. S., & Harris, S. G. (2007). Readiness for organizational change: The systematic development of a scale. The Journal of applied behavioral science, 43(2), 232-255. "Step 1: Item Development"
- ↑ Ersche, K. D., Lim, T. V., Ward, L. H., Robbins, T. W., & Stochl, J. (2017). Creature of Habit: A self-report measure of habitual routines and automatic tendencies in everyday life. Personality and Individual Differences, 116, 73-85. "Items that were consistently misunderstood were either reworded or removed."
- ↑ 25.0 25.1 Boyd, R. L., Pasca, P., & Lanning, K. (2020). The personality panorama: Conceptualizing personality through big behavioural data (PDF). European Journal of Personality, 34(5), 599-612.
- ↑ Conway, J. M., & Huffcutt, A. I. (2003). A review and evaluation of exploratory factor analysis practices in organizational research. Organizational research methods, 6(2), 147-168.
- ↑ Holt, D. T., Armenakis, A. A., Feild, H. S., & Harris, S. G. (2007). Readiness for organizational change: The systematic development of a scale. The Journal of applied behavioral science, 43(2), 232-255. Step 3 "Thus, Factor 1 was labeled appropriateness.", "Factor 2, termed management support, contained..."
- ↑ Nunnally, J.C. (1978). Psychometric theory (2nd ed.). New York: McGraw-Hill.
- ↑ Hayes & Coutts (2020): "Reliability is defined as the proportion of the variance (V) in the observed scores O attributable to actual variance in T: V(T)/V(O)."
- ↑ McHugh, M. L. (2012). Interrater reliability: the kappa statistic. Biochemia medica: Biochemia medica, 22(3), 276-282.
- ↑ Cronbach, Lee J.; Meehl, Paul E. (1955). "Construct validity in psychological tests". Psychological Bulletin. 52 (4): 281–302.
- ↑ Campell, D. T., & Fiske, D. W. (1959). Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin, 56, 81-105
- ↑ Gravetter, Frederick J.; Forzano, Lori-Ann B. (2012). Research Methods for the Behavioral Sciences (4th ed.). Belmont, Calif.: Wadsworth. p. 78.
- ↑ Souza, A. C. D., Alexandre, N. M. C., & Guirardello, E. D. B. (2017). Psychometric properties in instruments evaluation of reliability and validity. Epidemiologia e Serviços de Saúde, 26, 649-659.
- ↑ Wechsler, D. (1944). The measurement of adult intelligence. Baltimore: Williams & Wilkins.
- ↑ Kanazawa, S. (2004). General intelligence as a domain-specific adaptation. Psychological review, 111(2), 512.
- ↑ 37.0 37.1 Daniel, M. H. (1997). Intelligence testing: Status and trends. American psychologist, 52(10), 1038.
- ↑ 38.0 38.1 Snyderman, M., & Rothman, S. (1987). Survey of expert opinion on intelligence and aptitude testing. American Psychologist, 42(2), 137.
- ↑ What Do IQ Tests Test?: Interview with Psychologist W. Joel Schneider. Scientific American.
- ↑ Sternberg, R. J., & Grigorenko, E. L. (Eds.). (2002). The general factor of intelligence: How general is it?. Psychology Press.
- ↑ Colom, R., Jung, R. E., & Haier, R. J. (2006). Distributed brain sites for the g-factor of intelligence. Neuroimage, 31(3), 1359-1365.
- ↑ Ash, Robert B. (2008). Basic probability theory (Dover ed.). Mineola, N.Y.: Dover Publications. pp. 66-69.
- ↑ Corr, Philip J.; Matthews, Gerald (2009). The Cambridge handbook of personality psychology (1. publ. ed.). Cambridge: Cambridge University Press.
- ↑ John, O. P., Robins, R. W., & Pervin, L. A. (Eds.). (2010). Handbook of personality: Theory and research. Guilford Press.
- ↑ Eysenck, H. J. (Ed.). (2012). A model for personality. Springer Science & Business Media.
- ↑ Likert, Rensis (1932). "A Technique for the Measurement of Attitudes". Archives of Psychology. 140: 1–55.
- ↑ Blickle, G., Meurs, J. A., Wihler, A., Ewen, C., Merkl, R., & Missfeld, T. (2015). Extraversion and job performance: How context relevance and bandwidth specificity create a non-linear, positive, and asymptotic relationship. Journal of vocational behavior, 87, 80-88.
