【メタサーベイ】基盤モデル / Foundation Models
15 likes19,571 views
cvpaper.challenge の メタサーベイ発表スライドです。 cvpaper.challengeはコンピュータビジョン分野の今を映し、トレンドを創り出す挑戦です。論文サマリ作成・アイディア考案・議論・実装・論文投稿に取り組み、凡ゆる知識を共有します。 http://xpaperchallenge.org/cv/





![2022年現在,CVに波及する基盤モデルの衝撃
8
DALL•E2やFlamingoなど言語と視覚を繋ぐモデルが台頭
画像・動画・言語の複数モダリティを同時に処理
● 画像/動画と言語を別々に学習して統合
● 70Bパラメータの事前学習済みテキストエンコーダーと
CLIP方式で事前学習済み画像エンコーダーがベース
● ベースラインのわずか 1/1000程度のみのサンプル提示で
VQAなどの6/16のマルチモーダルタスクで SoTA達成.
追加学習を行うと更に 5つのベンチマークで SoTA達成.
自然言語から高精細な画像を生成
● CLIP : 画像・言語空間の対応関係を高度に学習
○ WEB上から収集した約4億組の画像・言語ペアにより学習
● DDPM : ノイズ付与/復元により高解像画像描画するモデル
● CLIPの画像埋め込み特徴を生成するように DDPM
を学習させ,多様性に富んだ Text-to-Imageのモデルを構築
● この結果,AIは創造性を持ったと総評されるに至る
次ページよりTransformer〜Foudation Models(FMs)に至るまでを解説↓
Flamingo [Alayac(DeepMind)+, arXiv22]
DALL•E 2 [Ramesh(OpenAI)+, arXiv22]
ロボットのような半顔を持つ
サルバドール・ダリの鮮やかな肖像画
ベレー帽と黒のタートルネック
を身に付けた柴犬
葉を茂らせた手掌のクローズアップ](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-8-2048.jpg)

![12
自然言語処理(NLP)分野でTransformerが誕生
● Transformer
● Self-Attention(自己注意)機構により
系列データを一括同時処理可能に
(従来のRNNでは逐次的に処理
→並列計算できず 処理に時間がかかる ,
離れた単語関係が見えず 長文理解は困難 )
○ GPUフレンドリーで
容易に並列計算による学習高速化可能
○ 入力シーケンス全体を考慮可能
● 劇的な学習時間短縮・性能向上を同時に実
現し,ブレイクスルーを引き起こした
(当時の翻訳タスクでSoTAを達成)
Transformerについてはこちらも参照
https://www.slideshare.net/cvpaperchallenge/transformer-247407256
[Vaswani(Google)+, NeurIPS17]
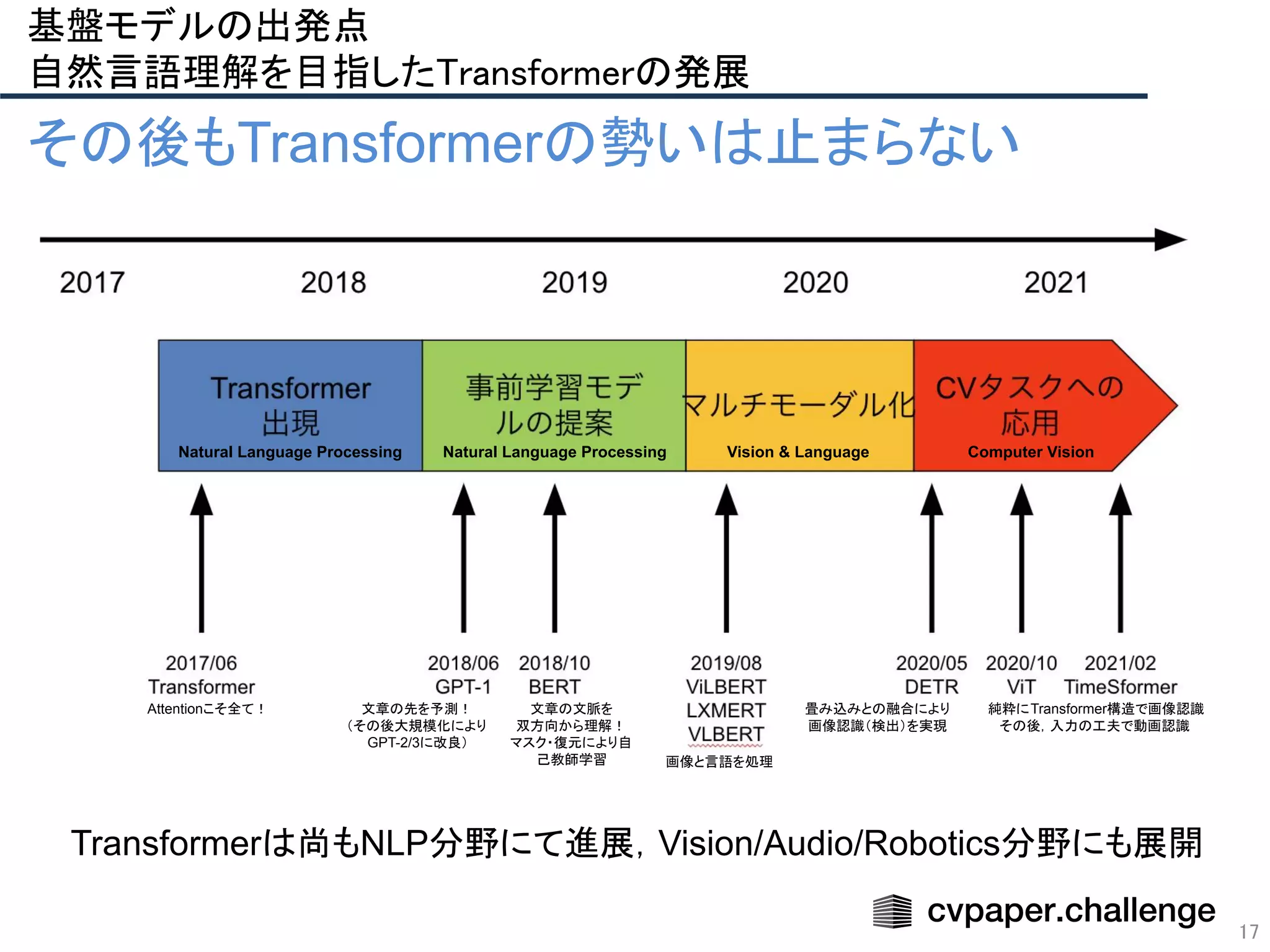
基盤モデルの出発点
自然言語理解を目指したTransformerの発展
急発達するHPCによるGPU/TPU並列計算技術と相性抜群.
近代のほぼ全ての大規模基盤モデルは,Transformerがベースに](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-12-2048.jpg)
![13
NLP分野にてTransformerが拡がる
● BERT(Bi-directional Encoder Representations from Transformers)
● 大量の汎用テキストデータで事前学習→タスクに合わせて追加学習
● 翻訳・予測などNLPのタスクを幅広く解くことができるモデル
● 文章の「意味を理解」することができるようになったと話題
● なぜBERTは躍進した?
● 自己教師学習によりラベルなし文章を学習に適用可能
● 双方向モデルにつき,単語の前後から文脈を把握
BERTでは多くのタスクを単一モデルで解くことができ
るが,その学習は「文章のマスクと復元」の自己教師
あり学習により実施される
Attention is All You Need.(元データ)
↓ 意図的に欠損作成
Attention is All ___ Need.(復元前)
↓ BERTにより推定
Attention is All You Need.(復元後)
[Devlin(Google)+, NAACL19]
基盤モデルの出発点
自然言語理解を目指したTransformerの発展](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-13-2048.jpg)
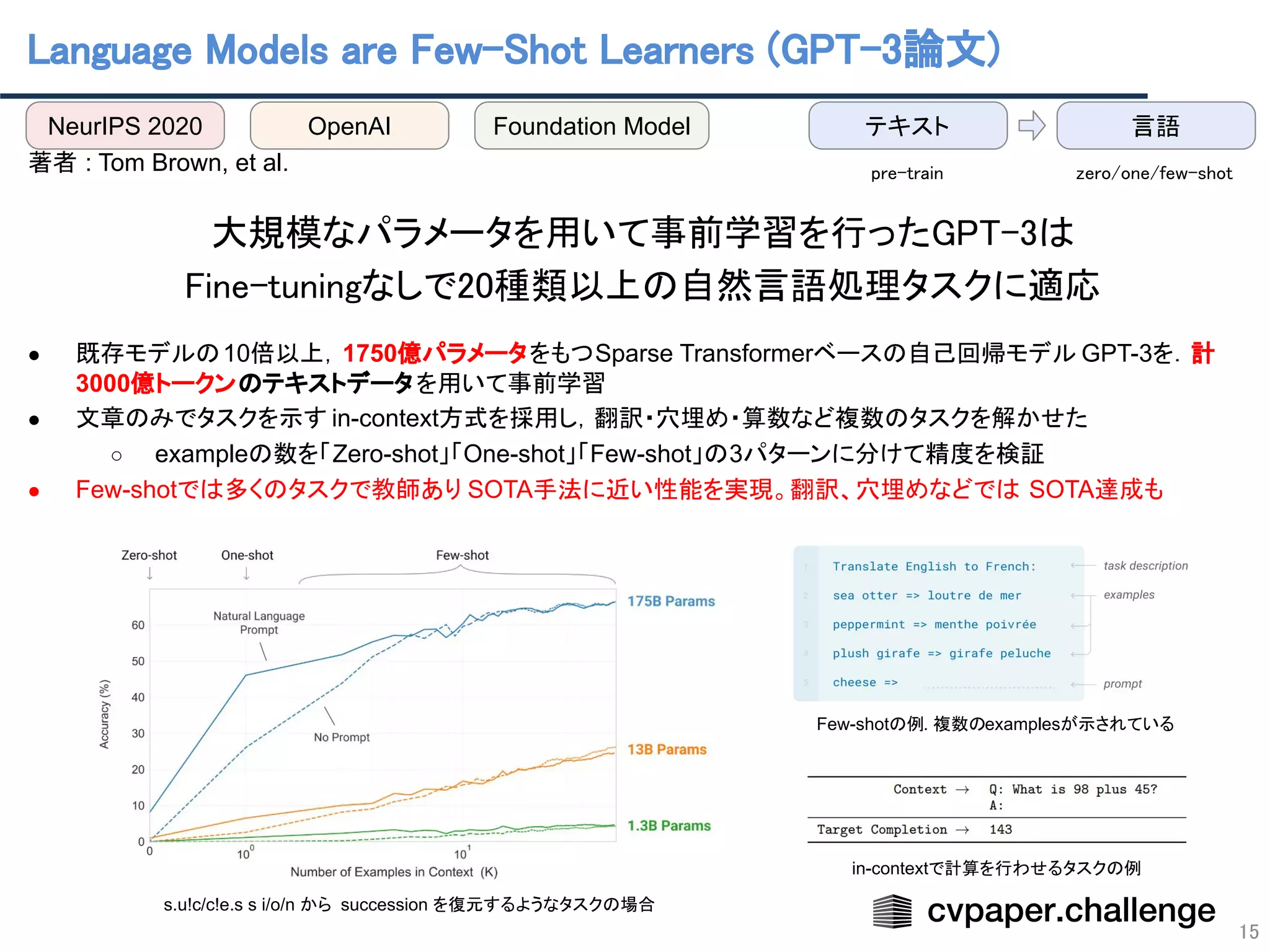
![GPT-3論文はNeurIPS 2020にて
Best Paper Awardを獲得
14
人間レベルの文章生成を可能に
● GPT(Generative Pre-trained Transformer)
● 与えられた文章の先を予測して文章生成
● 拡張される度にパラメータ数 / 学習テキストサイズが一気に増加
○ GPT : 1.2億パラメータ
○ GPT-2 : 15億パラメータ, 40GBテキスト
○ GPT-3 : 1750億パラメータ, 570GBテキスト(3000億トークン)
○ 爆発的なパラメータ数の増加により大幅な性能改善が見られた
● 「シンギュラリティが来た」と言われるほどに文章生成能力を獲得
https://neuripsconf.medium.com/announcing-the-neurips-2020-award-recipients-73e4d3101537
[Brown(OpenAI)+, NeurIPS20]
基盤モデルの出発点
自然言語理解を目指したTransformerの発展](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-14-2048.jpg)


![20
Vision Transformer(ViT)
● 純Transformer構造により画像認識
● 画像パッチを単語と見なして処理
● Encoderのみ使用 / MLPを通して出力
● 3億枚のラベル付き画像で事前学習
→CNNを超えたか?と話題に
● ViTの後にも亜種が登場
● CNN + Transformer: CvT, ConViT(擬似畳込み),
CMT, CoAtNet
● MLP: MLP-Mixer, gMLP(Attentionそのものではなく構造が重要?)
● ViT: DeiT, Swin Transformer
ViT [Dosovitskiy(Google)+, ICLR21]
【Swin Transformer V1/V2】
Swin Transformer V1 [Liu(Microsoft)+, ICCV21]
Swin Transformer V2 [Liu(Microsoft)+, CVPR22]
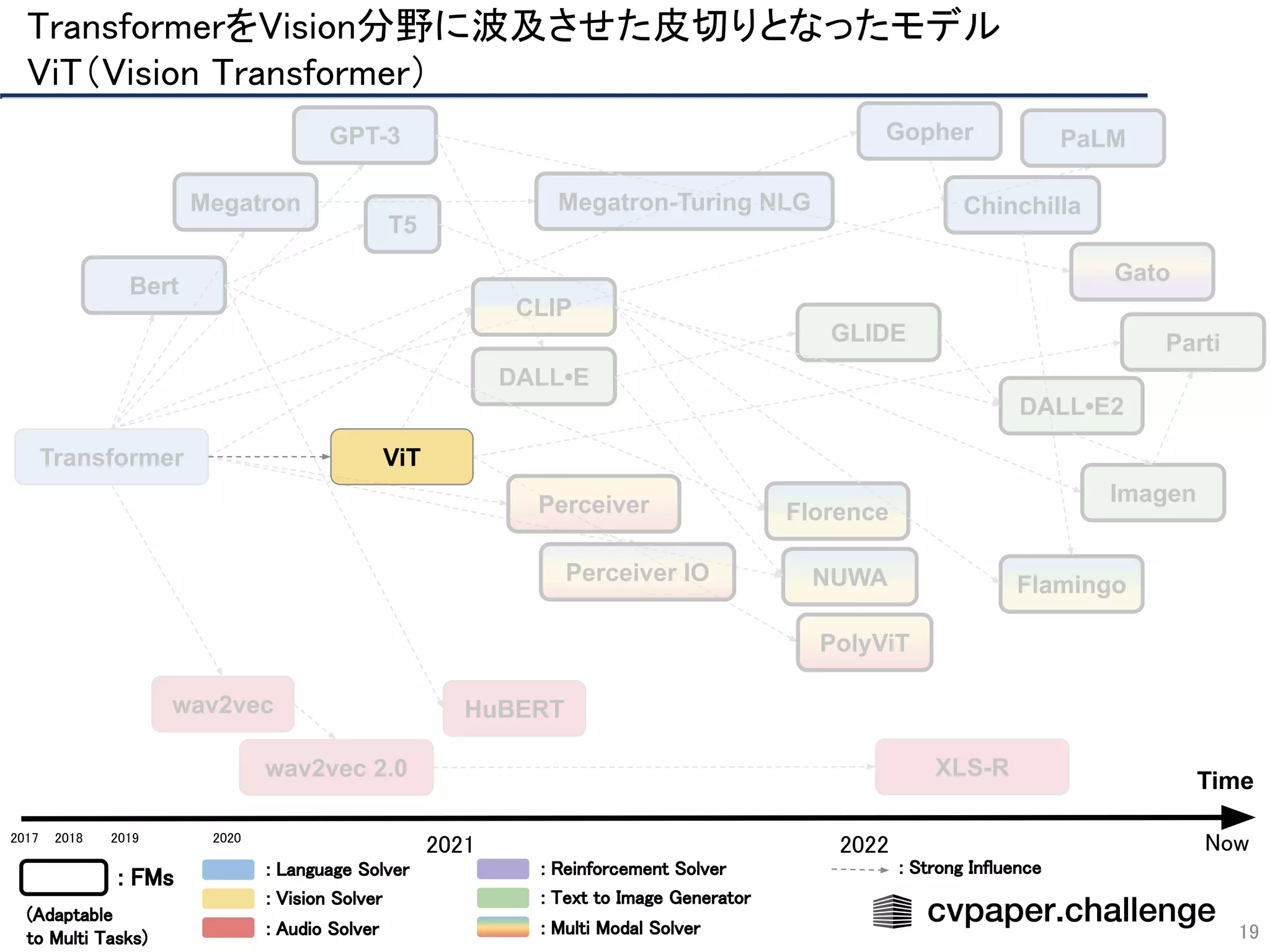
TransformerをVision分野に波及させた皮切りとなったモデル
ViT(Vision Transformer)](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-20-2048.jpg)
![21
ViTでも自己教師あり学習できることを実証
● ViTでは教師あり学習 @ ImageNet-1k/22k, JFT-300M(Googleが誇る3億のラベル付き画像データ)
● 初期よりContrastive Learning (対照学習)が提案・使用
● SimCLR / MoCo / DINOいずれもViTを学習可能
SimCLR [Chen+, ICML20] DINO [Caron+, ICCV21]
自己教師あり学習では Contrastive Learningが主流の1つ
Transformerへ適用する研究も多数
MoCo [He+, CVPR20]
TransformerをVision分野に波及させた皮切りとなったモデル
ViT(Vision Transformer)](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-21-2048.jpg)
![22
ViTにおける自己教師あり学習の真打ち!?
