





















社内サーバインフラ勉強会(DB)
- 2. 今回の目的 1. 「データを保存する」ということが、実際にど ういうことなのかを知る。 2. 中の動作を踏まえることで、効率のよいアプ リを書けるようになる。 3. 問題が起きたときに、その原因を突き止めら れるようになる。 一般論をメインとし、MySQL等の細かい 個別ノウハウは取り上げません。
- 3. おしながき 1. 「データを保存する」とはどういうことか 2. MySQLがディスクに書くまで 3. 仮想メモリとページキャッシュ 4. とっても複雑なストレージの動作 5. MySQLのインデックスとメモリの関係
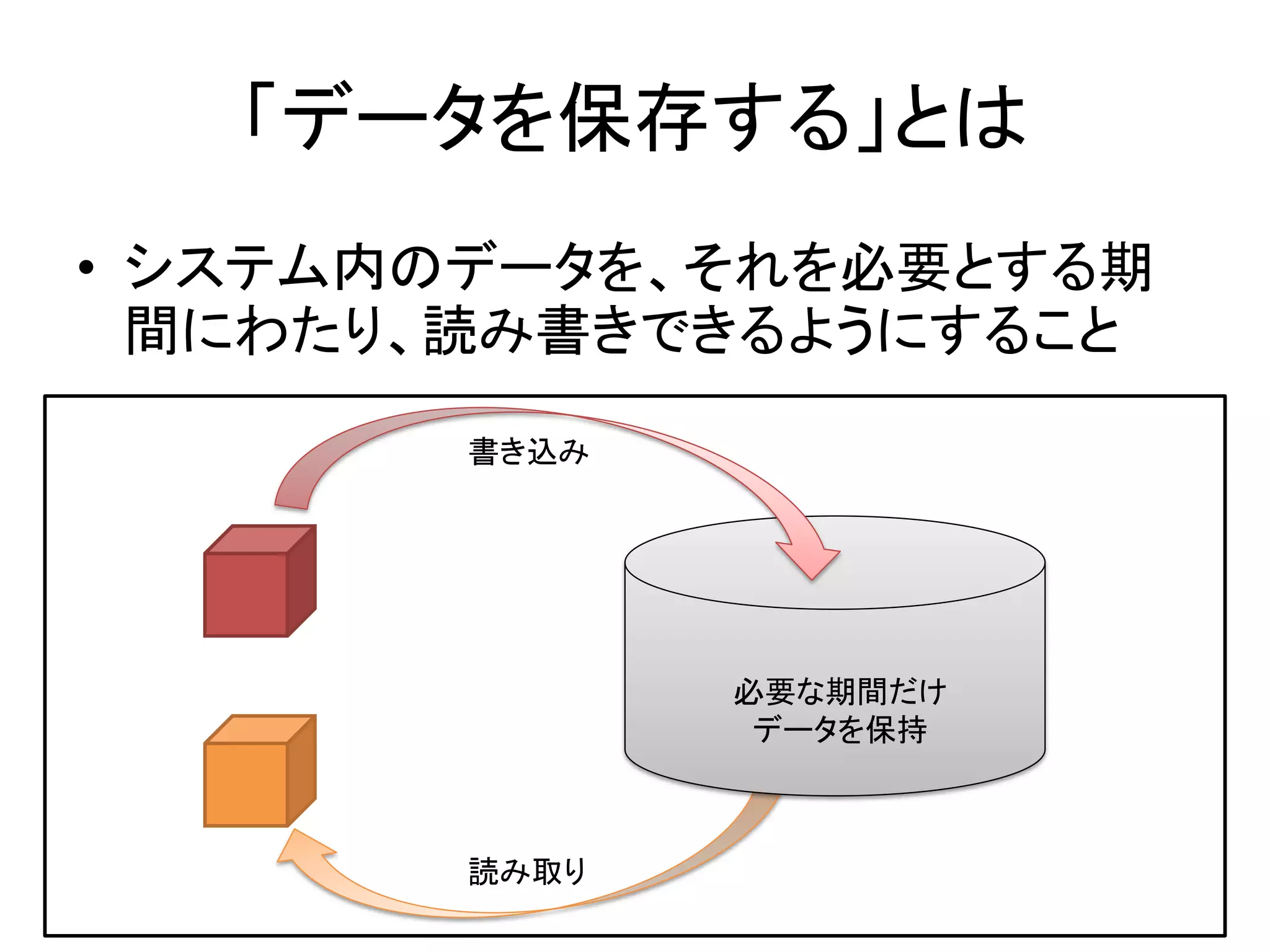
- 4. 「データを保存する」とは • システム内のデータを、それを必要とする期 間にわたり、読み書きできるようにすること 書き込み 必要な期間だけ データを保持 読み取り
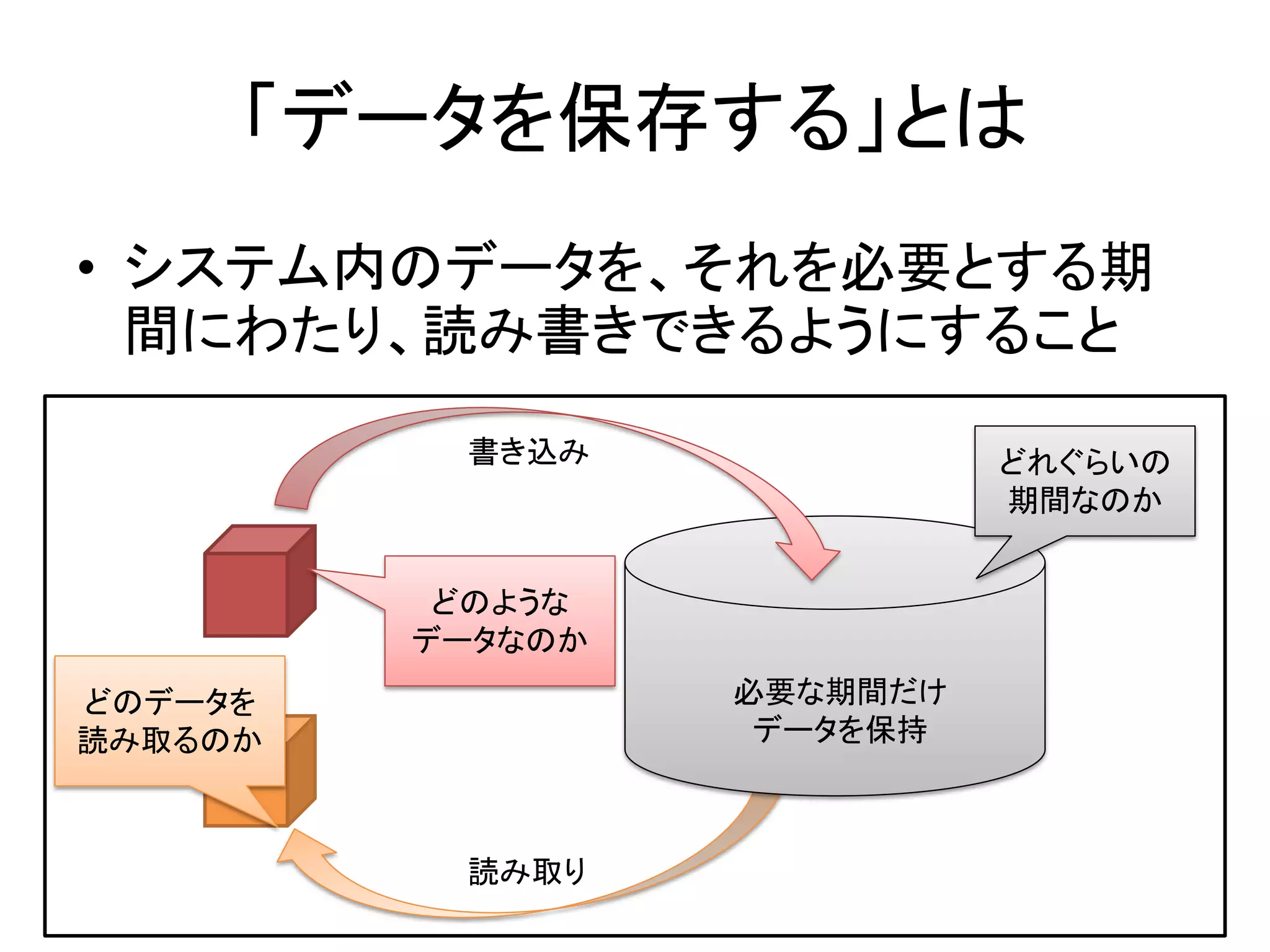
- 5. 「データを保存する」とは • システム内のデータを、それを必要とする期 間にわたり、読み書きできるようにすること 書き込み どれぐらいの 期間なのか どのような データなのか どのデータを 必要な期間だけ 読み取るのか データを保持 読み取り
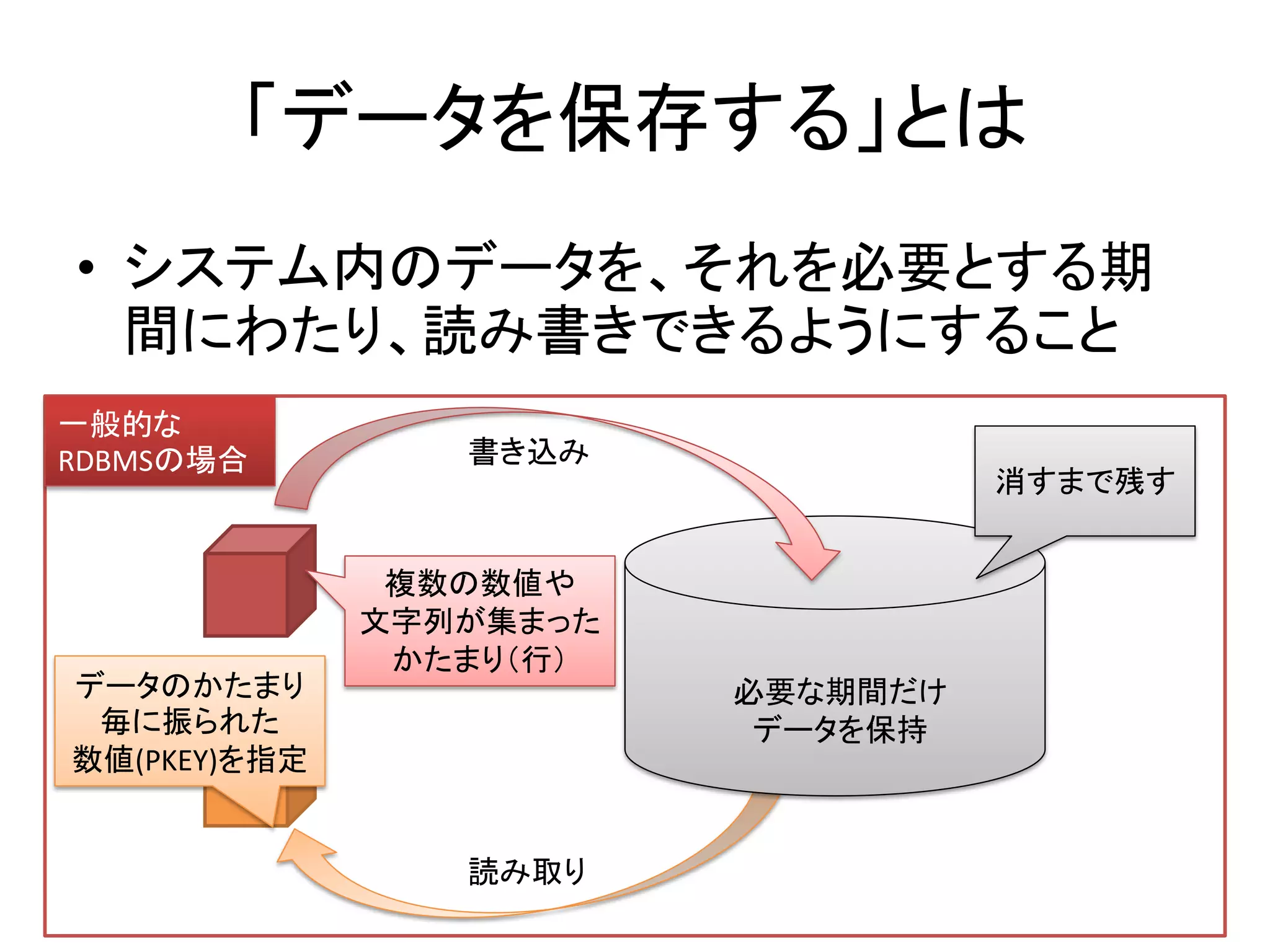
- 6. 「データを保存する」とは • システム内のデータを、それを必要とする期 間にわたり、読み書きできるようにすること 一般的な RDBMSの場合 書き込み 消すまで残す 複数の数値や 文字列が集まった かたまり(行) データのかたまり 必要な期間だけ 毎に振られた データを保持 数値(PKEY)を指定 読み取り