- ↑ Bennett, R. J., & Robinson, S. L. (2000). Development of a measure of workplace deviance. Journal of Applied Psychology, 85, 349 –360.
- ↑ Bing, M. N., LeBreton, J. M., Davison, H. K., Migetz, D. Z., & James, L. R. (2007). Integrating implicit and explicit social cognitions for enhanced personality assessment: A general framework for choosing measurement and statistical methods. Organizational Research Methods, 10, 346 –389
- ↑ Bechara A., Damasio H., Tranel D., Damasio A.R. (1997). "Deciding advantageously before knowing the advantageous strategy". Science. 275 (5304): 1293–5.
- ↑ Bechara A., Damasio H., Tranel D., Damasio A.R. (2000). "Characterization of the decision-making deficit of patients with ventromedial prefrontal cortex lesions". Brain. 123 (11): 2189-2202.
- ↑ Schmitz, F., Kunina-Habenicht, O., Hildebrandt, A., Oberauer, K., & Wilhelm, O. (2020). Psychometrics of the Iowa and Berlin gambling tasks: Unresolved issues with reliability and validity for risk taking (PDF). Assessment, 27(2), 232-245.
- ↑ Hintze, J. M., & Matthews, W. J. (2004). The generalizability of systematic direct observations across time and setting: A preliminary investigation of the psychometrics of behavioral observation. School Psychology Review, 33(2), 258-270.
- ↑ Duff, P. A., & Van Lier, L. E. O. (1997). Approaches to Observation in Classroom Research; Observation From an Ecological Perspective. Tesol Quarterly, 31(4), 783-787.
- ↑ Smith, B. R., & Blumstein, D. T. (2008). Fitness consequences of personality: a meta-analysis. Behavioral Ecology, 19(2), 448-455.
- ↑ Shaw, R. C., & Schmelz, M. (2017). Cognitive test batteries in animal cognition research: evaluating the past, present and future of comparative psychometrics (PDF). Animal cognition, 20(6), 1003-1018.
- ↑ Boogert, N. J., Giraldeau, L. A., & Lefebvre, L. (2008). Song complexity correlates with learning ability in zebra finch males. Animal Behaviour, 76(5), 1735-1741.
- ↑ Locurto, C., Fortin, E., & Sullivan, R. (2003). The structure of individual differences in heterogeneous stock mice across problem types and motivational systems. Genes, Brain and Behavior, 2(1), 40-55.
- ↑ Galsworthy, M. J., Paya-Cano, J. L., Liu, L., Monleon, S., Gregoryan, G., Fernandes, C., ... & Plomin, R. (2005). Assessing reliability, heritability and general cognitive ability in a battery of cognitive tasks for laboratory mice. Behavior genetics, 35(5), 675-692.
- ↑ Amici, F., Barney, B., Johnson, V. E., Call, J., & Aureli, F. (2012). A modular mind? A test using individual data from seven primate species. PloS one, 7(12), e51918.
- ↑ Hutter, Marcus (2005). Universal Artificial Intelligence. Berlin: Springer.
- ↑ 62.0 62.1 Hernández-Orallo, J., Dowe, D. L., & Hernández-Lloreda, M. V. (2014). Universal psychometrics: Measuring cognitive abilities in the machine kingdom. Cognitive Systems Research, 27, 50-74.
- ↑ Saygin, A. P., Cicekli, I., & Akman, V. (2000). Turing test: 50 years later. Minds and machines, 10(4), 463-518.
- ↑ Dominic, S.; Das, R.; Whitley, D.; Anderson, C. (July 1991). "Genetic reinforcement learning for neural networks". IJCNN-91-Seattle International Joint Conference on Neural Networks. Seattle, Washington, USA: IEEE.
- ↑ Hernandez-Orallo, J. (2000). Beyond the Turing test (PDF). Journal of Logic, Language and Information, 9(4), 447-466.
- ↑ 66.0 66.1 66.2 66.3 Kaplan, R.M., & Saccuzzo, D.P. (2010). Psychological Testing: Principles, Applications, and Issues. (8th ed.). Belmont, CA: Wadsworth, Cengage Learning.
- ↑ Futuyma, Douglas J. Evolution. Sunderland, Massachusetts: Sinauer Associates, Inc. 2005.
- ↑ Kimura, Motoo. The neutral theory of molecular evolution: a review of recent evidence. The Japanese Journal of Human Genetics (Mishima, Japan: Genetics Society of Japan). 1991, 66 (4): 367–386.