● “ViTでBERTする” Masked AutoEncoder (MAE)
● 画像・言語・音声の自己教師あり学習 Data2vec
MAE [He+, CVPR22]
Data2vec [Baevski+, arXiv22]
どちらも「マスクして復元」という方法論
● MAEは画像における自己教師あり学習
● Data2vecは3つのモダリティ(但しFTは個別)
● 今後,基盤モデルのための自己教師あり学習が
登場する可能性は大いにある
TransformerをVision分野に波及させた皮切りとなったモデル
ViT(Vision Transformer)](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-22-2048.jpg)

![Perceiver IO: A General Architecture for Structured
Inputs & Outputs
26
著者 : Andrew Jaegle, et al.
● 複数モダリティのデータを取り扱える
Perceiverは分類タスクのみに特化していた
● 複数モダリティの入力に対し,複数の出力(タスク)に対応可能な
Perceiver IOを提案
● 扱ったタスク
○ セグメンテーション ,言語の多様なタスク,動画予測,(
StarCractⅡ)
● 手法
○ 入力配列を潜在空間の配列に対応付けるアテンションモジュールを適用して符号化
○ 複数のアテンションモジュールを適用して潜在空間のパラメータを計算
○ 潜在空間の配列と出力配列を対応付けるアテンションモジュールを適用して復号
● 事前学習では,テキストは自己教師あり学習,画像は教師あり学習
○ 後にDeepMindは,画像などにもMAEを用いて自己教師ありで事前学習させる
Hierarchical
Perceiver[Carreira+, 2022]を発表
ICLR 2022 DeepMind Foundation Model 言語/画像/動画/音声
テキスト/画像
fine-tune
pre-train](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-26-2048.jpg)

![31
言語を媒介として視覚的情報の本質理解を目指す
“Vision and Language”の基盤モデル
CLIPは言語を介して画像の意味を捉えるレンズ
● 従来の画像エンコーダーのように
「そのものに意味がない記号(ラベル)」によって画像を捉えるのではなく,
「そのものに意味がある言語表現」によって画像を捉える
ため,より解像度の高い自然な画像理解を達成し得る
従来の
画像分類で
事前学習
CLIPで
事前学習
“白と黒のぶち猫が
座ってこちらを見ている ”
Class: 3
CLIP [Radford(OpenAI)+, CVPR21]
画像分類
テキストからの
画像生成
画像自動
キャプショニング
物体検出
VQA
視覚言語
ナビゲーション
画像キャプション
妥当性評価
NeRFによる
シーン生成
他モダリティ
拡張
多種多様な画像認識タスク,
Vision and Languageタスク
への応用が可能](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-31-2048.jpg)
![33
言語を媒介として視覚的情報の本質理解を目指す
“Vision and Language”の基盤モデル
次々に更新される文章から画像生成する基盤モデル
● DALL•E [Ramesh(OpenAI)+, ICML21]
● CLIDE [Nichol(OpenAI)+, ACL22]
● VQGAN-CLIP [Crowson(EleutherAI)+, arXiv22]
大体どのモデルも生成時のお気持ちはこんな感じ.
“こっち見てる白黒ぶち猫
”
Text
Encoder
復元
圧縮
テキストから潜在表現を獲得するブロック
(Text Encoder)
テキストの潜在表現から画像を生成するブロック
(Image Generator)
基盤モデル間で異なる主な要素は,
● Text Encoder に何を使うか
● Image Generator に何を使うか
● DALL•E 2 [Ramesh(OpenAI)+, arXiv22]
● Imagen [Saharia(Google)+, arXiv22]
● Parti [Yu(Google)+, arXiv22]
etc…](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-33-2048.jpg)
![34
言語を媒介として視覚的情報の本質理解を目指す
“Vision and Language”の基盤モデル
Text Encoder
Image Generator
DALL•E
GLIDE
VQGAN-CLIP
DALL•E 2
Imagen
Parti
BPE
VQ-VAE
+
Transformer(GPT-3 like)
VQGAN
+
CLIP
CLIP
DDPM
+
Classsifier-free Guidance
Transformer
DDPM
+
Classsifier-free Guidance
+
CLIP
T5-XXL
DDPM
+
Classsifier-free Guidance
ViT-VQGAN
+
Classsifier-free Guidance
+
Transformer
SentencePiece
model
CLIP
VQ-VAE(Vector Quantised-Variational AutoEncoder):
潜在変数を離散的なベクトルとして持たせて学習させ、複合して
画像を生成するモデル,オートエンコーダー
VQGAN:
VQ-VAEの進化系で,以下の点で異なる.
- PixelCNNの代わりにTransformerを導入し広い視野獲得
- GANの併用により,精度保ったまま
Patchの解像度を圧縮可能に
DDPM(拡散確率モデル) :
ソース画像に複数回ノイズを加え
(forward process),
最終的にノイズのみになるガウス確率過程を考え,
その逆過程を学習して遡ることで
(reverse process),
完全なノイズから画像の生成を行う.
VQ-VAE [Oord(DeepMind)+, NeurIPS17]
VQGAN [Esser(HCIP)+, CVPR21]
Denoising Diffusion Probabilistic Model
[Ho(UC Berkeley)+, NeurIPS20]
基本的に下に行くほど
新しく性能の高い
アーキテクチャ
次々に更新される文章から画像生成する基盤モデル](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-34-2048.jpg)





![41
言語を媒介として視覚的情報の本質理解を目指す
“Vision and Language”の基盤モデル
多種多様なVisionタスクを
言語を介して解く基盤モデル
Flamingo [Alayac(DeepMind)+, arXiv22]
Florence [Lu Yuan(Microsoft)+, arXiv21]](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-41-2048.jpg)




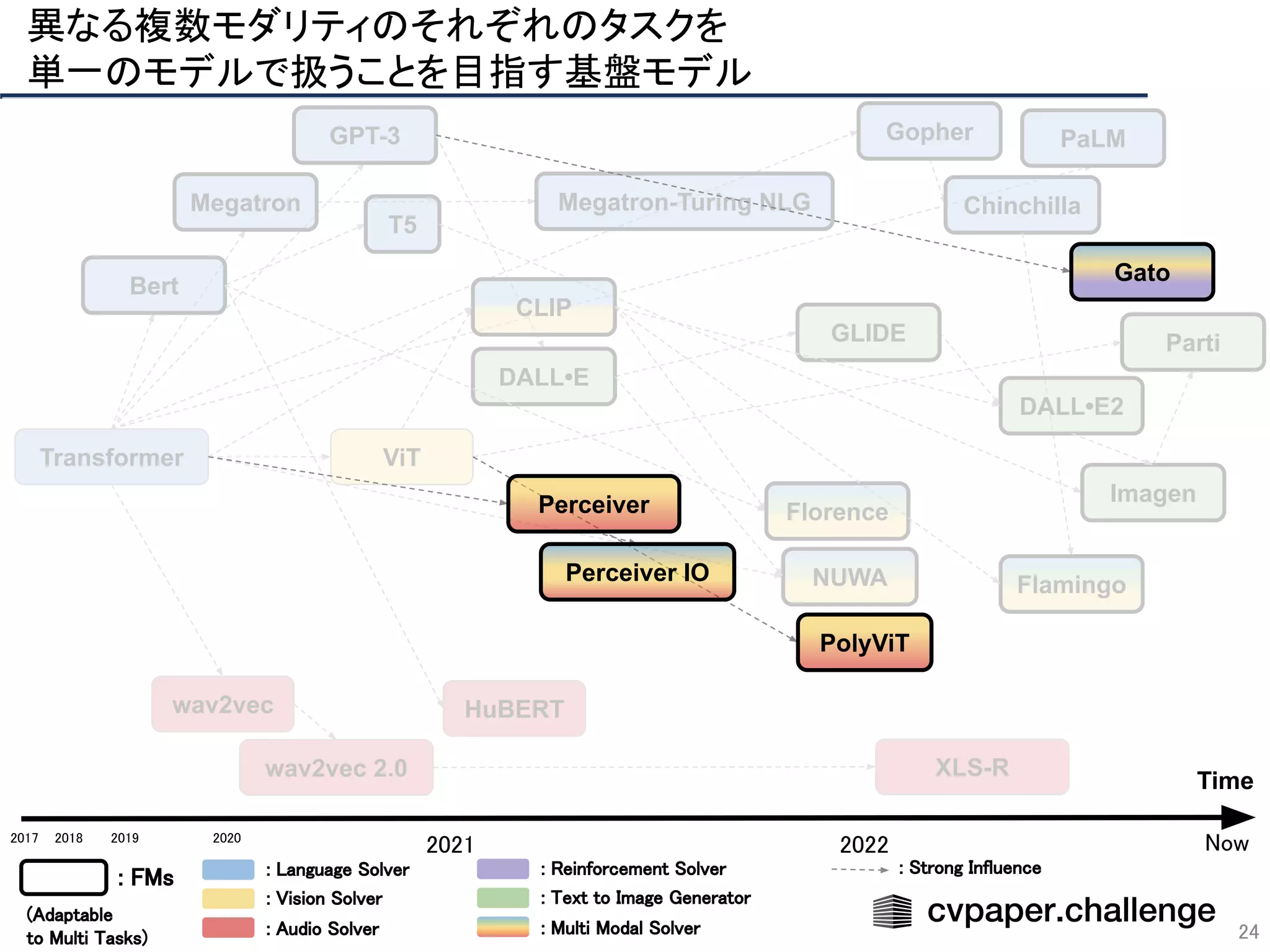
![マルチモダリティ/マルチタスク化の促進
48
複数モダリティでのデータ入力が可能
○ あらゆるデータをtokenizeしてTransformerで処理
→各分野のタスクを基盤モデルによる学習で統合
Visionに限らずあらゆるモダリティを基盤モデルによって
統一的に学習できるようになる(かも)
PolyViT [Likhosherstov(Google)+, ICLR22]
Gato [Reed(DeepMind)+, arXiv22]
入力形式:テキスト,画像,音声,動画,数値,…
分野:言語処理,画像認識,音声認識,行動認識,…](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-48-2048.jpg)
![Foundation Modelsのスケーリング則
49
スケーリング則(Scaling Law)
● モデルパラメータサイズ
● 事前学習データセットサイズ
● 計算予算
の3要素を同時にスケーリングすると性能が際限なく向上していく,
という仮説
Scaling Vision Transformers [Zhai+, CVPR22]
GPT-3 [Brown+, NeurIPS22]](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-49-2048.jpg)


![54
“思考停止”のスケーリングは資源の枯渇を招く
○ スケーリングを行う過程では
データ効率,パラメータ効率,計算効率
の追求が必須(ただ各要素をデカくするだけではダメ)
スケーリング則が基盤モデル研究に与えるリスク
An empirical analysis of compute-optimal large language model training
(chinchilla [Hoffmann(DeepMind)+, arXiv22]のプロジェクトページ )より
https://medium.com/@thepathtochange/maybe-microsoft-s-tay-ai-didn-t-have-a-meltdown-4291b910a37c
DeepMindがchinchillaの発表に伴い,
最近の言語基盤モデルが,モデルパラメータを大きくしすぎて
学習データ不足による精度劣化を引き起こしている ことを指摘](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-54-2048.jpg)

![56
JFT-300M/3B/4B (Google, 2017/2021/2022)
→約3億/30億/40億枚の画像データセット
IG-3.5B (Facebook, 2018)
→約35億枚の画像データセット
スケーリング則が基盤モデル研究に与えるリスク
巨大Tech企業による大規模データセット寡占化
○ 独自に保有するプラットフォームで
非公開な超大規模データを収集し利用
Parti [Yu(Google)+, arXiv22]
プライバシーの問題や誤用の懸念がある以上,
容易に公開はできず難しい問題](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-56-2048.jpg)





More Related Content
What's hot (20)
Similar to 【メタサーベイ】基盤モデル / Foundation Models (20)
Recently uploaded (15)
【メタサーベイ】基盤モデル / Foundation Models
- 1. Foundation Models 基盤モデル 高島空良, 中村凌, 山田亮佑, 片岡裕雄 1 http://xpaperchallenge.org/cv
- 2. 発表者紹介 2 ❖ 高島 空良 ➢ 所属 ■ 東京工業大学 情報理工学院 横田(理)研究室 修士2年 ■ cvpaper.challenge(2022/1〜) ■ 産業技術総合研究所 デジタルアーキテクチャ研究センターRA ➢ 研究 ■ FDSL(数式ドリブン教師あり学習)の大規模スケーリング ■ SAMの正則化効果など最適化手法についての調査 ➢ その他の活動 ■ 競技プログラミング(最近着手できていない …) ■ この夏Kaggleを始めてみるつもりです!