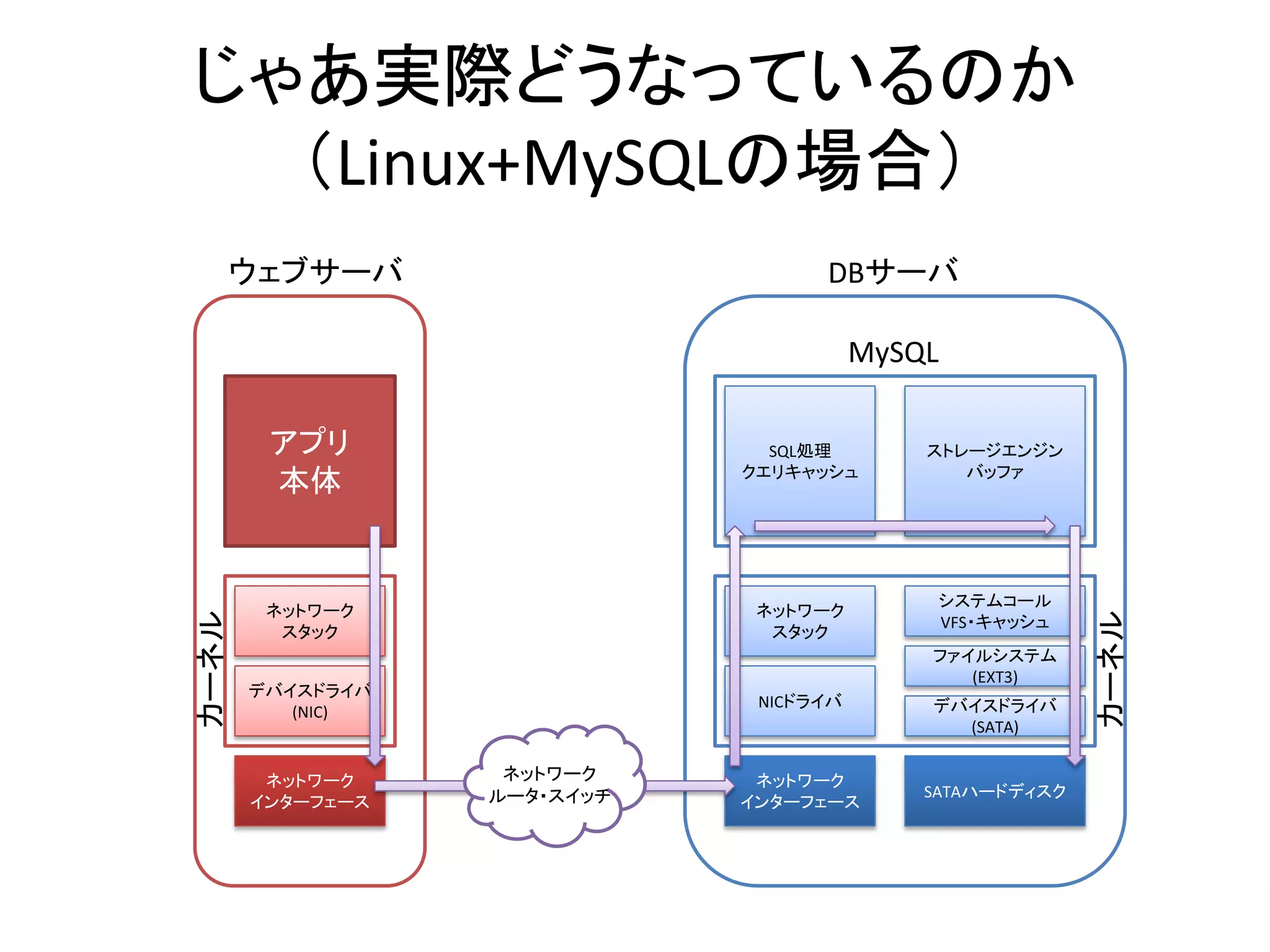
- 7. じゃあ実際どうなっているのか (Linux+MySQLの場合) ウェブサーバ DBサーバ MySQL アプリ SQL処理 ストレージエンジン クエリキャッシュ バッファ 本体 システムコール ネットワーク ネットワーク カーネル カーネル VFS・キャッシュ スタック スタック ファイルシステム (EXT3) デバイスドライバ NICドライバ デバイスドライバ (NIC) (SATA) ネットワーク ネットワーク ネットワーク ルータ・スイッチ SATAハードディスク インターフェース インターフェース
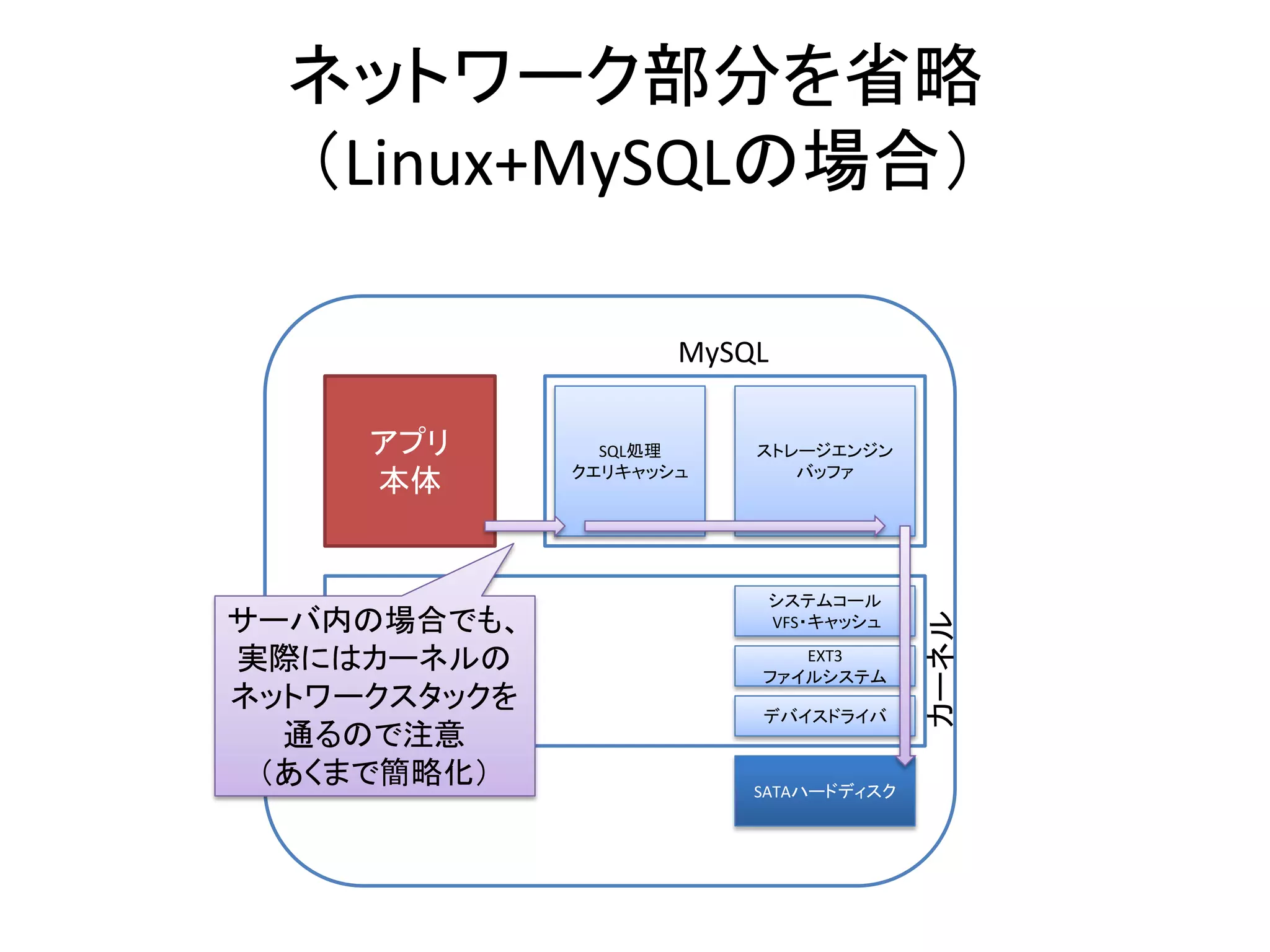
- 8. ネットワーク部分を省略 (Linux+MySQLの場合) MySQL アプリ SQL処理 ストレージエンジン クエリキャッシュ バッファ 本体 システムコール サーバ内の場合でも、 カーネル VFS・キャッシュ 実際にはカーネルの EXT3 ファイルシステム ネットワークスタックを デバイスドライバ 通るので注意 (あくまで簡略化) SATAハードディスク
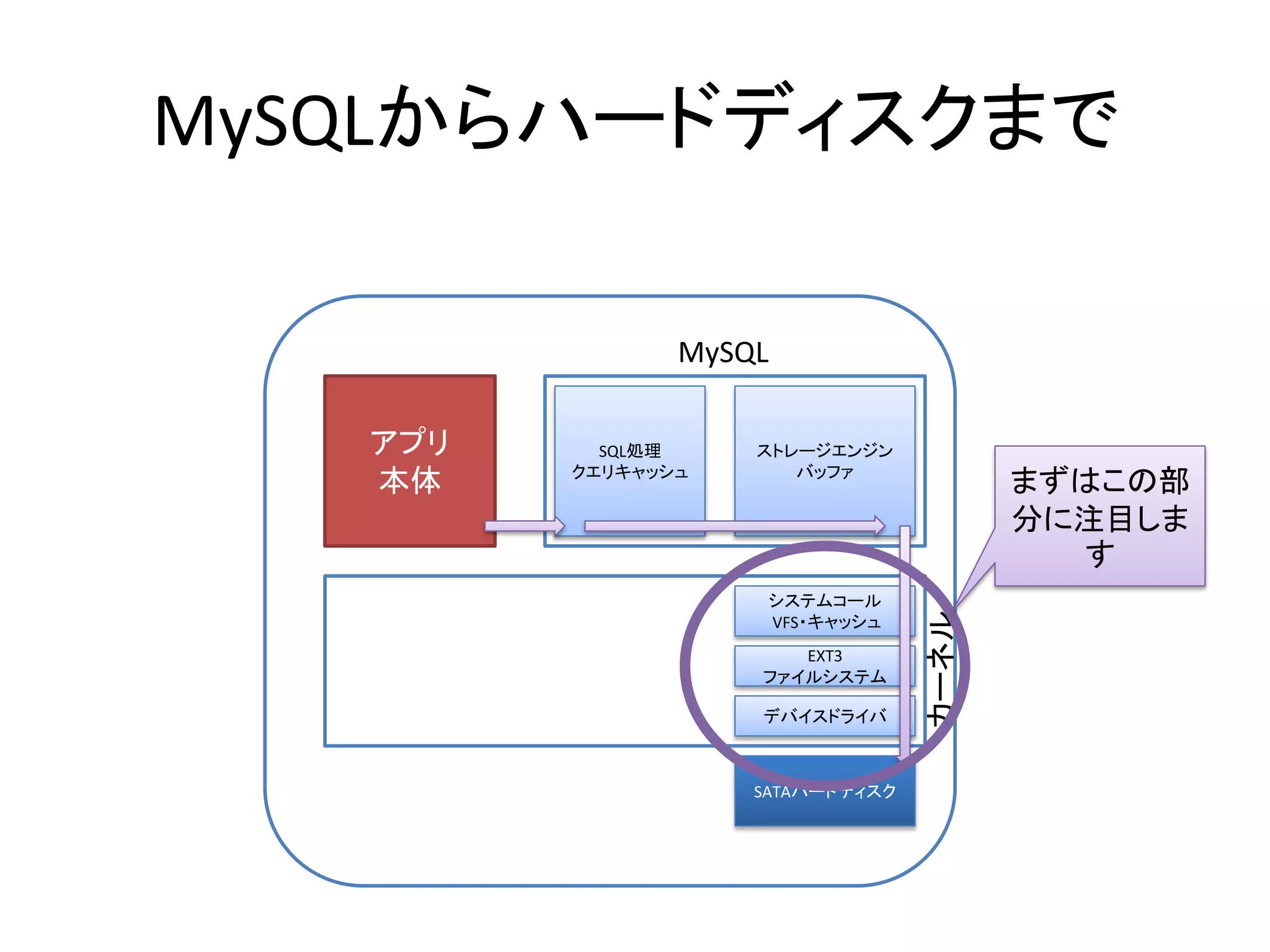
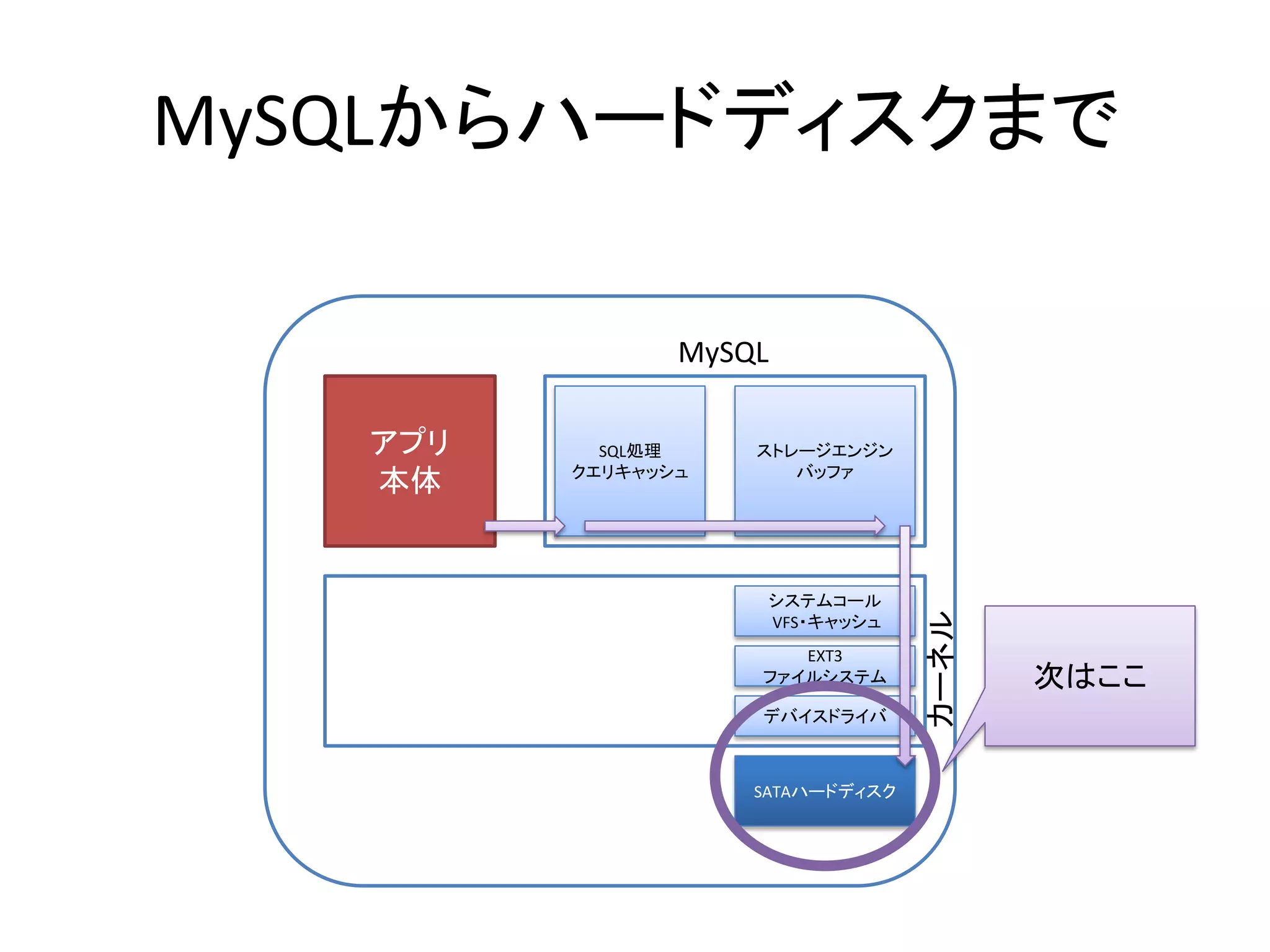
- 9. MySQLからハードディスクまで MySQL アプリ SQL処理 ストレージエンジン クエリキャッシュ バッファ 本体 まずはこの部 分に注目しま す システムコール カーネル VFS・キャッシュ EXT3 ファイルシステム デバイスドライバ SATAハードディスク