- ↑ Cattell, J. M. (1928). Early psychological laboratories. Science, 67(1744), 543-548.
- ↑ Gescheider, G. (1997). Psychophysics: the fundamentals. Somatosensory & Motor Research. 14 (3rd ed.). pp. 181-188.
- ↑ Gignac, G. E., & Szodorai, E. T. (2016). Effect size guidelines for individual differences researchers (PDF). Personality and individual differences, 102, 74-78.
文獻
[編輯]一般文獻:
- Amerise, I. L., & Tarsitano, A. (2015). Correction methods for ties in rank correlations. Journal of Applied Statistics, 42(12), 2584-2596,呢篇文講到計等級相關嗰陣要點應付等級打和。
- Andrich, D. & Luo, G. (1993). "A hyperbolic cosine model for unfolding dichotomous single-stimulus responses" (PDF). Applied Psychological Measurement. 17 (3): 253–276. CiteSeerX 10.1.1.1003.8107.
- Churchill, G. A., Jr. (1979). A paradigm for developing better measures of marketing constructs (PDF). Journal of Marketing Research, 16, 64-73.
- Corr, P. J., & Cooper, A. J. (2016). The reinforcement sensitivity theory of personality questionnaire (RST-PQ): development and validation (PDF). Psychological assessment, 28(11), 1427.
- Borsboom, Denny (2005). Measuring the Mind: Conceptual Issues in Contemporary Psychometrics. Cambridge: Cambridge University Press. ISBN 978-0-521-84463-5. Lay summary (28 June 2010).
- Hayes, A. F., & Coutts, J. J. (2020). Use omega rather than Cronbach's alpha for estimating reliability. But…. Communication Methods and Measures, 14(1), 1-24,呢篇文喺度批評卡隆巴系數嘅不足之處。
- Holt, D. T., Armenakis, A. A., Feild, H. S., & Harris, S. G. (2007). Readiness for organizational change: The systematic development of a scale (PDF). The Journal of applied behavioral science, 43(2), 232-255,講到佢哋點整一個測驗,個測驗對於應變管理嚟講有用。
- Jones, L. V., & Thissen, D. (2007). A history and overview of psychometrics (PDF). Handbook of Statistics, Vol. 26.
- LeBreton, J. M., & Senter, J. L. (2008). Answers to 20 questions about interrater reliability and interrater agreement (PDF). Organizational research methods, 11(4), 815-852.
運算文獻:
- Polyak, S. T., von Davier, A. A., & Peterschmidt, K. (2017). Computational psychometrics for the measurement of collaborative problem solving skills. Frontiers in psychology, 8, 2029.
- Shute, V. J., Smith, G., Kuba, R., Dai, C. P., Rahimi, S., Liu, Z., & Almond, R. (2021). The design, development, and testing of learning supports for the Physics Playground game (PDF). International Journal of Artificial Intelligence in Education, 31(3), 357-379,呢篇文講解一隻可以攞嚟量度創意同某啲性格特質嘅物理模擬遊戲。
- Stachl, C., Boyd, R. L., Horstmann, K. T., Khambatta, P., Matz, S., & Harari, G. M. (2021). Computational Personality Assessment-An Overview and Perspective (PDF).
AI 文獻:
- Chmait, N., Dowe, D. L., Li, Y. F., & Green, D. G. (2017, August). An information-theoretic predictive model for the accuracy of AI agents adapted from psychometrics (PDF). In International Conference on Artificial General Intelligence (pp. 225-236). Springer, Cham.
- Hernandez-Orallo, J. (2000). Beyond the Turing test (PDF). Journal of Logic, Language and Information, 9(4), 447-466.
- Hernández-Orallo, J., Dowe, D. L., & Hernández-Lloreda, M. V. (2014). Universal psychometrics: Measuring cognitive abilities in the machine kingdom (PDF). Cognitive Systems Research, 27, 50-74.
拎
[編輯]- (香港繁體) 「超神準心理測驗」是怎麼做到「超神準」的?,亦可以睇睇可否證度呢個概念。
- (英文) 用嚟做教育同心理測驗嘅 APA 標準
- (英文) 心理測量學社群
- (英文) 倫敦心理測量實驗室
- (英文) 劍橋大學心理測量學中心
- (英文)IQ 測試量度緊啲乜?