- 3. 本発表について 3 cvpaper.challengeのメタサーベイ ● 2022/03/01~2022/07/08現在に実施した調査 ● 今回は主にコンピュータビジョン研究者の視点からFoundation Models(基盤モデル)を調査 ● トピックのサーベイはもちろん,論文の背後にある情報(メタな 知識)も収集
- 4. アジェンダ 4 1. イントロダクション+論文サマリ Foundation Modelsの概観について, 具体的な例を論文サマリとして提示しつつ説明 1.1. 基盤モデルとは? 1.2. Transformerの誕生と発展 1.3. ViTによるVisionへのモダリティシフト 1.4. マルチモーダルな基盤モデルの台頭 2. メタサーベイ 全体を俯瞰してFoundation Modelsの動向をまとめる
- 5. アジェンダ 5 1. イントロダクション+論文サマリ Foundation Modelsの概観について, 具体的な例を論文サマリとして提示しつつ説明 1.1. 基盤モデルとは? 1.2. Transformerの誕生と発展 1.3. ViTによるVisionへのモダリティシフト 1.4. マルチモーダルな基盤モデルの台頭 2. メタサーベイ 全体を俯瞰してFoundation Modelsの動向をまとめる
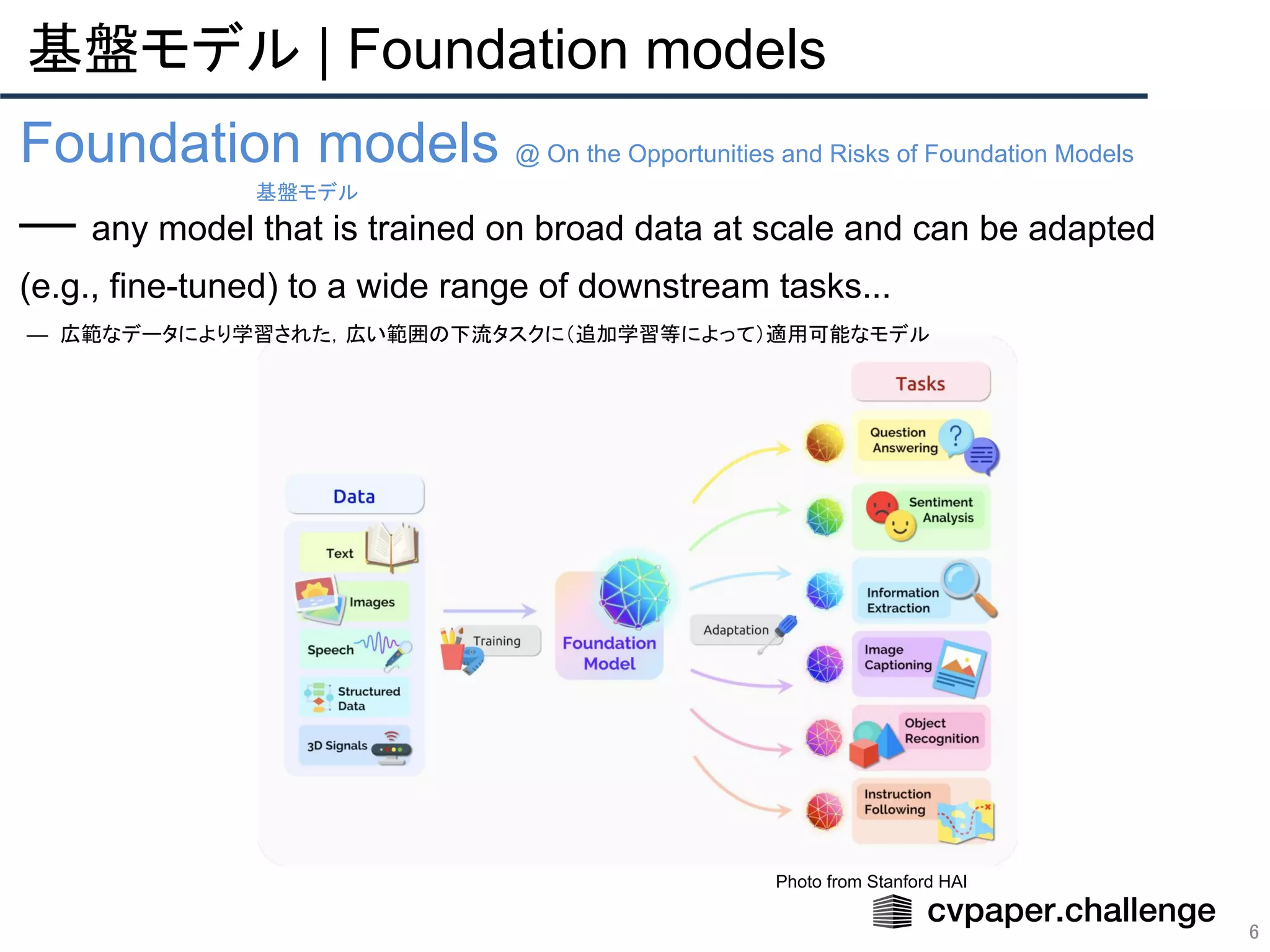
- 6. 基盤モデル | Foundation models 6 Foundation models @ On the Opportunities and Risks of Foundation Models — any model that is trained on broad data at scale and can be adapted (e.g., fine-tuned) to a wide range of downstream tasks... — 広範なデータにより学習された,広い範囲の下流タスクに(追加学習等によって)適用可能なモデル 基盤モデル Photo from Stanford HAI
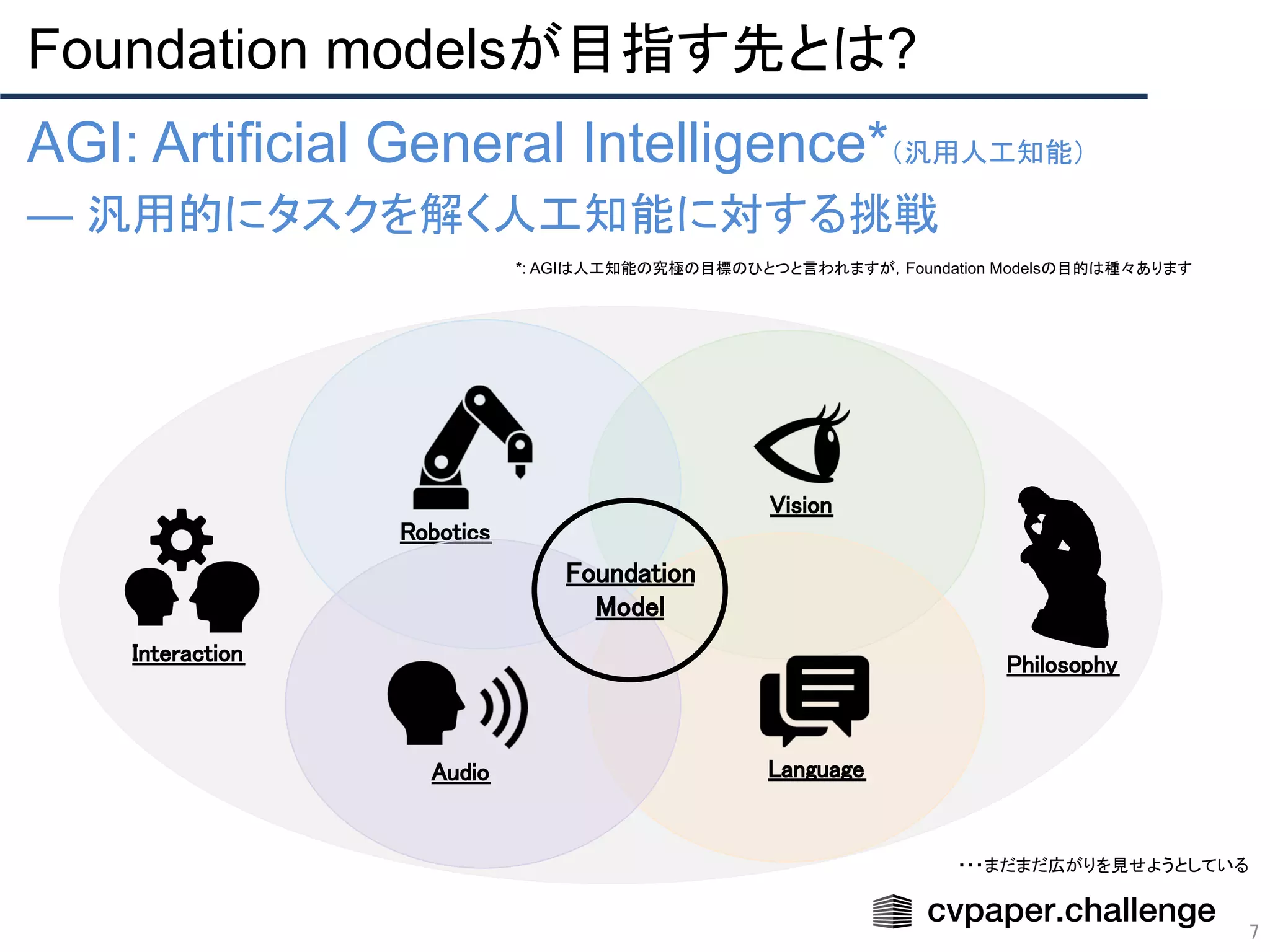
- 7. Foundation modelsが目指す先とは? 7 AGI: Artificial General Intelligence*(汎用人工知能) — 汎用的にタスクを解く人工知能に対する挑戦 Robotics Vision Language Audio Foundation Model Philosophy Interaction ・・・まだまだ広がりを見せようとしている *: AGIは人工知能の究極の目標のひとつと言われますが,Foundation Modelsの目的は種々あります
- 8. 2022年現在,CVに波及する基盤モデルの衝撃 8 DALL•E2やFlamingoなど言語と視覚を繋ぐモデルが台頭 画像・動画・言語の複数モダリティを同時に処理 ● 画像/動画と言語を別々に学習して統合 ● 70Bパラメータの事前学習済みテキストエンコーダーと CLIP方式で事前学習済み画像エンコーダーがベース ● ベースラインのわずか 1/1000程度のみのサンプル提示で VQAなどの6/16のマルチモーダルタスクで SoTA達成. 追加学習を行うと更に 5つのベンチマークで SoTA達成. 自然言語から高精細な画像を生成 ● CLIP : 画像・言語空間の対応関係を高度に学習 ○ WEB上から収集した約4億組の画像・言語ペアにより学習 ● DDPM : ノイズ付与/復元により高解像画像描画するモデル ● CLIPの画像埋め込み特徴を生成するように DDPM を学習させ,多様性に富んだ Text-to-Imageのモデルを構築 ● この結果,AIは創造性を持ったと総評されるに至る 次ページよりTransformer〜Foudation Models(FMs)に至るまでを解説↓ Flamingo [Alayac(DeepMind)+, arXiv22] DALL•E 2 [Ramesh(OpenAI)+, arXiv22] ロボットのような半顔を持つ サルバドール・ダリの鮮やかな肖像画 ベレー帽と黒のタートルネック を身に付けた柴犬 葉を茂らせた手掌のクローズアップ
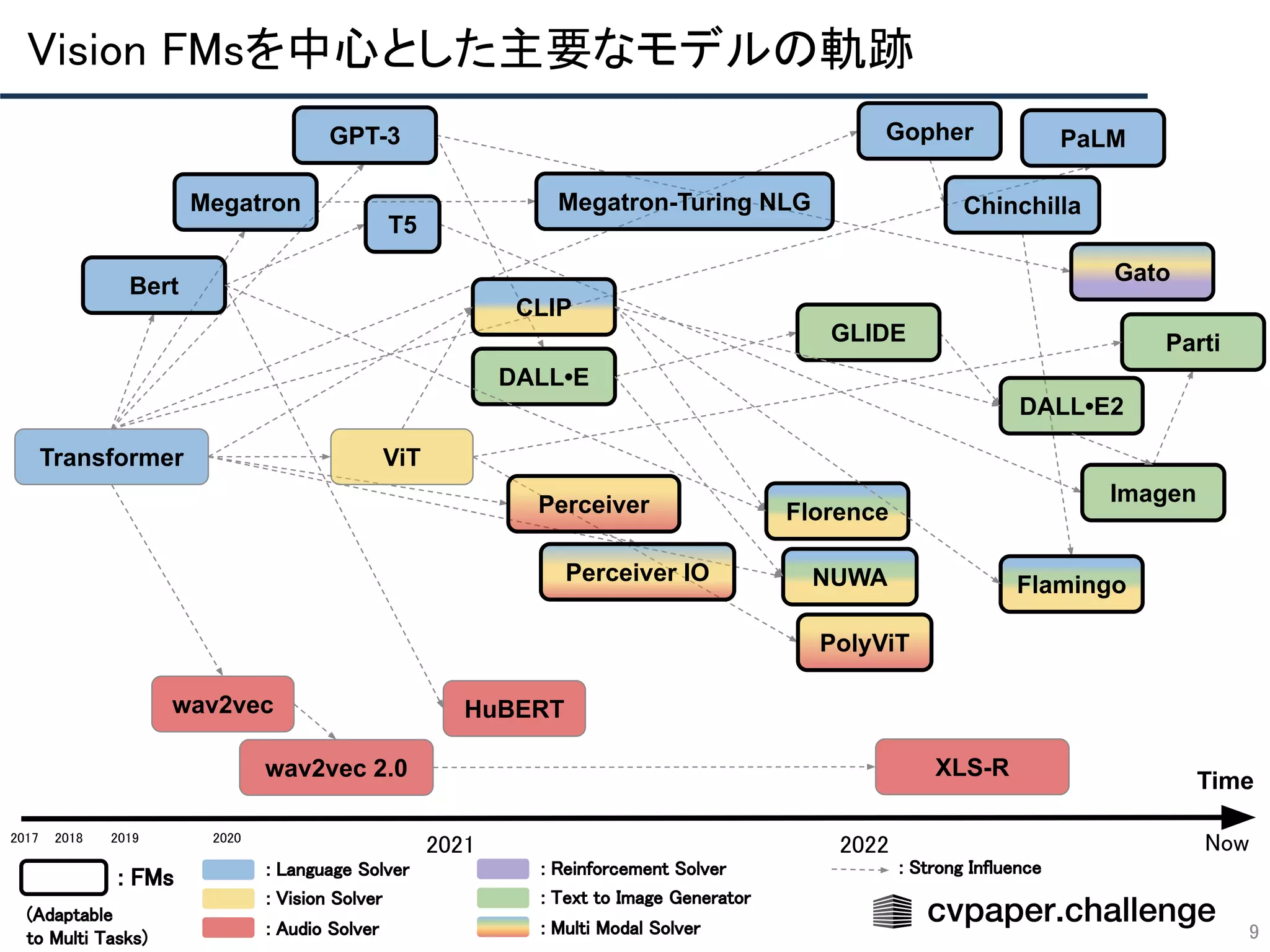
- 9. Vision FMsを中心とした主要なモデルの軌跡 9 Time 2018 2019 2020 2021 2022 Transformer Bert PolyViT Florence CLIP ViT NUWA Perceiver GPT-3 PaLM Perceiver IO Gato DALL•E DALL•E2 GLIDE Imagen Parti Megatron wav2vec wav2vec 2.0 XLS-R Gopher 2017 : FMs : Language Solver : Vision Solver : Audio Solver : Reinforcement Solver : Text to Image Generator : Multi Modal Solver (Adaptable to Multi Tasks) Now HuBERT Megatron-Turing NLG T5 : Strong Influence Flamingo Chinchilla
- 10. アジェンダ 10 1. イントロダクション+論文サマリ Foundation Modelsの概観について, 具体的な例を論文サマリとして提示しつつ説明 1.1. 基盤モデルとは? 1.2. Transformerの誕生と発展 1.3. ViTによるVisionへのモダリティシフト 1.4. マルチモーダルな基盤モデルの台頭 2. メタサーベイ 全体を俯瞰してFoundation Modelsの動向をまとめる
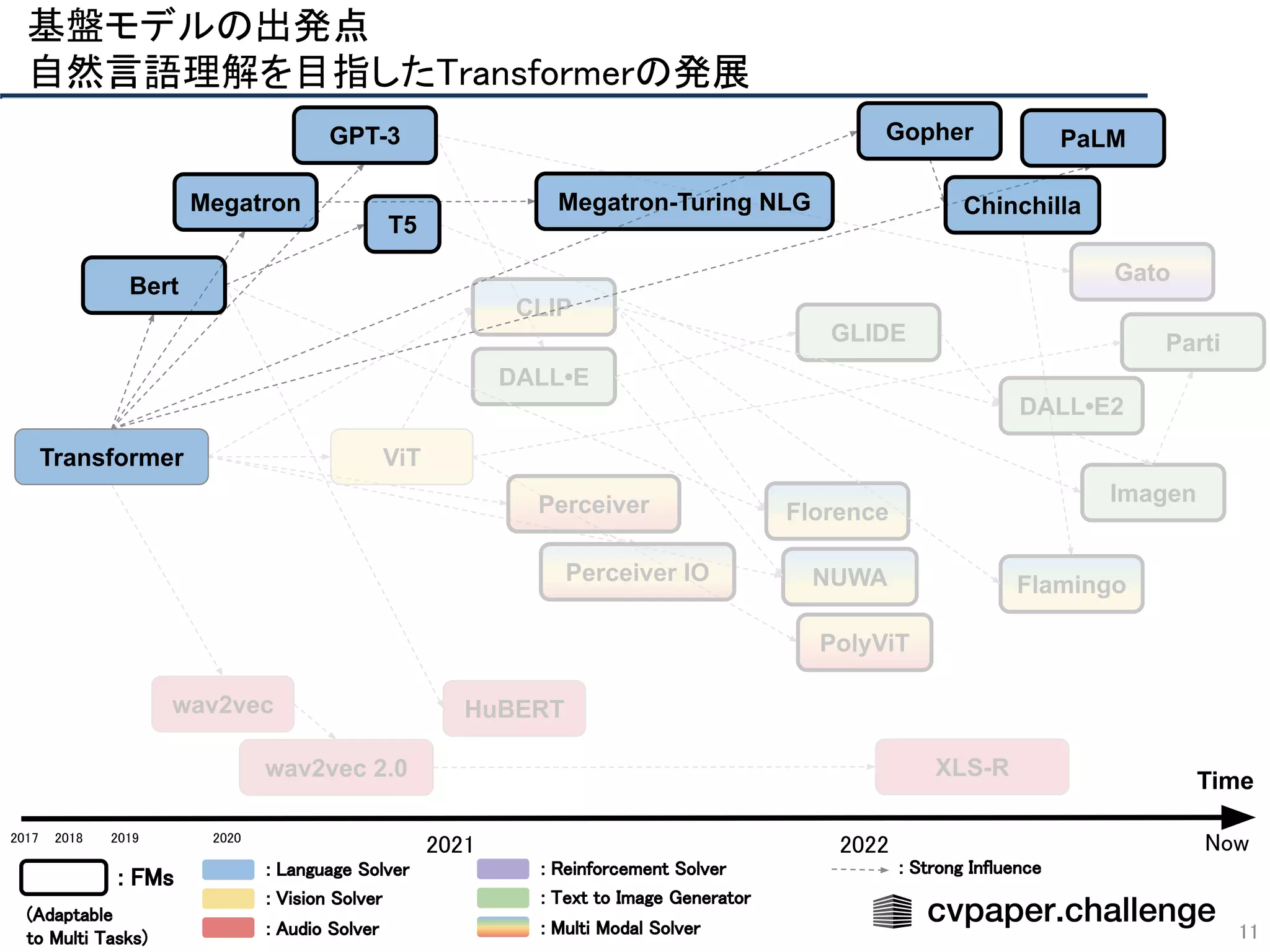
- 11. PolyViT Florence CLIP ViT NUWA Perceiver Perceiver IO Gato DALL•E DALL•E2 GLIDE Imagen Parti wav2vec wav2vec 2.0 XLS-R HuBERT Flamingo 基盤モデルの出発点 自然言語理解を目指したTransformerの発展 11 Time 2018 2019 2020 2021 2022 Transformer Bert GPT-3 PaLM Megatron Gopher 2017 : FMs : Language Solver : Vision Solver : Audio Solver : Reinforcement Solver : Text to Image Generator : Multi Modal Solver (Adaptable to Multi Tasks) Now Megatron-Turing NLG T5 : Strong Influence Chinchilla
- 12. 12 自然言語処理(NLP)分野でTransformerが誕生 ● Transformer ● Self-Attention(自己注意)機構により 系列データを一括同時処理可能に (従来のRNNでは逐次的に処理 →並列計算できず 処理に時間がかかる , 離れた単語関係が見えず 長文理解は困難 ) ○ GPUフレンドリーで 容易に並列計算による学習高速化可能 ○ 入力シーケンス全体を考慮可能 ● 劇的な学習時間短縮・性能向上を同時に実 現し,ブレイクスルーを引き起こした (当時の翻訳タスクでSoTAを達成) Transformerについてはこちらも参照 https://www.slideshare.net/cvpaperchallenge/transformer-247407256 [Vaswani(Google)+, NeurIPS17] 基盤モデルの出発点 自然言語理解を目指したTransformerの発展 急発達するHPCによるGPU/TPU並列計算技術と相性抜群. 近代のほぼ全ての大規模基盤モデルは,Transformerがベースに
- 13. 13 NLP分野にてTransformerが拡がる ● BERT(Bi-directional Encoder Representations from Transformers) ● 大量の汎用テキストデータで事前学習→タスクに合わせて追加学習 ● 翻訳・予測などNLPのタスクを幅広く解くことができるモデル ● 文章の「意味を理解」することができるようになったと話題 ● なぜBERTは躍進した? ● 自己教師学習によりラベルなし文章を学習に適用可能 ● 双方向モデルにつき,単語の前後から文脈を把握 BERTでは多くのタスクを単一モデルで解くことができ るが,その学習は「文章のマスクと復元」の自己教師 あり学習により実施される Attention is All You Need.(元データ) ↓ 意図的に欠損作成 Attention is All ___ Need.(復元前) ↓ BERTにより推定 Attention is All You Need.(復元後) [Devlin(Google)+, NAACL19] 基盤モデルの出発点 自然言語理解を目指したTransformerの発展