- 10. MySQLがディスクに書くまでの おおまかな流れ 1. MySQL→カーネル システムコールを用いて、書き込むデータをカーネルに送る。 2. システムコール→VFS (以下カーネル内) システムコールのルーチン内で、LinuxのVFS(仮想ファイルシステム)に書き込 み指示を送る。 3. VFS→EXT3 VFSは、書き込み先ディレクトリがEXT3でマウントされたファイルシステムである ことを特定し、EXT3のモジュールに書き込み指示を送る。 4. EXT3→デバイスドライバ ここでようやく実際にファイルの記録方法が実装されているため、ハードディス ク上における記録先アドレスを算出し、デバイスドライバに書き込み指示を送る。 5. デバイスドライバ→SATA HBA(コントローラ) デバイスドライバは、記録先アドレスをハードディスクのパーティション情報など を踏まえた物理的な書き込み先アドレスに変換し、HBAに指示 6. SATA HBA→ハードディスク HBAはメモリから書き込み内容を受け取り、SATAのコマンドとしてハードディスク に書き込み内容を送信 7. 書き込み成功したら、その結果を今までの逆順でMySQLまで戻す。 実際にはもっと複雑です。 (ディスクへの書き込みは非同期、など)
- 11. MySQLがディスクに書くまでの おおまかな流れ 1. MySQL→カーネル システムコールを用いて、書き込むデータをカーネルに送る。 2. システムコール→VFS (以下カーネル内) システムコールのルーチン内で、LinuxのVFS(仮想ファイルシステム)に書き込 み指示を送る。 3. VFS→EXT3 VFSは、書き込み先ディレクトリがEXT3でマウントされたファイルシステムである ことを特定し、EXT3のモジュールに書き込み指示を送る。 4. EXT3→デバイスドライバ ここでようやく実際にファイルの記録方法が実装されているため、ハードディス ク上における記録先アドレスを算出し、デバイスドライバに書き込み指示を送る。 5. デバイスドライバ→SATA HBA(コントローラ) デバイスドライバは、記録先アドレスをハードディスクのパーティション情報など を踏まえた物理的な書き込み先アドレスに変換し、HBAに指示 6. SATA HBA→ハードディスク HBAはメモリから書き込み内容を受け取り、SATAのコマンドとしてハードディスク に書き込み内容を送信 7. 書き込み成功したら、その結果を今までの逆順でMySQLまで戻す。 実際にはもっと複雑です。 (ディスクへの書き込みは非同期、など)
- 12. 仮想メモリ • Unix環境では、仮想メモリを利用します。 – 物理的なメモリのアドレスを、仮想的なメモリの空 間にマッピング – プロセスごとに仮想メモリ空間が用意され、そこ に開けられた「窓」を通じて物理メモリにアクセス – 窓のあいていない仮想メモリにアクセスすると 「Segmentation fault」
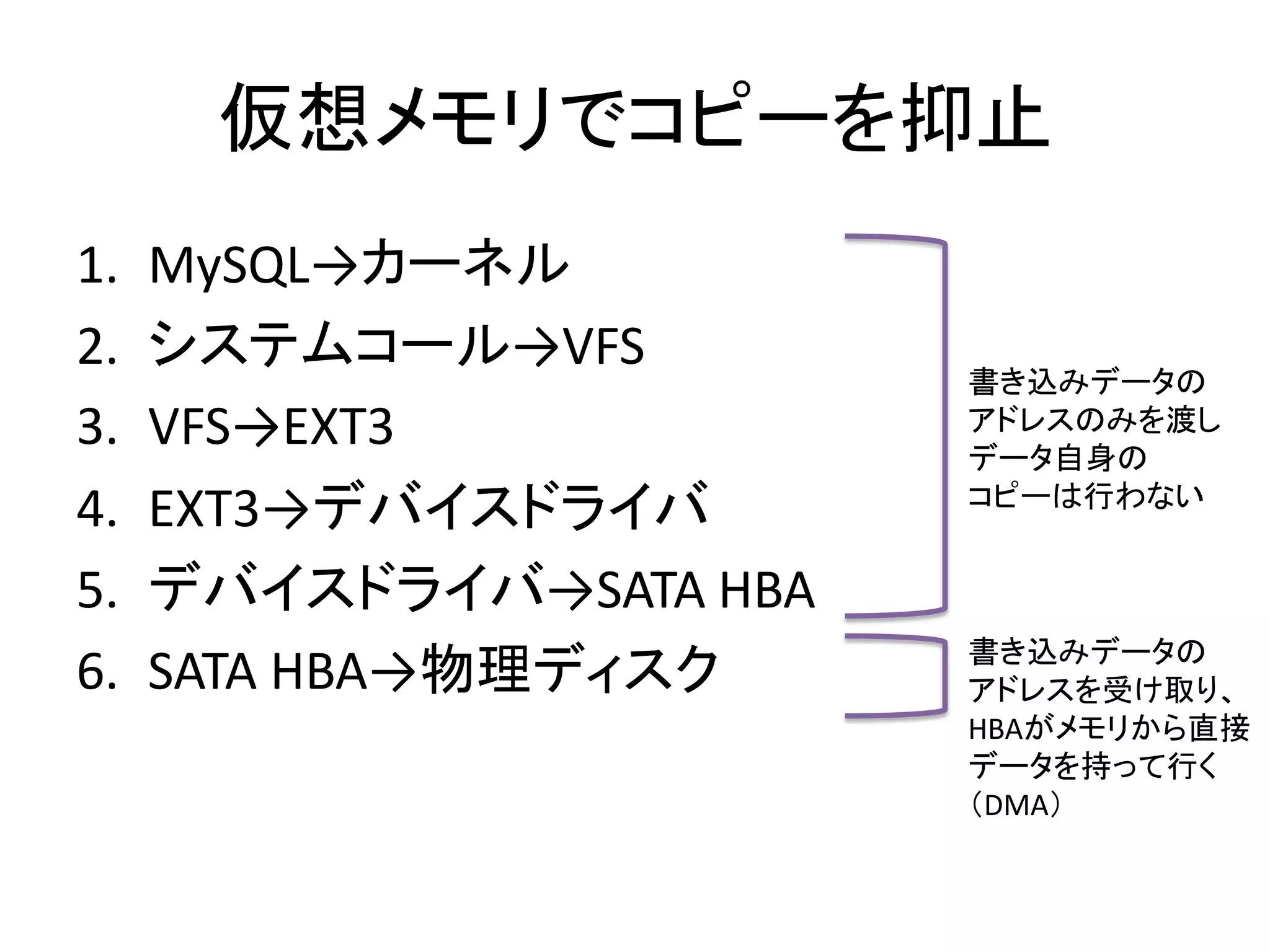
- 13. 仮想メモリでコピーを抑止 1. MySQL→カーネル 2. システムコール→VFS 書き込みデータの 3. VFS→EXT3 アドレスのみを渡し データ自身の コピーは行わない 4. EXT3→デバイスドライバ 5. デバイスドライバ→SATA HBA 書き込みデータの 6. SATA HBA→物理ディスク アドレスを受け取り、 HBAがメモリから直接 データを持って行く (DMA)
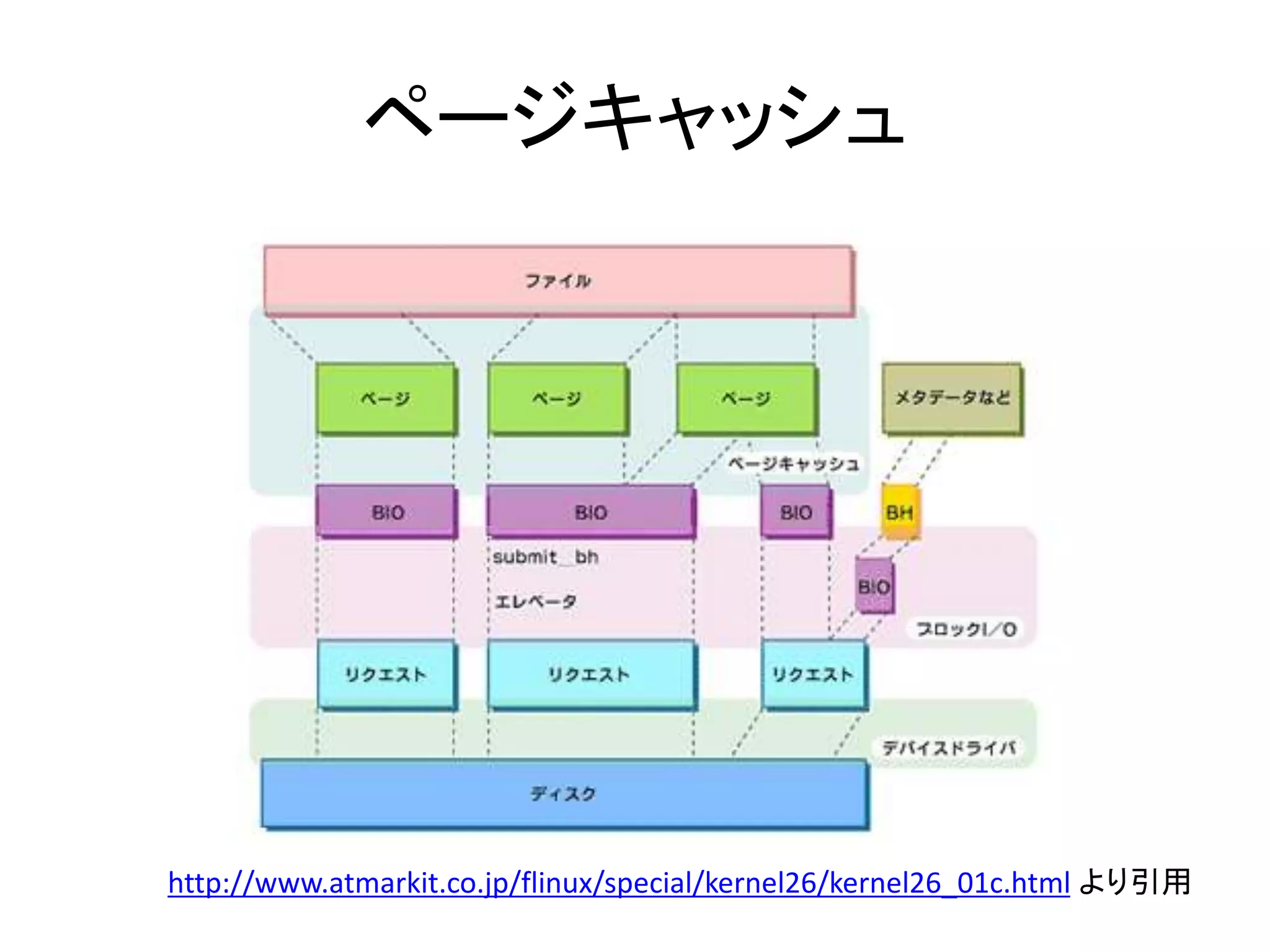
- 14. ページキャッシュ • 仮想メモリ上でやりとりしたデータを、消さず にそのまま再利用→ページキャッシュ • VFS内で、1ページ=4KBごとにキャッシュ – ファイル1個ずつに振られたiノード番号 – ファイル内の位置(オフセット) • Linuxではメモリが足りる限りページキャッシュ を残す。 • 実際にはページキャッシュに書いた時点で、 システムコールはアプリに処理を戻す。