- 14. GPT-3論文はNeurIPS 2020にて Best Paper Awardを獲得 14 人間レベルの文章生成を可能に ● GPT(Generative Pre-trained Transformer) ● 与えられた文章の先を予測して文章生成 ● 拡張される度にパラメータ数 / 学習テキストサイズが一気に増加 ○ GPT : 1.2億パラメータ ○ GPT-2 : 15億パラメータ, 40GBテキスト ○ GPT-3 : 1750億パラメータ, 570GBテキスト(3000億トークン) ○ 爆発的なパラメータ数の増加により大幅な性能改善が見られた ● 「シンギュラリティが来た」と言われるほどに文章生成能力を獲得 https://neuripsconf.medium.com/announcing-the-neurips-2020-award-recipients-73e4d3101537 [Brown(OpenAI)+, NeurIPS20] 基盤モデルの出発点 自然言語理解を目指したTransformerの発展
- 15. Language Models are Few-Shot Learners (GPT-3論文) 15 著者 : Tom Brown, et al. 大規模なパラメータを用いて事前学習を行ったGPT-3は Fine-tuningなしで20種類以上の自然言語処理タスクに適応 ● 既存モデルの10倍以上,1750億パラメータをもつSparse Transformerベースの自己回帰モデル GPT-3を.計 3000億トークンのテキストデータを用いて事前学習 ● 文章のみでタスクを示す in-context方式を採用し,翻訳・穴埋め・算数など複数のタスクを解かせた ○ exampleの数を「Zero-shot」「One-shot」「Few-shot」の3パターンに分けて精度を検証 ● Few-shotでは多くのタスクで教師あり SOTA手法に近い性能を実現。翻訳、穴埋めなどでは SOTA達成も s.u!c/c!e.s s i/o/n から succession を復元するようなタスクの場合 in-contextで計算を行わせるタスクの例 Few-shotの例. 複数のexamplesが示されている NeurIPS 2020 OpenAI テキスト Foundation Model 言語 zero/one/few-shot pre-train
- 16. PaLM: Scaling Language Modeling with Pathways 著者 : Aakanksha Chowdhery, et al. 超大規模Transformer model「PaLM」 5400億パラメータまでモデルを拡張し、 主要な29種の言語処理タスク中28種でSOTA達成 ● 複数TPU podを横断した計算を効率化する深層学習基盤 Pathwaysを用いてSSL ○ 訓練データには,計7800億トークンもの様々なテキストデータを使用 ○ 計算資源として,計6144個のTPU v4を使用 ● 150のタスクが混合された言語ベンチマークBIG-bench でも平均的な人間の性能を上回り, コーディングタスクや多言語タスク(翻訳・多言語QA)でもSOTAに迫る高い性能を発揮 ● モデルのスケールをある程度大きくすると, いくつかのタスク(15%〜25%ほど)において これまで解けなかったタスクが急にできるようになる 「非連続的な改善」が見られた 16 冪乗則に従った改善をするタスク例 論理的に正しいものを選択 非連続的な改善をするタスク例 論理的に正しい並び方を選択 緩やかな改善をするタスク例 数学的な証明 Model FLOPs ベースの利用率においても、46.2%と最高峰のハードウェア利用率を達成 arXiv 2022 Google Foundation Model テキスト 言語 zero-shot/fine-tune pre-train
- 17. Transformerは尚もNLP分野にて進展,Vision/Audio/Robotics分野にも展開 17 その後もTransformerの勢いは止まらない Attentionこそ全て! 文章の先を予測! (その後大規模化により GPT-2/3に改良) 文章の文脈を 双方向から理解! マスク・復元により自 己教師学習 画像と言語を処理 畳み込みとの融合により 画像認識(検出)を実現 純粋にTransformer構造で画像認識 その後,入力の工夫で動画認識 Natural Language Processing Natural Language Processing Vision & Language Computer Vision 基盤モデルの出発点 自然言語理解を目指したTransformerの発展
- 18. アジェンダ 18 1. イントロダクション+論文サマリ Foundation Modelsの概観について, 具体的な例を論文サマリとして提示しつつ説明 1.1. 基盤モデルとは? 1.2. Transformerの誕生と発展 1.3. ViTによるVisionへのモダリティシフト 1.4. マルチモーダルな基盤モデルの台頭 2. メタサーベイ 全体を俯瞰してFoundation Modelsの動向をまとめる
- 19. Transformer Bert GPT-3 PaLM Megatron Gopher Megatron-Turing NLG T5 Chinchilla PolyViT Florence CLIP NUWA Perceiver Perceiver IO Gato DALL•E DALL•E2 GLIDE Imagen Parti wav2vec wav2vec 2.0 XLS-R HuBERT Flamingo TransformerをVision分野に波及させた皮切りとなったモデル ViT(Vision Transformer) 19 Time 2018 2019 2020 2021 2022 2017 : FMs : Language Solver : Vision Solver : Audio Solver : Reinforcement Solver : Text to Image Generator : Multi Modal Solver (Adaptable to Multi Tasks) Now : Strong Influence ViT
- 20. 20 Vision Transformer(ViT) ● 純Transformer構造により画像認識 ● 画像パッチを単語と見なして処理 ● Encoderのみ使用 / MLPを通して出力 ● 3億枚のラベル付き画像で事前学習 →CNNを超えたか?と話題に ● ViTの後にも亜種が登場 ● CNN + Transformer: CvT, ConViT(擬似畳込み), CMT, CoAtNet ● MLP: MLP-Mixer, gMLP(Attentionそのものではなく構造が重要?) ● ViT: DeiT, Swin Transformer ViT [Dosovitskiy(Google)+, ICLR21] 【Swin Transformer V1/V2】 Swin Transformer V1 [Liu(Microsoft)+, ICCV21] Swin Transformer V2 [Liu(Microsoft)+, CVPR22] TransformerをVision分野に波及させた皮切りとなったモデル ViT(Vision Transformer)
- 21. 21 ViTでも自己教師あり学習できることを実証 ● ViTでは教師あり学習 @ ImageNet-1k/22k, JFT-300M(Googleが誇る3億のラベル付き画像データ) ● 初期よりContrastive Learning (対照学習)が提案・使用 ● SimCLR / MoCo / DINOいずれもViTを学習可能 SimCLR [Chen+, ICML20] DINO [Caron+, ICCV21] 自己教師あり学習では Contrastive Learningが主流の1つ Transformerへ適用する研究も多数 MoCo [He+, CVPR20] TransformerをVision分野に波及させた皮切りとなったモデル ViT(Vision Transformer)
- 22. 22 ViTにおける自己教師あり学習の真打ち!? ● “ViTでBERTする” Masked AutoEncoder (MAE) ● 画像・言語・音声の自己教師あり学習 Data2vec MAE [He+, CVPR22] Data2vec [Baevski+, arXiv22] どちらも「マスクして復元」という方法論 ● MAEは画像における自己教師あり学習 ● Data2vecは3つのモダリティ(但しFTは個別) ● 今後,基盤モデルのための自己教師あり学習が 登場する可能性は大いにある TransformerをVision分野に波及させた皮切りとなったモデル ViT(Vision Transformer)
- 23. アジェンダ 23 1. イントロダクション+論文サマリ Foundation Modelsの概観について, 具体的な例を論文サマリとして提示しつつ説明 1.1. 基盤モデルとは? 1.2. Transformerの誕生と発展 1.3. ViTによるVisionへのモダリティシフト 1.4. マルチモーダルな基盤モデルの台頭 2. メタサーベイ 全体を俯瞰してFoundation Modelsの動向をまとめる