- 16. MySQLからハードディスクまで MySQL アプリ SQL処理 ストレージエンジン クエリキャッシュ バッファ 本体 システムコール カーネル VFS・キャッシュ EXT3 ファイルシステム 次はここ デバイスドライバ SATAハードディスク
- 17. SATAハードディスクへの読み書き • 基本的な動作(単体のSATAディスクの場合) 1. デバイスドライバがSATAのコマンドを作成 2. SATAインターフェースカードがコマンドをSATA ケーブルに送信 3. ハードディスクがSATAコマンドを受信 4. 書き込み位置にヘッドを移動 5. 回り続けるディスクで、ヘッドの下に書き込み位 置が来たところで磁気を使って書き込み
- 18. 複雑になる要因 コマンドキューイング • ハードディスクが遅い最大要因: • 「回り続けるディスクで、ヘッドの下に書き込み位 置が来たところで磁気を使って書き込み」 • 物理的に近いものをまとめて読み書き →コマンドをいったん待ち行列に入れ(キューイン グ)、都合の良い順序に入れ替え
- 20. 複雑になる要因 RAIDコントローラ • ハードディスクが遅いなら並べれば早くなる • データを細切りにして複数のハードディスクに分 散して読み書き • RAIDコントローラ内のキャッシュに保存したら、も う書き込み終わったことにしてしまう (ライトバックキャッシュ) – 停電したら書いたはずのデータが実は未保存 → RAIDコントローラに電池を搭載(BBWC) 電源復帰したら書き込み (バッテリーなしでは危険!)