- 24. ViT Transformer Bert GPT-3 PaLM Megatron Gopher Megatron-Turing NLG T5 Chinchilla Florence CLIP NUWA DALL•E DALL•E2 GLIDE Imagen Parti wav2vec wav2vec 2.0 XLS-R HuBERT Flamingo 異なる複数モダリティのそれぞれのタスクを 単一のモデルで扱うことを目指す基盤モデル 24 Time 2018 2019 2020 2021 2022 2017 : FMs : Language Solver : Vision Solver : Audio Solver : Reinforcement Solver : Text to Image Generator : Multi Modal Solver (Adaptable to Multi Tasks) Now : Strong Influence PolyViT Perceiver Perceiver IO Gato
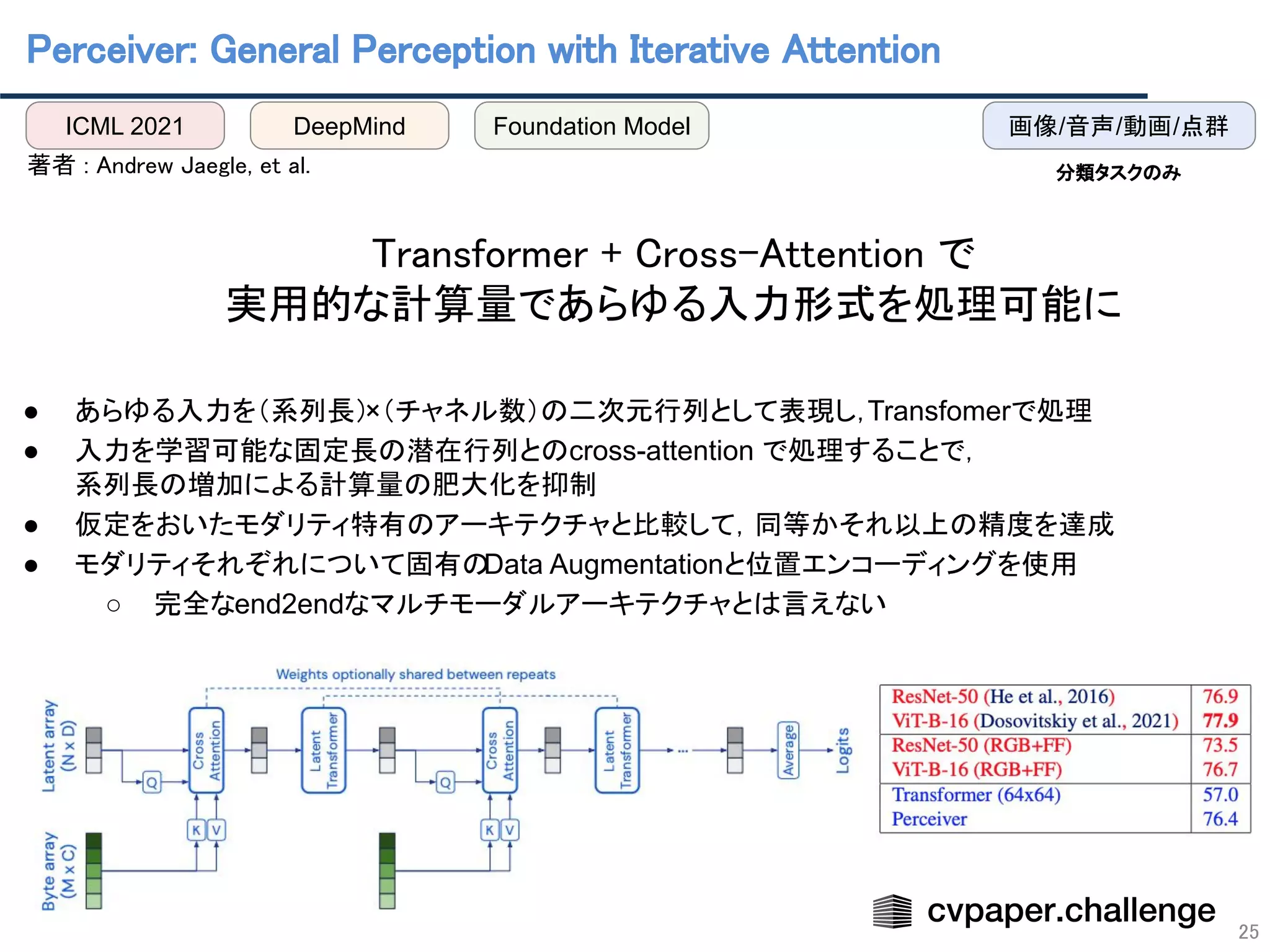
- 25. Perceiver: General Perception with Iterative Attention 著者 : Andrew Jaegle, et al. Transformer + Cross-Attention で 実用的な計算量であらゆる入力形式を処理可能に ● あらゆる入力を(系列長)×(チャネル数)の二次元行列として表現し, Transfomerで処理 ● 入力を学習可能な固定長の潜在行列とのcross-attention で処理することで, 系列長の増加による計算量の肥大化を抑制 ● 仮定をおいたモダリティ特有のアーキテクチャと比較して,同等かそれ以上の精度を達成 ● モダリティそれぞれについて固有の Data Augmentationと位置エンコーディングを使用 ○ 完全なend2endなマルチモーダルアーキテクチャとは言えない 25 ICML 2021 DeepMind 画像/音声/動画/点群 分類タスクのみ Foundation Model
- 26. Perceiver IO: A General Architecture for Structured Inputs & Outputs 26 著者 : Andrew Jaegle, et al. ● 複数モダリティのデータを取り扱える Perceiverは分類タスクのみに特化していた ● 複数モダリティの入力に対し,複数の出力(タスク)に対応可能な Perceiver IOを提案 ● 扱ったタスク ○ セグメンテーション ,言語の多様なタスク,動画予測,( StarCractⅡ) ● 手法 ○ 入力配列を潜在空間の配列に対応付けるアテンションモジュールを適用して符号化 ○ 複数のアテンションモジュールを適用して潜在空間のパラメータを計算 ○ 潜在空間の配列と出力配列を対応付けるアテンションモジュールを適用して復号 ● 事前学習では,テキストは自己教師あり学習,画像は教師あり学習 ○ 後にDeepMindは,画像などにもMAEを用いて自己教師ありで事前学習させる Hierarchical Perceiver[Carreira+, 2022]を発表 ICLR 2022 DeepMind Foundation Model 言語/画像/動画/音声 テキスト/画像 fine-tune pre-train
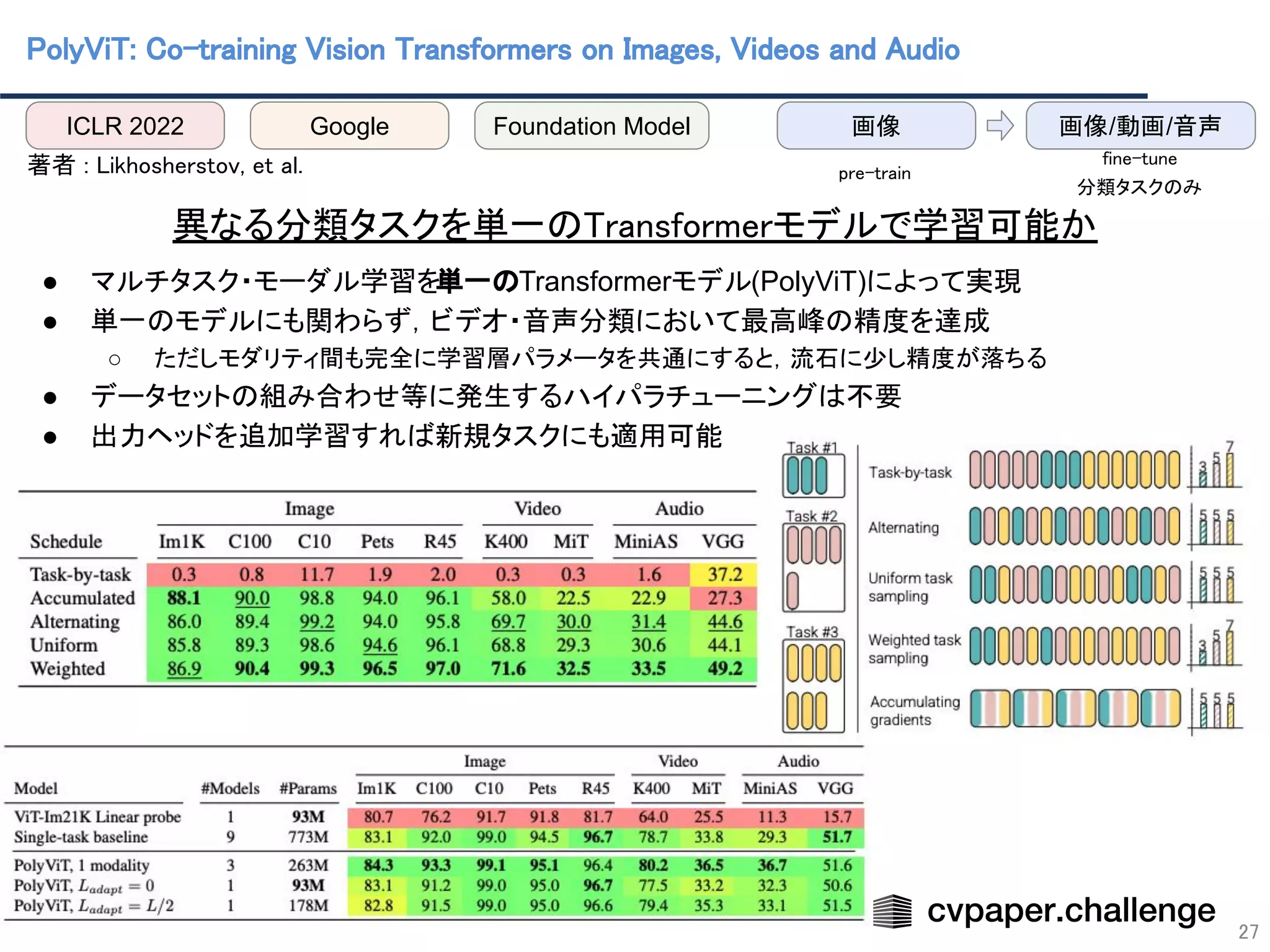
- 27. PolyViT: Co-training Vision Transformers on Images, Videos and Audio 27 著者 : Likhosherstov, et al. ● マルチタスク・モーダル学習を単一のTransformerモデル(PolyViT)によって実現 ● 単一のモデルにも関わらず,ビデオ・音声分類において最高峰の精度を達成 ○ ただしモダリティ間も完全に学習層パラメータを共通にすると,流石に少し精度が落ちる ● データセットの組み合わせ等に発生するハイパラチューニングは不要 ● 出力ヘッドを追加学習すれば新規タスクにも適用可能 異なる分類タスクを単一のTransformerモデルで学習可能か ICLR 2022 Google Foundation Model 画像/動画/音声 画像 pre-train fine-tune 分類タスクのみ
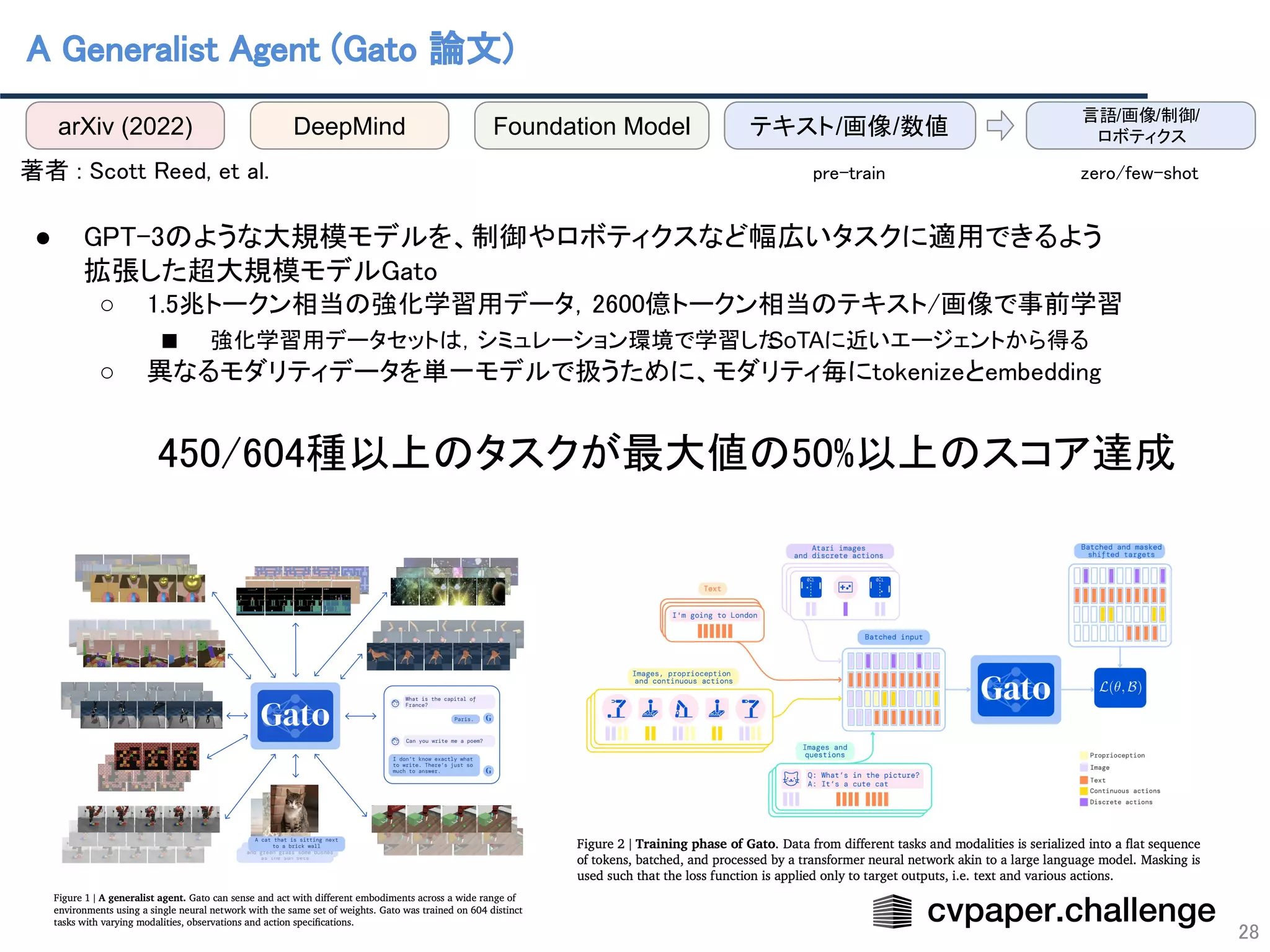
- 28. A Generalist Agent (Gato 論文) 28 著者 : Scott Reed, et al. ● GPT-3のような大規模モデルを、制御やロボティクスなど幅広いタスクに適用できるよう 拡張した超大規模モデルGato ○ 1.5兆トークン相当の強化学習用データ,2600億トークン相当のテキスト/画像で事前学習 ■ 強化学習用データセットは,シミュレーション環境で学習した SoTAに近いエージェントから得る ○ 異なるモダリティデータを単一モデルで扱うために、モダリティ毎にtokenizeとembedding 450/604種以上のタスクが最大値の50%以上のスコア達成 arXiv (2022) DeepMind 言語/画像/制御/ ロボティクス テキスト/画像/数値 Foundation Model pre-train zero/few-shot
- 29. PolyViT Perceiver Perceiver IO ViT Transformer Bert GPT-3 PaLM Megatron Gopher Megatron-Turing NLG T5 Chinchilla Gato wav2vec wav2vec 2.0 XLS-R HuBERT 言語を媒介として視覚的情報の本質理解を目指す “Vision and Language”の基盤モデル 29 2018 2019 2020 2021 2022 2017 : FMs : Language Solver : Vision Solver : Audio Solver : Reinforcement Solver : Text to Image Generator : Multi Modal Solver (Adaptable to Multi Tasks) : Strong Influence Florence CLIP NUWA DALL•E DALL•E2 GLIDE Imagen Parti Flamingo Time Now
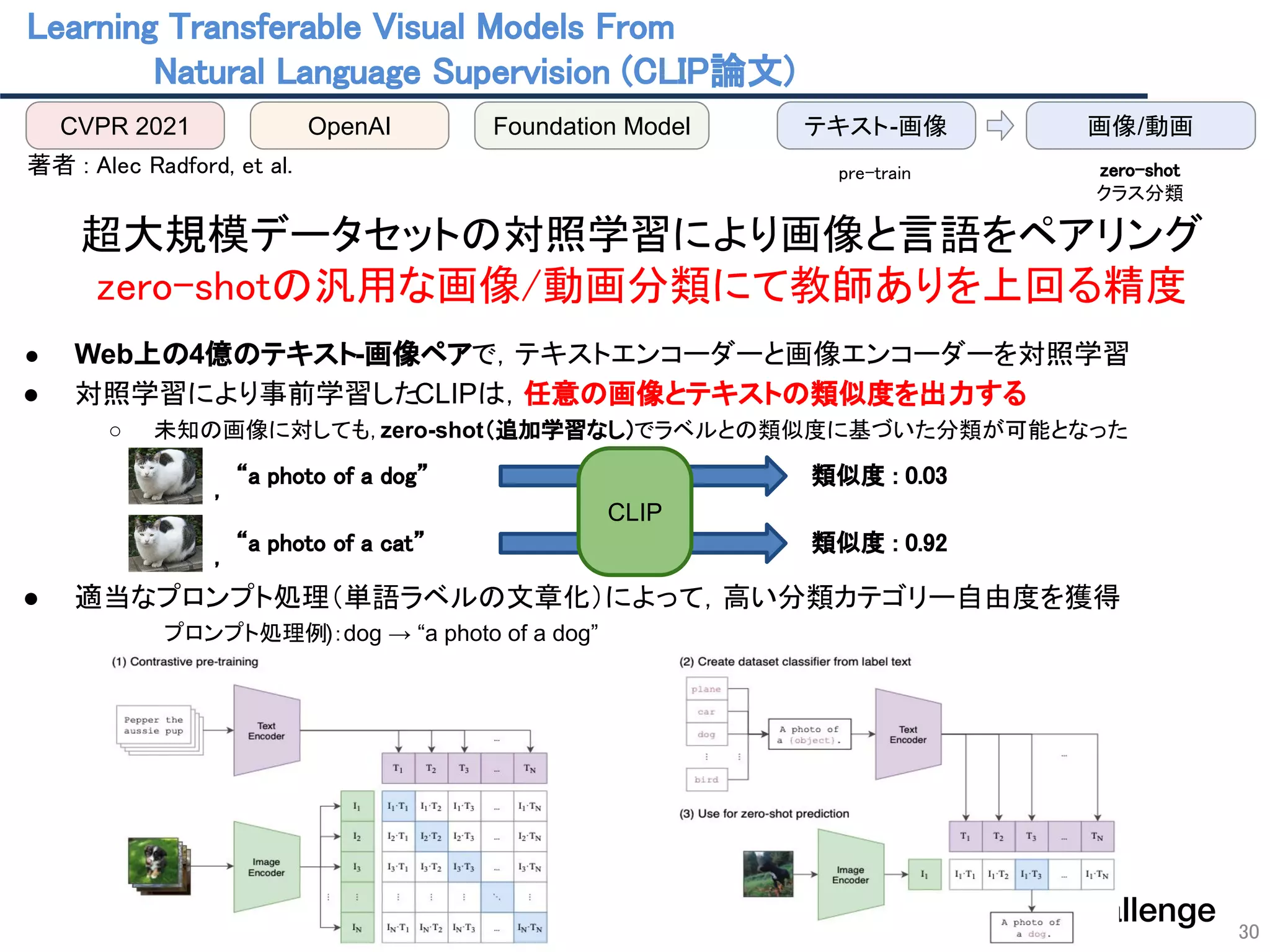
- 30. Learning Transferable Visual Models From Natural Language Supervision (CLIP論文) 30 著者 : Alec Radford, et al. 超大規模データセットの対照学習により画像と言語をペアリング zero-shotの汎用な画像/動画分類にて教師ありを上回る精度 ● Web上の4億のテキスト-画像ペアで,テキストエンコーダーと画像エンコーダーを対照学習 ● 対照学習により事前学習したCLIPは,任意の画像とテキストの類似度を出力する ○ 未知の画像に対しても,zero-shot(追加学習なし)でラベルとの類似度に基づいた分類が可能となった ● 適当なプロンプト処理(単語ラベルの文章化)によって,高い分類カテゴリー自由度を獲得 プロンプト処理例):dog → “a photo of a dog” CVPR 2021 OpenAI Foundation Model 画像/動画 テキスト-画像 pre-train zero-shot クラス分類 , “a photo of a dog” , “a photo of a cat” CLIP 類似度 : 0.03 類似度 : 0.92
- 31. 31 言語を媒介として視覚的情報の本質理解を目指す “Vision and Language”の基盤モデル CLIPは言語を介して画像の意味を捉えるレンズ ● 従来の画像エンコーダーのように 「そのものに意味がない記号(ラベル)」によって画像を捉えるのではなく, 「そのものに意味がある言語表現」によって画像を捉える ため,より解像度の高い自然な画像理解を達成し得る 従来の 画像分類で 事前学習 CLIPで 事前学習 “白と黒のぶち猫が 座ってこちらを見ている ” Class: 3 CLIP [Radford(OpenAI)+, CVPR21] 画像分類 テキストからの 画像生成 画像自動 キャプショニング 物体検出 VQA 視覚言語 ナビゲーション 画像キャプション 妥当性評価 NeRFによる シーン生成 他モダリティ 拡張 多種多様な画像認識タスク, Vision and Languageタスク への応用が可能
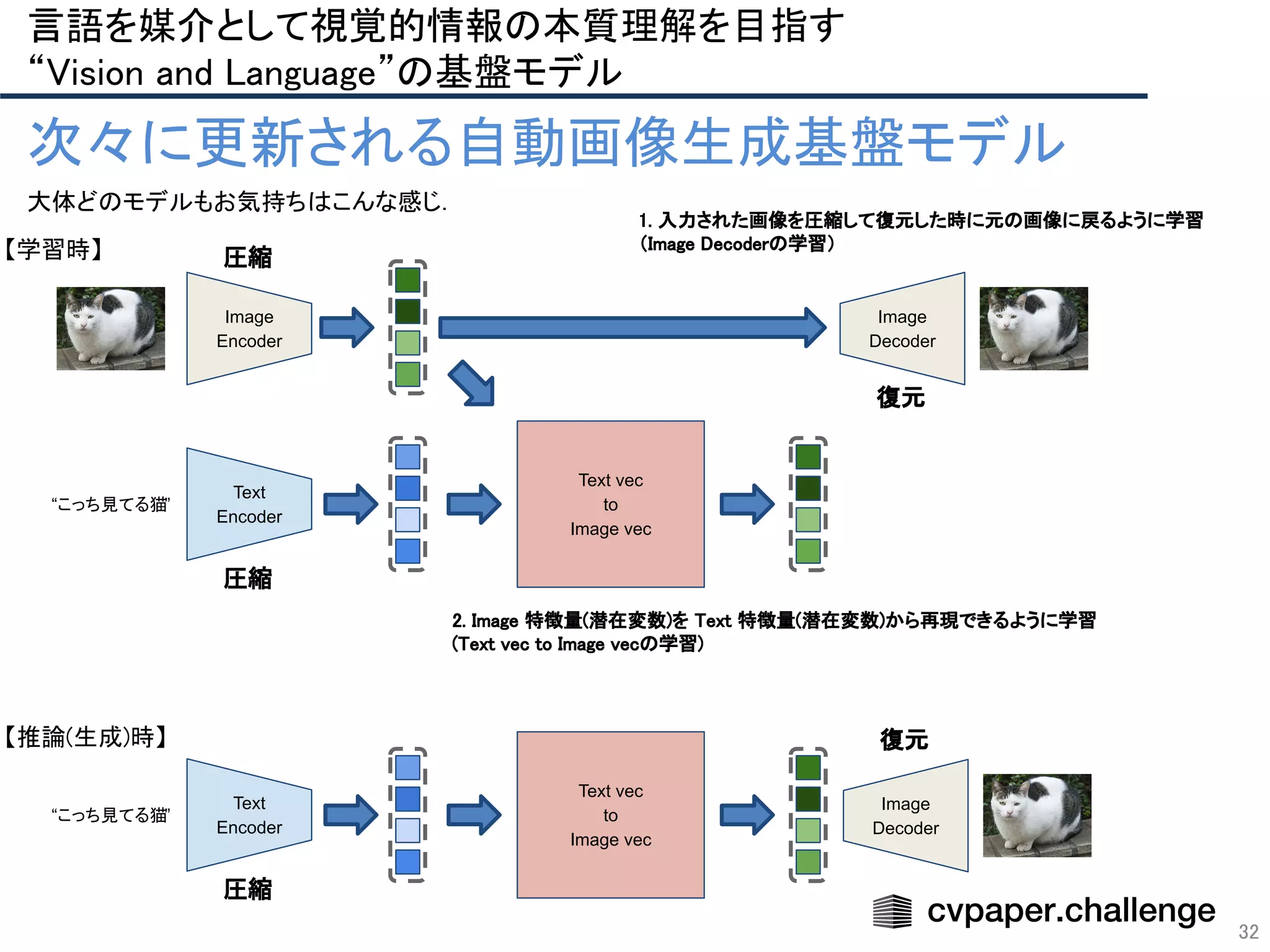
- 32. 32 言語を媒介として視覚的情報の本質理解を目指す “Vision and Language”の基盤モデル 次々に更新される自動画像生成基盤モデル Image Encoder “こっち見てる猫” Text Encoder 大体どのモデルもお気持ちはこんな感じ. 【学習時】 Text vec to Image vec Image Decoder 圧縮 復元 圧縮 2. Image 特徴量(潜在変数)を Text 特徴量(潜在変数)から再現できるように学習 (Text vec to Image vecの学習) 1. 入力された画像を圧縮して復元した時に元の画像に戻るように学習 (Image Decoderの学習) 【推論(生成)時】 “こっち見てる猫” Text Encoder Text vec to Image vec Image Decoder 復元 圧縮
- 33. 33 言語を媒介として視覚的情報の本質理解を目指す “Vision and Language”の基盤モデル 次々に更新される文章から画像生成する基盤モデル ● DALL•E [Ramesh(OpenAI)+, ICML21] ● CLIDE [Nichol(OpenAI)+, ACL22] ● VQGAN-CLIP [Crowson(EleutherAI)+, arXiv22] 大体どのモデルも生成時のお気持ちはこんな感じ. “こっち見てる白黒ぶち猫 ” Text Encoder 復元 圧縮 テキストから潜在表現を獲得するブロック (Text Encoder) テキストの潜在表現から画像を生成するブロック (Image Generator) 基盤モデル間で異なる主な要素は, ● Text Encoder に何を使うか ● Image Generator に何を使うか ● DALL•E 2 [Ramesh(OpenAI)+, arXiv22] ● Imagen [Saharia(Google)+, arXiv22] ● Parti [Yu(Google)+, arXiv22] etc…
- 34. 34 言語を媒介として視覚的情報の本質理解を目指す “Vision and Language”の基盤モデル Text Encoder Image Generator DALL•E GLIDE VQGAN-CLIP DALL•E 2 Imagen Parti BPE VQ-VAE + Transformer(GPT-3 like) VQGAN + CLIP CLIP DDPM + Classsifier-free Guidance Transformer DDPM + Classsifier-free Guidance + CLIP T5-XXL DDPM + Classsifier-free Guidance ViT-VQGAN + Classsifier-free Guidance + Transformer SentencePiece model CLIP VQ-VAE(Vector Quantised-Variational AutoEncoder): 潜在変数を離散的なベクトルとして持たせて学習させ、複合して 画像を生成するモデル,オートエンコーダー VQGAN: VQ-VAEの進化系で,以下の点で異なる. - PixelCNNの代わりにTransformerを導入し広い視野獲得 - GANの併用により,精度保ったまま Patchの解像度を圧縮可能に DDPM(拡散確率モデル) : ソース画像に複数回ノイズを加え (forward process), 最終的にノイズのみになるガウス確率過程を考え, その逆過程を学習して遡ることで (reverse process), 完全なノイズから画像の生成を行う. VQ-VAE [Oord(DeepMind)+, NeurIPS17] VQGAN [Esser(HCIP)+, CVPR21] Denoising Diffusion Probabilistic Model [Ho(UC Berkeley)+, NeurIPS20] 基本的に下に行くほど 新しく性能の高い アーキテクチャ 次々に更新される文章から画像生成する基盤モデル
- 35. Zero-Shot Text-to-Image Generation (DALL·E論文) 35 著者 : Aditya Ramesh, et al. VQ-VAE(dVAE) + Transformer(120億パラメータ)の構成で 約2.5億のテキスト-画像ペアで事前学習させ, テキストから完成度の高い画像を自動生成 ● VQ-VAEによって256×256のRGB画像を32×32(=1024)の画像トークンに変換(encode) ● BPE圧縮によってキャプションを256のテキストトークンに変換(encode) ● 上記のトークンをconcatしてembedding,Sparse Transformerを用いて各潜在変数を学習 ● 画像生成時はTransformerで潜在変数を予測し,VQ-VAEによって画像を復元(decode) ○ CLIPによって入力テキストとの類似度でランキングして出力 ● MS-COCOにおいて,zero-shotで既存手法に匹敵するFIDスコア達成 ● 人間による評価実験において, 既存手法(DF-GAN)と比較してよりリアルで入力テキスト通りの画像を生成 ICML 2021 OpenAI 画像生成 テキスト-画像 pre-train zero-shot text to image Foundation Model
- 36. VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance 36 著者 : Katherine Crowson et al. ● 複雑な文章をもとにした画像生成システム ● CLIPを用いてテキスト・画像ペアの類似性を評価する損失関数を定義し、画像生成の潜在空間を更新すること で画像を生成 ● 実行時間はやや遅い(イテレーション回数が多い)が学習コストが不要 GitHub https://github.com/eleutherai/vqgan-clip Kaggle https://www.kaggle.com/code/basu369vi ctor/playing-with-vqgan-clip/notebook arXiv 2022 EleutherAI 画像生成 テキスト-画像 pre-train zero-shot text to image Foundation Model
- 37. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models 37 著者 : Alex Nichol, et al. テキストからの画像生成タスクにおいて DALL-Eよりリアルであると評価された“GLIDE” ● パラメータ数35億+15億の誘導拡散モデルGLIDEを提案 ● GLIDEを2種類の誘導方法からテキスト条件付き画像生成を行い比較 ○ CLIP guidance:CLIP(ViT-L)の潜在空間の類似度を利用(classifierの知識を活用) ○ classifier-free guidance:確率的に条件付けを除外し分類も同時学習( classifier不要) ● 比較の結果classifier-free guidanceの方が本物らしさとキャプション類似性について優位 ● 独自フィルタによって生成画像の悪用を防止 ● サンプリングがGANよりも大幅に遅いのがネック ACL 2022 OpenAI 画像生成 テキスト-画像 pre-train zero-shot text to image Foundation Model
- 38. Hierarchical Text-Conditional Image Generation with CLIP Latents (DALL·E 2 論文) 38 著者 : Aditya Ramesh, et al. DDPM + CLIPで 約6.4億のテキスト-画像ペアで事前学習し, GLIDEと比較してより多様性のある画像を生成 ● 事前分布(prior)として拡散モデルを用いる ○ テキストからCLIP画像埋め込みを生成.自己回帰モデルも試したが拡散モデルの方が良い結果に ● デコーダとしてGLIDEとほぼ同じ35億パラメータの拡散確率モデルを用いる ○ CLIP画像埋め込みから画像を生成. GLIDEと同様にclassifier-free guidanceを使用 →unCLIPと総称 arXiv (2022) OpenAI 画像生成 テキスト-画像 pre-train zero-shot text to image Foundation Model
- 39. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (Imagen 論文) 39 著者 : Chitwan Saharia, et al. ● テキストのみを事前学習し凍結させた大規模言語モデル(T5-XLL)が画像生成に有効 ● DDPMをスケーリングするよりも,大規模言語モデルを拡張する方が効く ● DDPMは計約8.6億のテキスト-画像ペアで事前学習 ● Efficient U-Netを導入し,計算効率・メモリ効率を向上させ,学習時間を短縮 COCOのFID指標においてDALLE•2を超える性能 arXiv (2022) Google 画像生成 テキスト-画像 pre-train zero-shot text to image Foundation Model
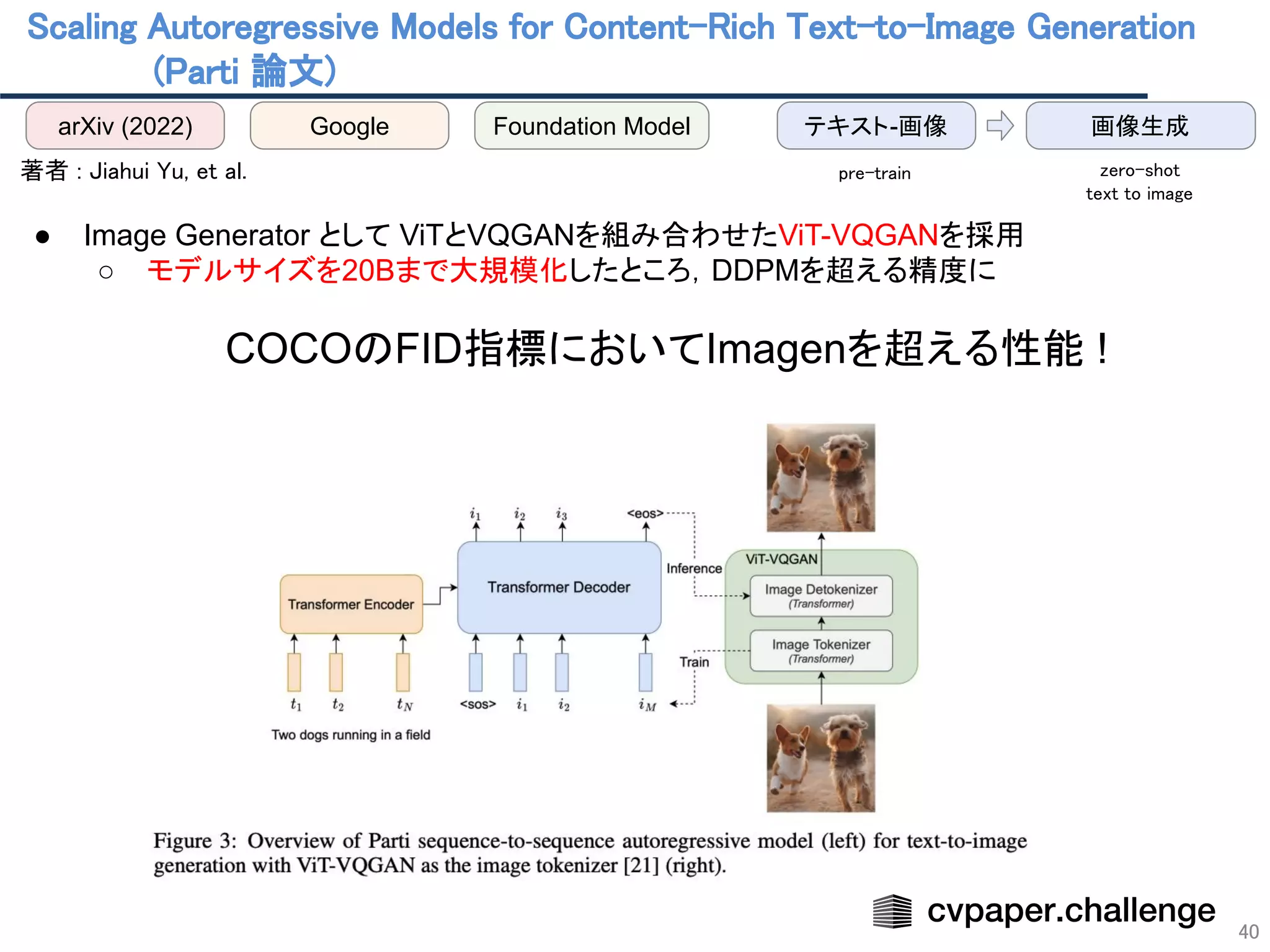
- 40. Scaling Autoregressive Models for Content-Rich Text-to-Image Generation (Parti 論文) 40 arXiv (2022) Google 画像生成 テキスト-画像 pre-train zero-shot text to image Foundation Model 著者 : Jiahui Yu, et al. ● Image Generator として ViTとVQGANを組み合わせたViT-VQGANを採用 ○ モデルサイズを20Bまで大規模化したところ,DDPMを超える精度に COCOのFID指標においてImagenを超える性能 !