- 21. 複雑になる要因 SSD • フラッシュメモリを使った記録メディア – 物理的な可動部分がないので反応が早い。 – 同じ場所を何度も書き込みすると寿命が来る。 – インターフェースはSATA,SAS等 • ウェアレベリング – 仮想メモリのように、実際の記録先を入れ替える。 – 寿命が来たブロックを切り離し、代替ブロックと差 し替える。 – どちらも、SATAコントローラ側からは関知しない
- 22. 複雑になる要因 FusionIO ioDrive等の出現 • 性能特性が全く異なる(ディスクとメモリの中間) – 量が多く全体を舐める集計処理 – 運用コスト削減 (台数削減) – 開発の省力化 (チューニング等) http://monoist.atmarkit.co.jp/feledev/news/2011/01/13ted.html より引用
- 23. 複雑になる要因 階層型ストレージ • アクセス頻度に応じて、物理メディアを変更 – アクセス頻度が低い:回転数の低いSATAディスク – アクセス頻度が普通:SASディスク – アクセス頻度が高い:SSDやFusionIO – アクセス頻度が極めて高い:キャッシュを併用
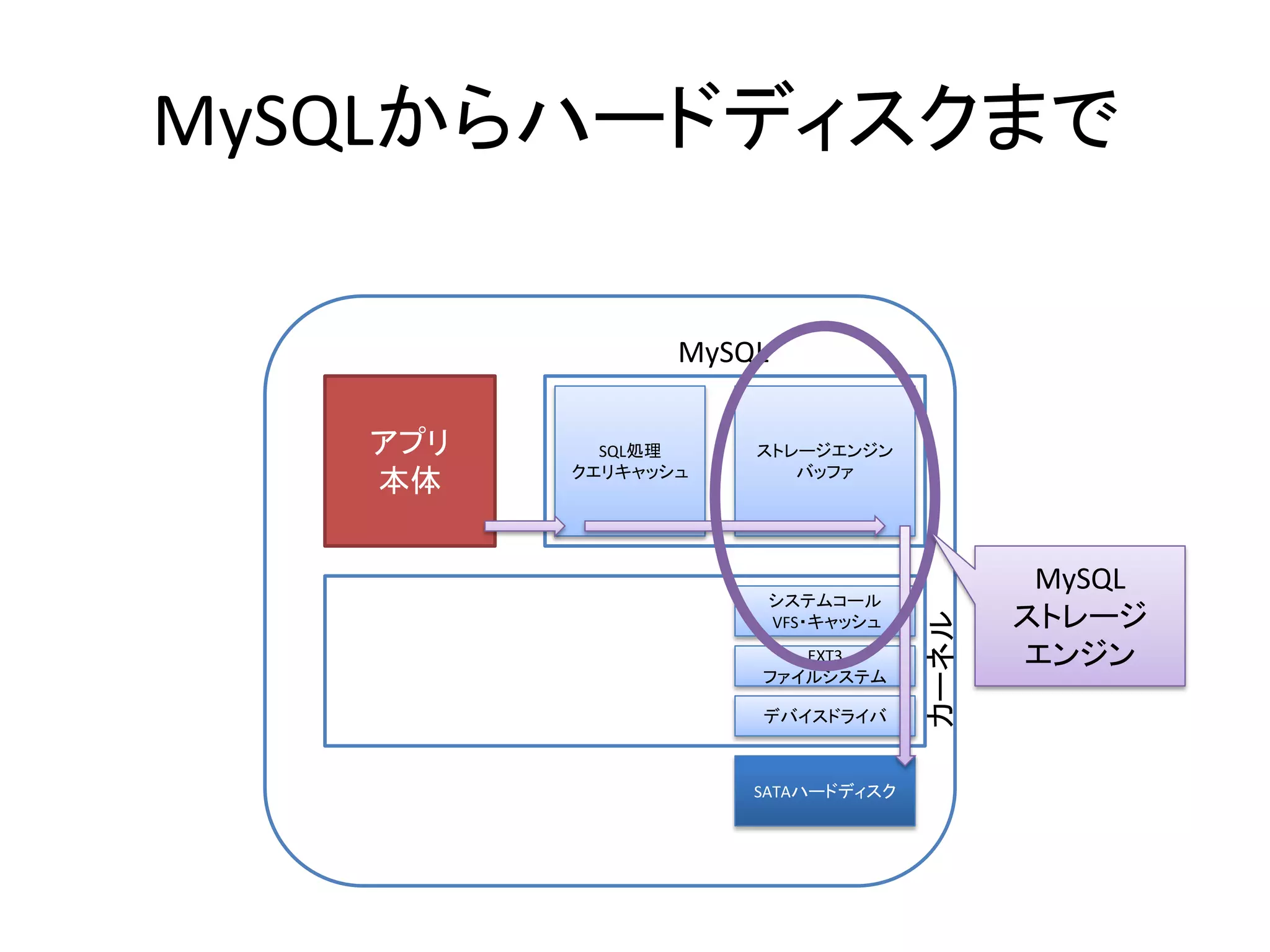
- 24. MySQLからハードディスクまで MySQL アプリ SQL処理 ストレージエンジン クエリキャッシュ バッファ 本体 MySQL システムコール ストレージ カーネル VFS・キャッシュ EXT3 エンジン ファイルシステム デバイスドライバ SATAハードディスク
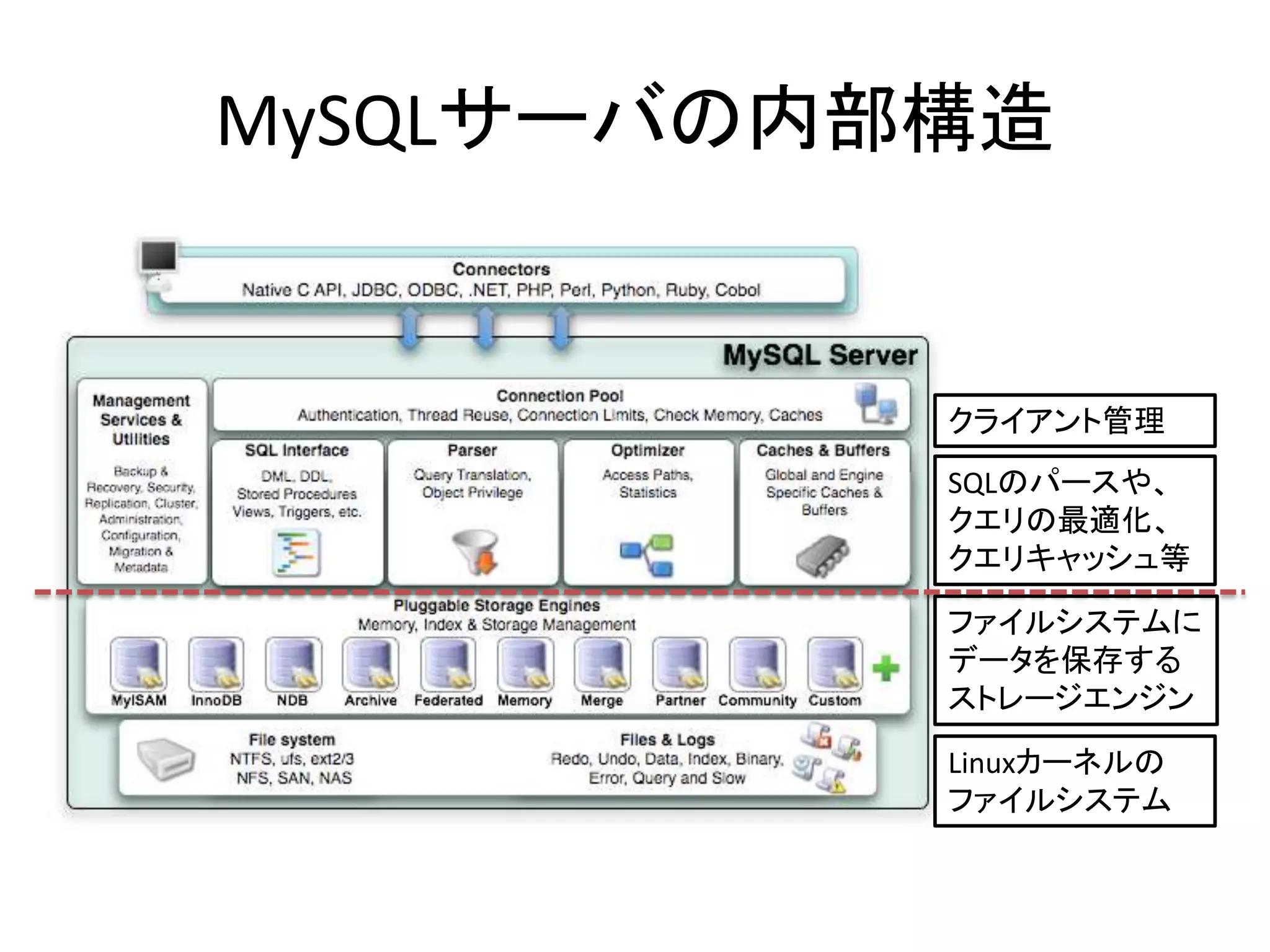
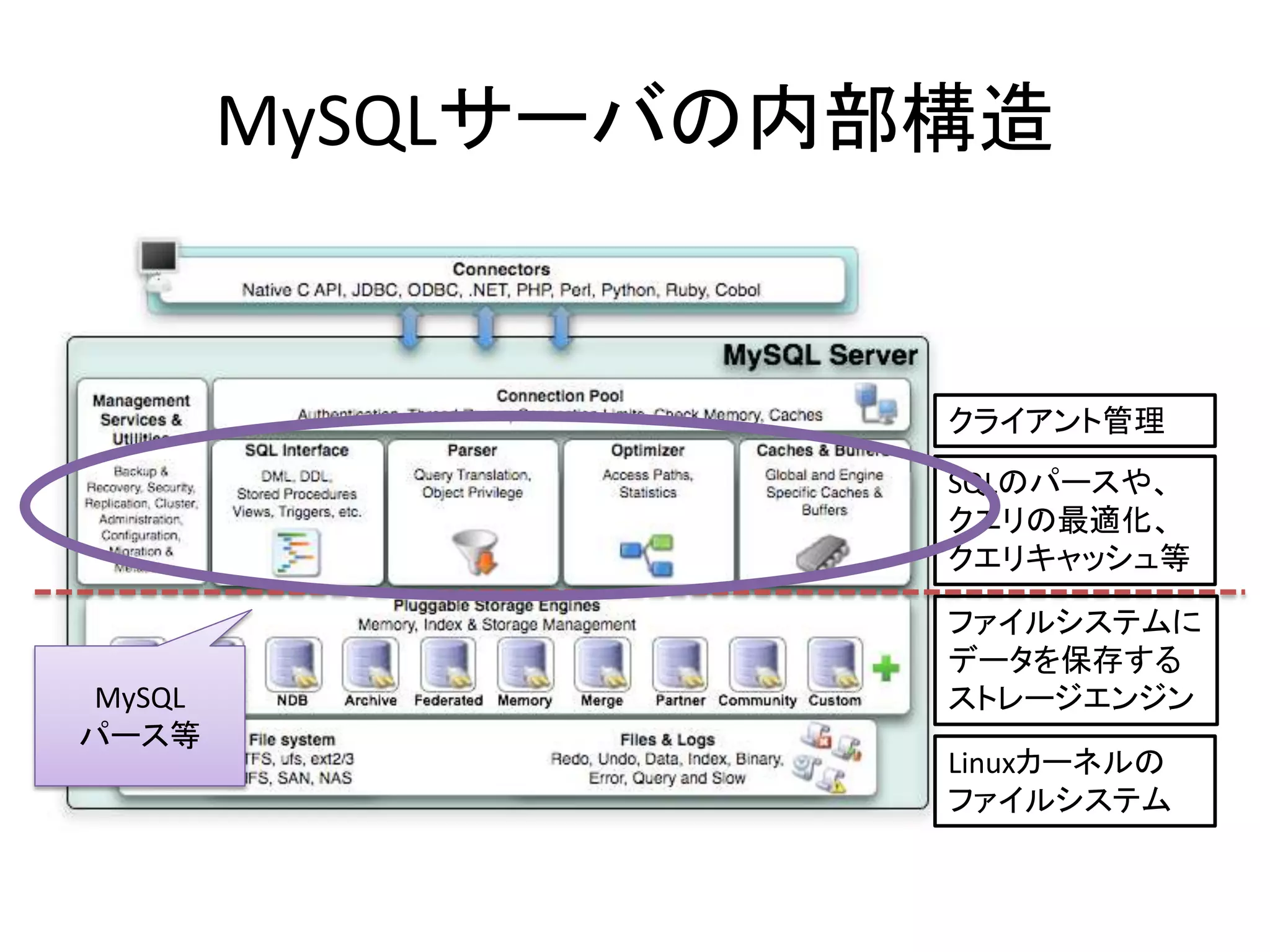
- 25. MySQLサーバの内部構造 クライアント管理 SQLのパースや、 クエリの最適化、 クエリキャッシュ等 ファイルシステムに データを保存する ストレージエンジン Linuxカーネルの ファイルシステム