- 41. 41 言語を媒介として視覚的情報の本質理解を目指す “Vision and Language”の基盤モデル 多種多様なVisionタスクを 言語を介して解く基盤モデル Flamingo [Alayac(DeepMind)+, arXiv22] Florence [Lu Yuan(Microsoft)+, arXiv21]
- 42. NU¨ WA: Visual Synthesis Pre-training for Neural visUal World creAtion 42 著者 : Chenfei Wu, et al. 画像・動画・テキストを同時に学習することで 様々な視覚的生成/補完タスクにおいてSOTAを達成 ● 3D Transformer encoder-decoder Frameworkにより画像・動画・テキストを同時に学習 3D Nearby Attentionによって,空間軸と時間軸の双方の局所性を考慮しつつ計算量を削減 ● 290万の画像-テキストペア,24万の動画-テキストペア,72万の動画データで事前学習 ○ A-100 GPU × 64台 × 2週間 ● 8つの視覚的な合成タスクにおいて高水準な精度,特に TtoI/TtoV/VtoVでSOTAを達成 arXiv (2021) Microsoft (with Peking University) Foundation Model テキスト/画像/動画 言語/画像/動画 zero/few-shot 生成タスクが主 pre-train
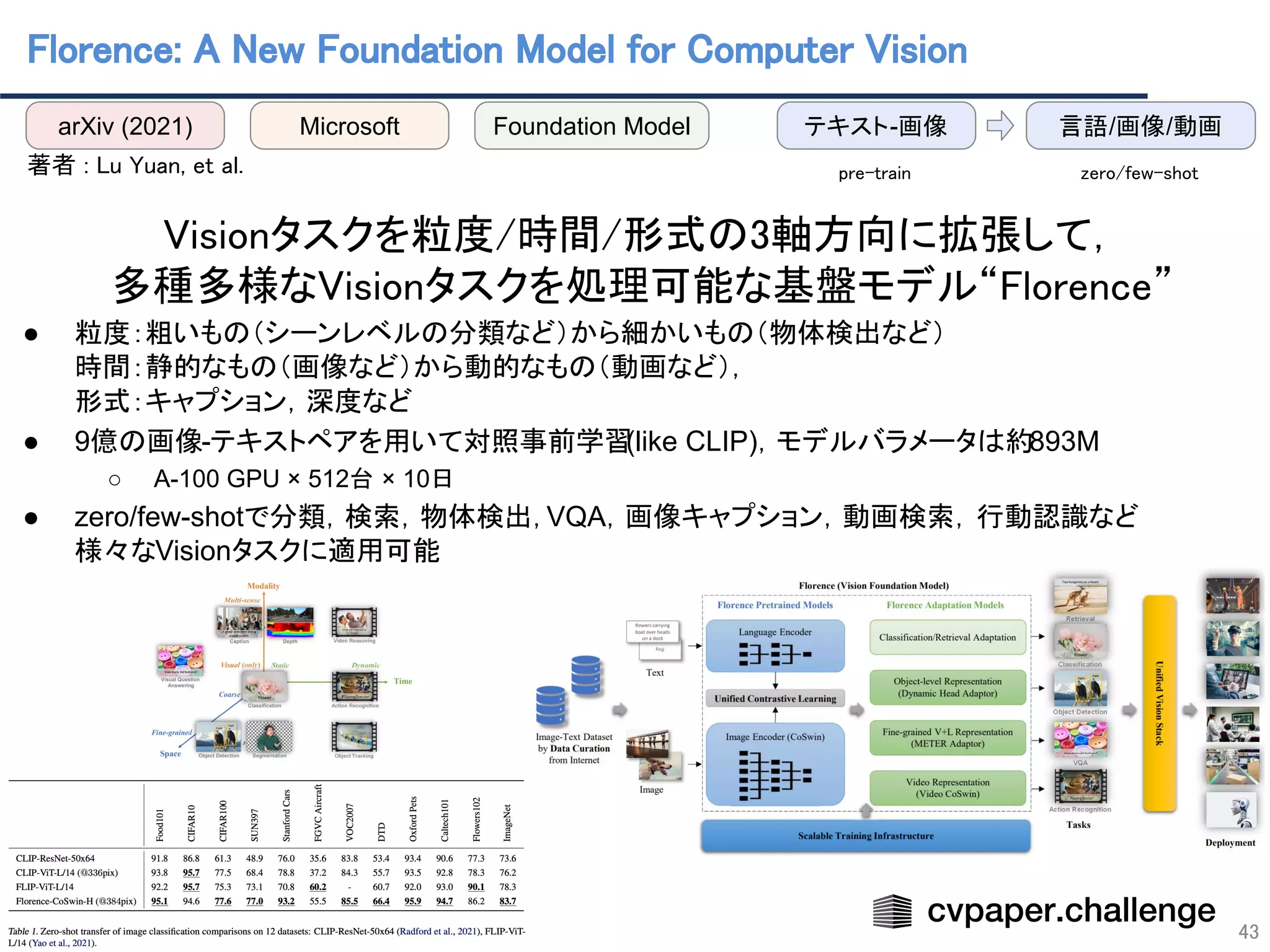
- 43. Florence: A New Foundation Model for Computer Vision 43 著者 : Lu Yuan, et al. Visionタスクを粒度/時間/形式の3軸方向に拡張して, 多種多様なVisionタスクを処理可能な基盤モデル“Florence” ● 粒度:粗いもの(シーンレベルの分類など)から細かいもの(物体検出など) 時間:静的なもの(画像など)から動的なもの(動画など), 形式:キャプション,深度など ● 9億の画像-テキストペアを用いて対照事前学習 (like CLIP),モデルバラメータは約893M ○ A-100 GPU × 512台 × 10日 ● zero/few-shotで分類,検索,物体検出,VQA,画像キャプション,動画検索,行動認識など 様々なVisionタスクに適用可能 arXiv (2021) Microsoft Foundation Model 言語/画像/動画 テキスト-画像 pre-train zero/few-shot
- 44. Flamingo: a Visual Language Model for Few-Shot Learning 44 著者 : Jean-Baptiste Alayrac, et al. 画像とテキストを入力してテキストを生成するタスク全般 をfew-shotで高精度に実現し,6/16タスクでSoTA ● 70B(PT済みchinchilla)+10Bのtext encoderとCLIPベースのimage encoderが土台 ● PerceiverをベースとしたResamplerで,動画などのマルチモーダルにも対応 ● ベースラインのわずか1/1000程度のみのサンプル提示で, VQAなどの6/16のtext-imageマルチモーダルタスクでSoTA達成 ○ FIne-Tuningを行うと,更に5つのベンチマークでSoTA達成 arXiv (2022) DeepMind Foundation Model 言語(from 動画像) テキスト-画像 pre-train zero/few-shot
- 45. From Transformer to Vision FMs 45 Transformer → Vision FMs 3つのポイント ● 複数モダリティ・単一モデル ● 画像・言語・音声を一つのTransformerモデルで扱える ● 同時に扱えるモダリティは増加傾向 ● モデル・データのサイズ増加 ● データ:数億〜数十億規模(e.g., WebImageText(400M), JFT-4B) ● モデル:百億パラメータ規模(言語だと数兆とかもっと多い) (e.g.,Flamingo, Parti) ● ラベルなしデータで事前学習 ● 自己教師あり学習の台頭 ● マルチモーダルの教師なし学習 ●
- 46. アジェンダ 46 1. イントロダクション+論文サマリ Foundation Modelsの概観について, 具体的な例を論文サマリとして提示しつつ説明 1.1. 基盤モデルとは? 1.2. Transformerの誕生と発展 1.3. ViTによるVisionへのモダリティシフト 1.4. マルチモーダルな基盤モデルの台頭 2. メタサーベイ 全体を俯瞰してFoundation Modelsの動向をまとめる
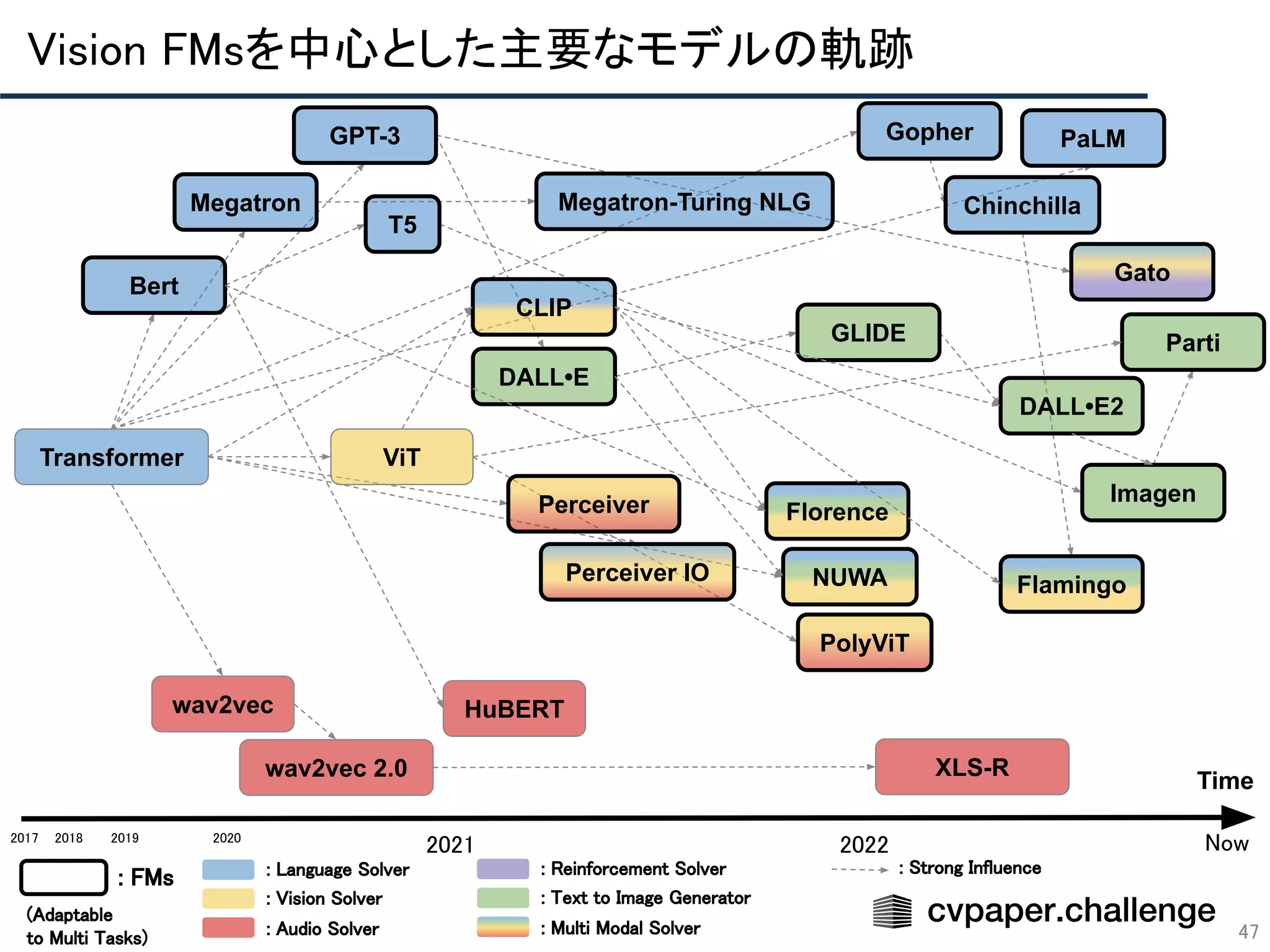
- 47. Vision FMsを中心とした主要なモデルの軌跡 47 Time 2018 2019 2020 2021 2022 Transformer Bert PolyViT Florence CLIP ViT NUWA Perceiver GPT-3 PaLM Perceiver IO Gato DALL•E DALL•E2 GLIDE Imagen Parti Megatron wav2vec wav2vec 2.0 XLS-R Gopher 2017 : FMs : Language Solver : Vision Solver : Audio Solver : Reinforcement Solver : Text to Image Generator : Multi Modal Solver (Adaptable to Multi Tasks) Now HuBERT Megatron-Turing NLG T5 : Strong Influence Flamingo Chinchilla
- 48. マルチモダリティ/マルチタスク化の促進 48 複数モダリティでのデータ入力が可能 ○ あらゆるデータをtokenizeしてTransformerで処理 →各分野のタスクを基盤モデルによる学習で統合 Visionに限らずあらゆるモダリティを基盤モデルによって 統一的に学習できるようになる(かも) PolyViT [Likhosherstov(Google)+, ICLR22] Gato [Reed(DeepMind)+, arXiv22] 入力形式:テキスト,画像,音声,動画,数値,… 分野:言語処理,画像認識,音声認識,行動認識,…
- 49. Foundation Modelsのスケーリング則 49 スケーリング則(Scaling Law) ● モデルパラメータサイズ ● 事前学習データセットサイズ ● 計算予算 の3要素を同時にスケーリングすると性能が際限なく向上していく, という仮説 Scaling Vision Transformers [Zhai+, CVPR22] GPT-3 [Brown+, NeurIPS22]
- 50. 50 Time 2018 2019 2020 2021 2022 Transformer Bert PolyViT Florence CLIP ViT NUWA Perceiver GPT-3 PaLM Perceiver IO Gato DALL•E DALL•E2 GLIDE Imagen Parti Megatron wav2vec wav2vec 2.0 XLS-R Gopher 2017 Now HuBERT Megatron-Turing NLG T5 Flamingo Chinchilla 主要FMsのモデルパラメータサイズ 223M 345M 8.3B 530B 175B 11B 280B 540B 20B 632M 12B 425M 42.1M 5B 637M 870M 178M 1.2B 317M 1B 2B 80B 70B 400M 5.5B 7.6B 全てのモダリティにおいて増大傾向 増大数は,Language>Vision>Audio
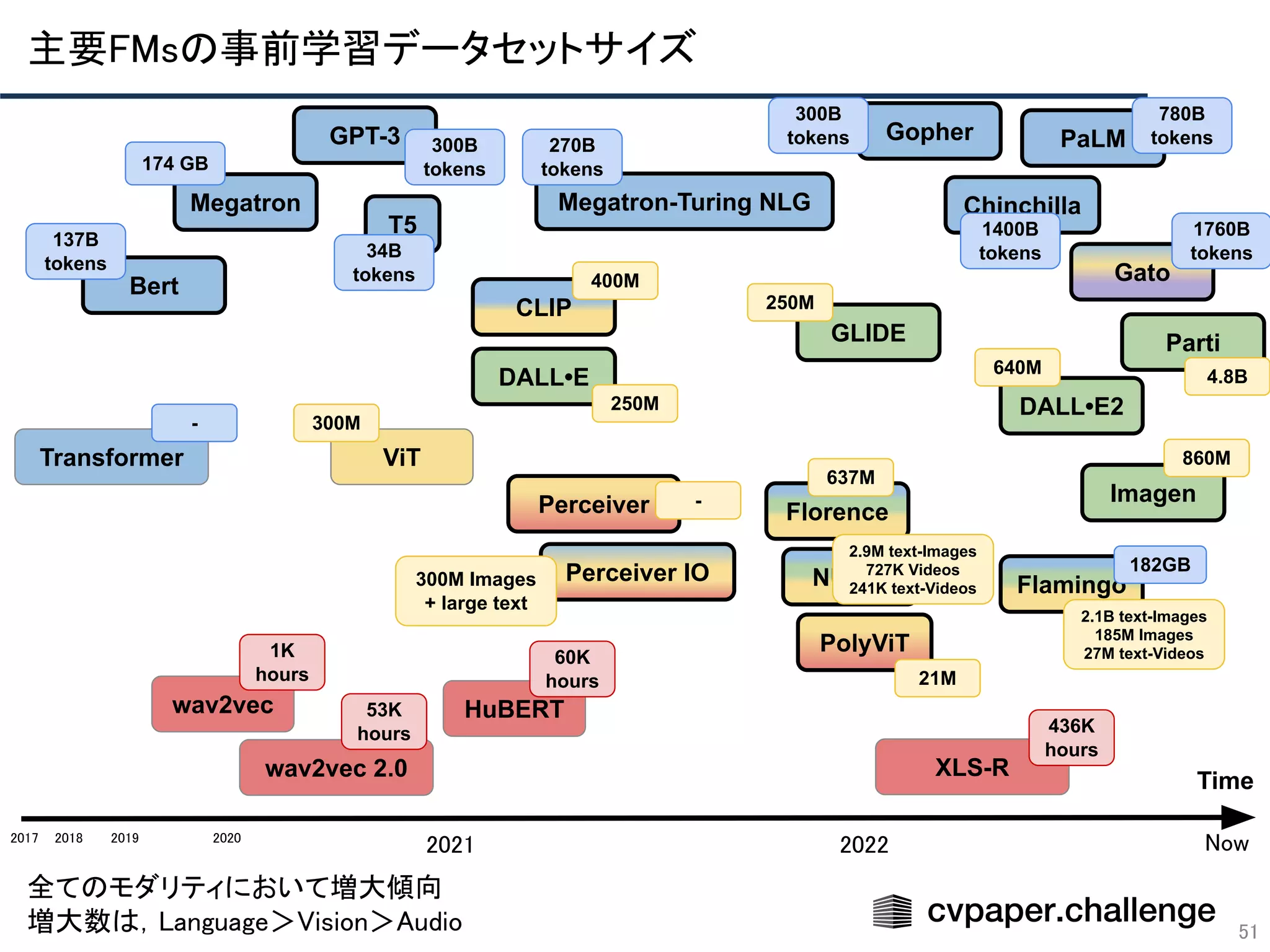
- 51. 51 Time 2018 2019 2020 2021 2022 Transformer Bert PolyViT Florence CLIP ViT NUWA Perceiver GPT-3 PaLM Perceiver IO Gato DALL•E DALL•E2 GLIDE Imagen Parti Megatron wav2vec wav2vec 2.0 XLS-R Gopher 2017 Now HuBERT Megatron-Turing NLG T5 Flamingo Chinchilla 全てのモダリティにおいて増大傾向 増大数は,Language>Vision>Audio 主要FMsの事前学習データセットサイズ 4.8B - 637M 21M 400M 860M 640M 250M 250M 300M 300M Images + large text 2.9M text-Images 727K Videos 241K text-Videos 436K hours 1760B tokens 2.1B text-Images 185M Images 27M text-Videos 182GB 1K hours 300B tokens - 53K hours 60K hours 780B tokens 1400B tokens 270B tokens 300B tokens 34B tokens 137B tokens 174 GB
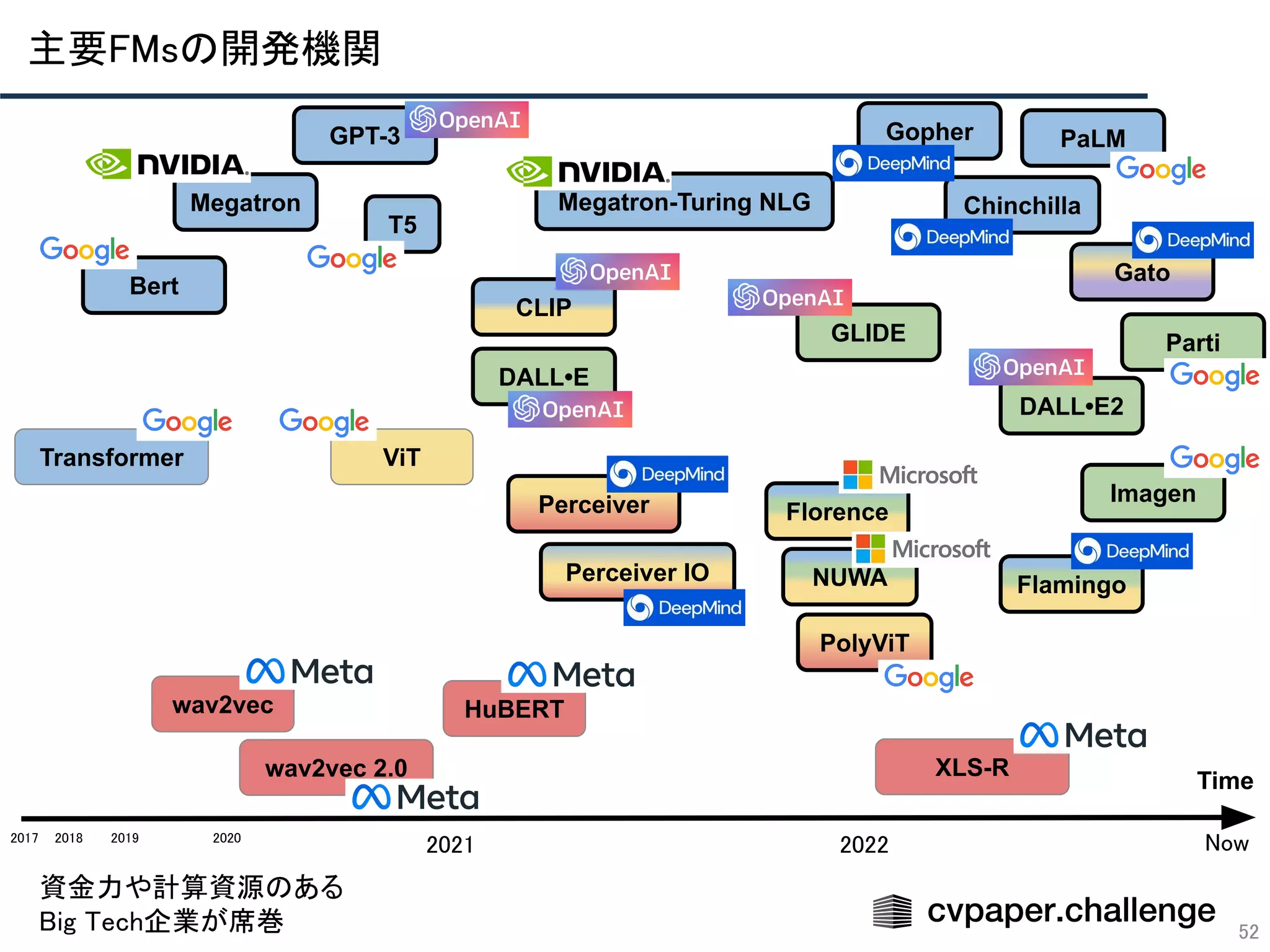
- 52. 52 Time 2018 2019 2020 2021 2022 Transformer Bert PolyViT Florence CLIP ViT NUWA Perceiver GPT-3 PaLM Perceiver IO Gato DALL•E DALL•E2 GLIDE Imagen Parti Megatron wav2vec wav2vec 2.0 XLS-R Gopher 2017 Now HuBERT Megatron-Turing NLG T5 Flamingo Chinchilla 主要FMsの開発機関 資金力や計算資源のある Big Tech企業が席巻
- 54. 54 “思考停止”のスケーリングは資源の枯渇を招く ○ スケーリングを行う過程では データ効率,パラメータ効率,計算効率 の追求が必須(ただ各要素をデカくするだけではダメ) スケーリング則が基盤モデル研究に与えるリスク An empirical analysis of compute-optimal large language model training (chinchilla [Hoffmann(DeepMind)+, arXiv22]のプロジェクトページ )より https://medium.com/@thepathtochange/maybe-microsoft-s-tay-ai-didn-t-have-a-meltdown-4291b910a37c DeepMindがchinchillaの発表に伴い, 最近の言語基盤モデルが,モデルパラメータを大きくしすぎて 学習データ不足による精度劣化を引き起こしている ことを指摘
- 55. 55 学習データの権利・倫理関係問題 ○ Web上の大量データで学習→含むバイアスも大量 特定の集団に対して不公平/有害な出力を招くリスク Maybe Microsoft’s Tay AI didn’t have a meltdown… https://medium.com/@thepathtochange/maybe-microsoft-s-tay-ai-didn-t-have-a-meltdown-4291b9 10a37c Google's Artificial Intelligence Hate Speech Detector Is 'Racially Biased,' Study Finds https://www.forbes.com/sites/nicolemartin1/2019/08/13/googles-artificial-intelligence-hate-s peech-detector-is-racially-biased/#1418e6d8326c スケーリング則が基盤モデル研究に与えるリスク 近年の基盤モデルでは, 出力されるバイアスも評価観点として重視傾向
- 56. 56 JFT-300M/3B/4B (Google, 2017/2021/2022) →約3億/30億/40億枚の画像データセット IG-3.5B (Facebook, 2018) →約35億枚の画像データセット スケーリング則が基盤モデル研究に与えるリスク 巨大Tech企業による大規模データセット寡占化 ○ 独自に保有するプラットフォームで 非公開な超大規模データを収集し利用 Parti [Yu(Google)+, arXiv22] プライバシーの問題や誤用の懸念がある以上, 容易に公開はできず難しい問題
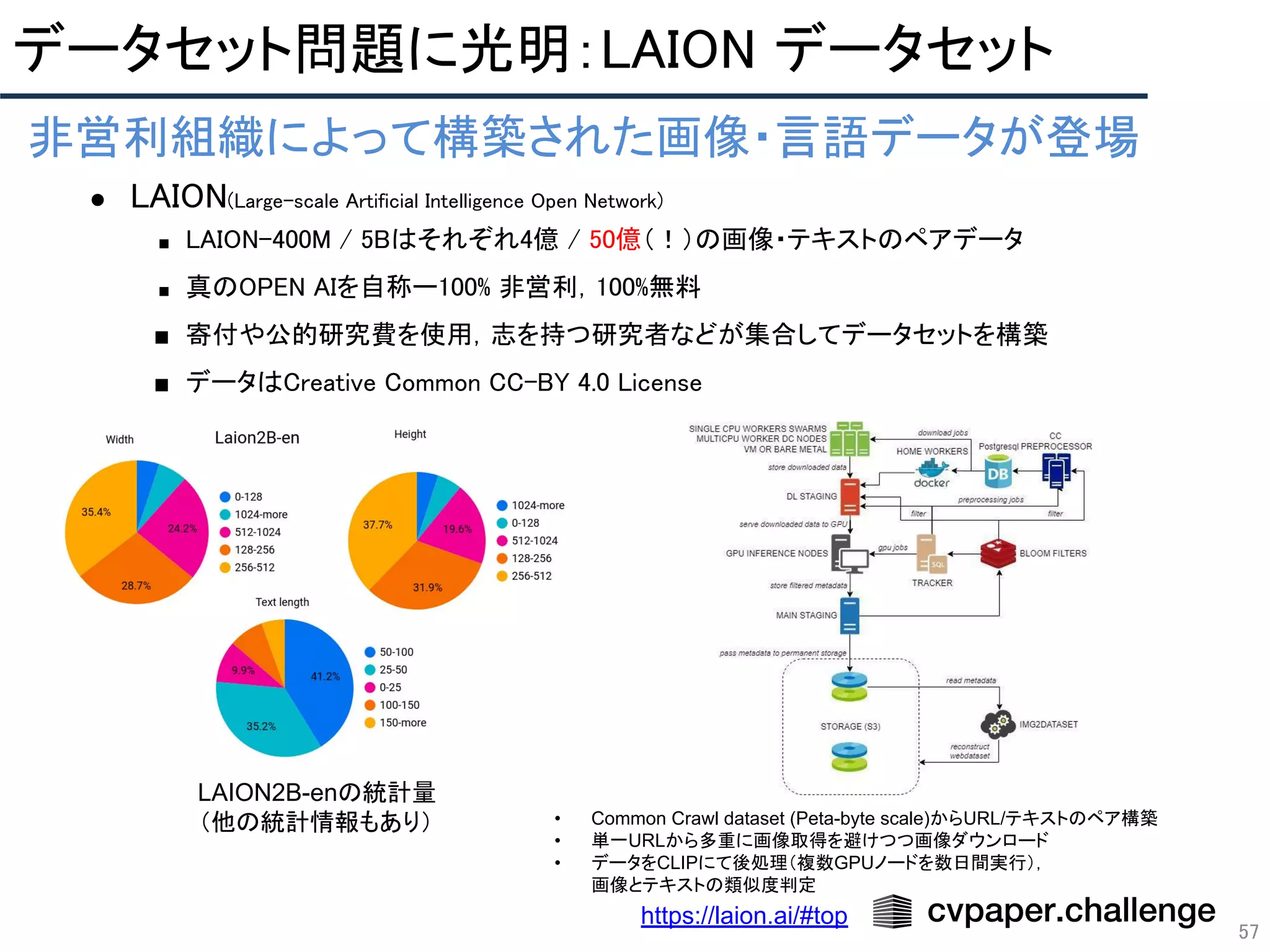
- 57. 57 非営利組織によって構築された画像・言語データが登場 ● LAION(Large-scale Artificial Intelligence Open Network) ■ LAION-400M / 5Bはそれぞれ4億 / 50億(!)の画像・テキストのペアデータ ■ 真のOPEN AIを自称ー100% 非営利,100%無料 ■ 寄付や公的研究費を使用,志を持つ研究者などが集合してデータセットを構築 ■ データはCreative Common CC-BY 4.0 License https://laion.ai/#top LAION2B-enの統計量 (他の統計情報もあり) • Common Crawl dataset (Peta-byte scale)からURL/テキストのペア構築 • 単一URLから多重に画像取得を避けつつ画像ダウンロード • データをCLIPにて後処理(複数GPUノードを数日間実行), 画像とテキストの類似度判定 データセット問題に光明:LAION データセット
- 58. Center for Research on Foundation Models (CRFM) 58 Percy Liang率いるStanford ● HAIから分岐してStanford大学内に2021年に発足 ● Foundation Model開発に特化した研究機関 ● CSだけでなく10種以上の専門領域から研究者が集結 ● 不用意な大規模化でなく、効率性・堅牢性・ 解釈可能性・倫理的健全性の実現を目指す理論研究 https://crfm.stanford.edu/
- 59. OpenAI 59 https://openai.com/blog/tags/milestones/ AGI実現に向けて最高峰の性能を発揮する 超大規模モデルを次々に発表 ● Scaling Lawに基づきモデルとデータセットの大規模拡張を行い、 最高峰の性能を発揮する基盤モデルを開発 ■ 自然言語タスク:GPT-3など ■ マルチモーダル:DALL•E 2など ● Microsoftと連携し、 膨大な計算資源獲得とプロダクトのサービス化を実現
- 60. Project Florence (AI)- Microsoft 60 https://www.microsoft.com/en-us/research/project/projectflorence/ 科学技術を利用して人類の進化をアシストするミッ ション ● Microsoft AI Cognitive Serviceチームから資金提供 ■ 2020年3月より資金提供開始≒研究開始 ● Florence以外にもCVPR等のTop Conferenceに多数採択
- 61. Adept 61 Transformer ALL STARの共演 ● 汎用的な知能を構築するために設立されたStartup ● Transformer / GPT-2, 3 の研究開発メンバーが在籍することで話題 ● 巨大モデル構築・GPU計算・言語生成・音声認識・データセットなどをコア技 術に持つ研究者・開発者が集合 https://www.adept.ai/post/introducing-adept Adeptの狙うところ? ● 働きかけ(フライトの予約,小切手売買,学術的な実験) ● 読み書きのみではなく,人間に何か有益なことをする ● 安全な汎用的知能の構築 基盤モデルの文脈で今後,巨大IT企業に割って入れるか?
- 63. 基盤モデル研究での今後の重要課題(まとめ) 63 ● 今後の動向 ○ マルチモダリティ/マルチタスク化の促進 ○ 各開発機関による基盤モデル開発競争がヒートアップ ● 解決すべき課題 ● スケーリングのための諸問題対処 ○ スケーリングを行う過程で データ効率,パラメータ効率,計算効率 の追求が必須(ただデカくするだけではダメ) ○ バイアスの排除 ○ オープンでクリーンな研究 ● 可用性の追求 ○ 精度を落とさずに小型化 ○ 説明可能性の確保