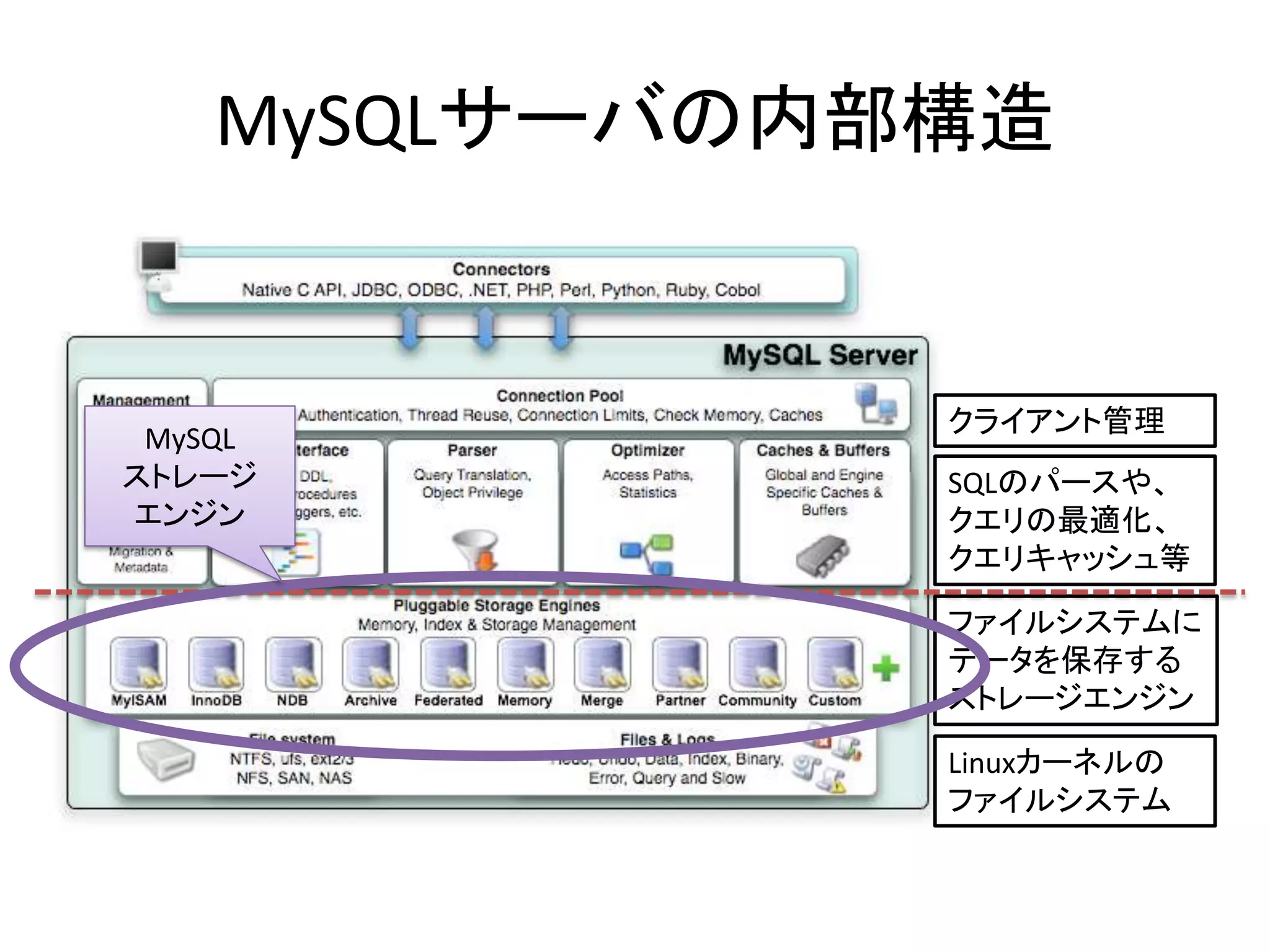
- 26. MySQLサーバの内部構造 クライアント管理 MySQL ストレージ SQLのパースや、 エンジン クエリの最適化、 クエリキャッシュ等 ファイルシステムに データを保存する ストレージエンジン Linuxカーネルの ファイルシステム
- 27. ストレージエンジンの仕事 • 表形式のデータを保存する。 – 複数のカラム(数値、文字列等)が集まった行 – 複数の行が集まった表 – 複数の表が集まったデータベース • 表から、検索条件に見合う行(に含まれるカラ ム)を検索・取得する。
- 28. ストレージエンジンの仕事 • 表形式のデータを保存する。 – 複数のカラム(数値、文字列等)が集まった行 – 複数の行が集まった表 – 複数の表が集まったデータベース • 表から、検索条件に見合う行(に含まれるカラ ム)を検索・取得する。 • 検索しやすい形式でデータを記録する。
- 29. 検索の仕方 1. 順次走査検索(grep型) – データの内容を一件ずつ検索条件と比較する。 – 挿入のコストはO(1)、検索のコストはO(n) 2. インデックス検索 – あらかじめ、検索用の小さな索引(インデックス) を作成しておき、高速に検索する。 – インデックスの作成方法がたくさんある – MySQLであれば原則B木(B-tree) 挿入・検索のコストはO(log n)
- 30. データ本体の格納場所 • クラスタードインデックス(InnoDB等) – プライマリキーのB木の末端に、直接その行の データ本体を記録する。 – プライマリキーからの検索であれば、B木を一回 たどるだけで取得可能 – プライマリキー以外での検索は、セカンダリーイ ンデックスの末端にプライマリキーを格納し、2回 B木をたどる。
- 31. インデックスが高速な理由 1. そもそも検索コストが低い – O(n)に対して、O(log n)しか計算量が増えない。 – データ量が、1MB→10MBに増えたときに検索時 間が0.01秒から0.1秒に10倍に増えたと仮定。 – 10MB→100MBに増えた場合: 逐次検索:さらに10倍に増えて、1秒 インデックス検索:2倍しか増えず、0.2秒
- 32. インデックスが高速な理由 2. アクセスするデータ量が少ない – OSのページキャッシュに残る可能性が上がる – 1GBのデータ本体、100MBのインデックス 逐次検索:毎回、平均500MBを読み取り インデックス検索:毎回、平均50MBを読み取り (実際はB木の辿った部分のみでさらに少ない) – インデックスがページキャッシュからあふれると、 一気に性能が务化
- 33. インデックスの更新 • インデックスが更新されるケース – データの追加・削除 – インデックスを張っているデータの変更 • 何が起きるか – B木が深くなり、効率が下がる – インデックスを詰めるのは大変 →削除マークをつけて無視する – インデックスのサイズが増える→メモリから溢れる • 不必要なインデックスは作らないことも重要
- 34. MySQLサーバの内部構造 クライアント管理 SQLのパースや、 クエリの最適化、 クエリキャッシュ等 ファイルシステムに データを保存する MySQL ストレージエンジン パース等 Linuxカーネルの ファイルシステム
- 35. SQLのパース処理 • SQLのパースは案外重い – 上半分をまるまる差し替える DeNA Handlersocket plugin • クエリキャッシュをうまく使う – プリペアドステートメントはキャッシュ効かないorz この辺は個別ノウハウの かたまりなので今回は割愛