CPANci: Continuous Integration for CPAN
0 likes2,534 views
The document provides a brief history of testing on CPAN from 1987 to the present. It discusses the development of the Test Anything Protocol (TAP) and CPAN Testers for testing Perl modules. It then proposes the idea of CPANci, a continuous integration system for all of CPAN that would test each distribution in isolation on virtualized environments to avoid issues with CPAN Testers. The document outlines an approach using perlbrew and cpanminus to test each distribution on fresh Perl installations of different versions.



























































































































More Related Content
What's hot (19)
Similar to CPANci: Continuous Integration for CPAN (20)
More from Mike Friedman (8)
Recently uploaded (20)
CPANci: Continuous Integration for CPAN
- 1. Testing CPAN in the 21st Century Mike Friedman (friedo) YAPC::NA 2013 Austin,TX Tuesday, June 4, 13
- 2. A lengthy series of bad ideas and stupid questions. Tuesday, June 4, 13
- 3. Tuesday, June 4, 13
- 4. Stupid Question No. 1 Tuesday, June 4, 13
- 5. Tuesday, June 4, 13
- 6. Stupid Question No. 2 Tuesday, June 4, 13
- 7. What’s this about, anyway? Tuesday, June 4, 13
- 8. What’s this about, anyway? CPANci Tuesday, June 4, 13
- 9. A Brief History Tuesday, June 4, 13
- 10. A Brief History •December 18, 1987 Tuesday, June 4, 13
- 11. A Brief History •December 18, 1987 •Perl 1.000 released. Tuesday, June 4, 13
- 12. A Brief History •December 18, 1987 •Perl 1.000 released. •TAP invented. Tuesday, June 4, 13
- 13. The Test Anything Protocol Tuesday, June 4, 13
- 14. The Test Anything Protocol 1..42 ok 1 the thing looks good! ok 2 ok 3 $beer isa $drink not ok 4 too much $beer not ok 5 $me->vomit( 'now' ) ... Tuesday, June 4, 13
- 15. A Brief History Tuesday, June 4, 13
- 16. A Brief History •October 17, 1994 Tuesday, June 4, 13
- 17. A Brief History •October 17, 1994 •Perl 5.000 released. Tuesday, June 4, 13
- 18. A Brief History •October 17, 1994 •Perl 5.000 released. •Perl has a module system. Tuesday, June 4, 13
- 19. Tuesday, June 4, 13
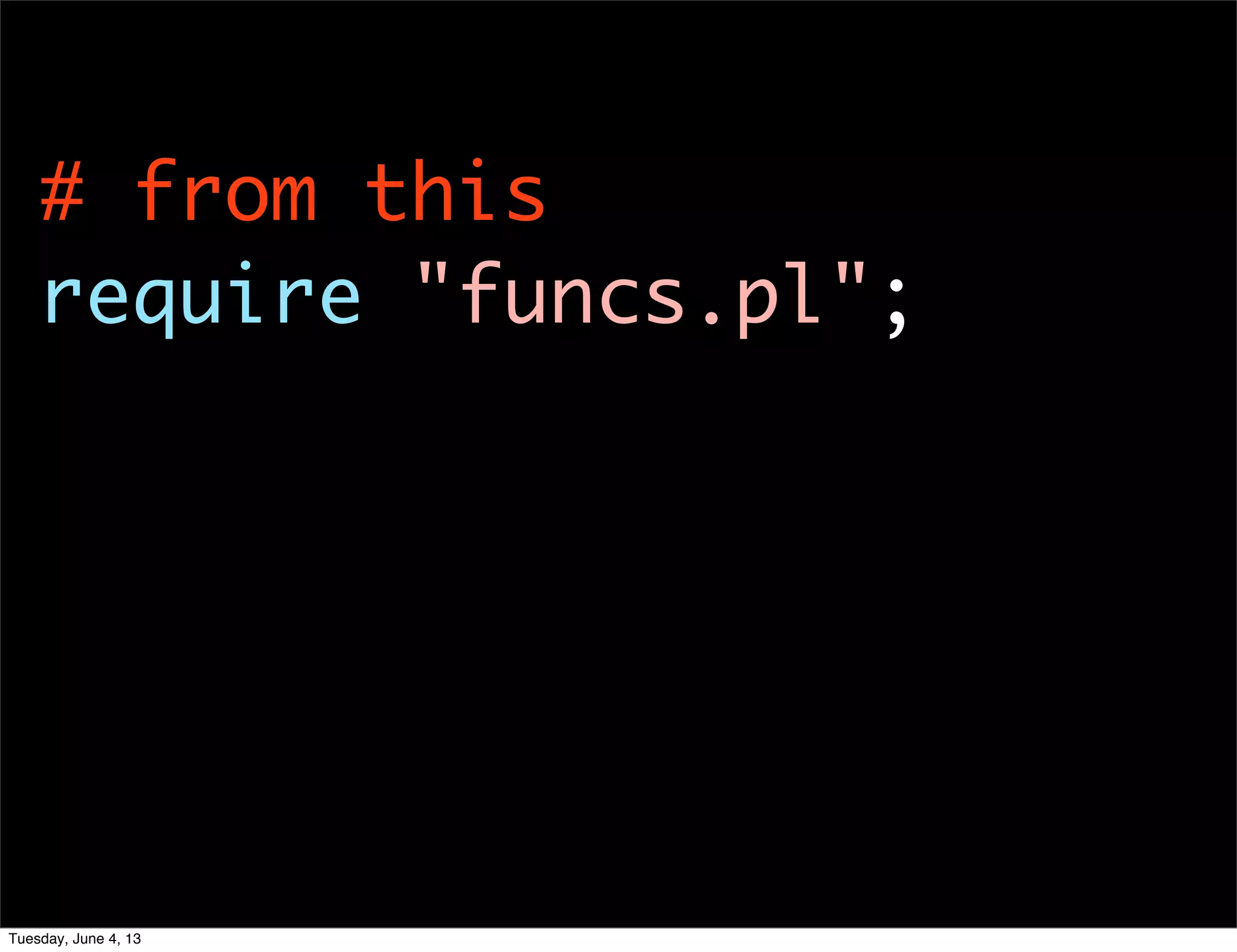
- 20. # from this require "funcs.pl"; Tuesday, June 4, 13
- 21. # from this require "funcs.pl"; # to this use My::Module; Tuesday, June 4, 13
- 22. Tuesday, June 4, 13
- 23. # but under the hood BEGIN { require My::Module; My::Module->import; }; Tuesday, June 4, 13
- 24. A Brief History Tuesday, June 4, 13
- 25. A Brief History •October 26, 1995 Tuesday, June 4, 13
- 26. A Brief History •October 26, 1995 •CPAN established. Tuesday, June 4, 13
- 27. A Brief History •October 26, 1995 •CPAN established. •Perl modules are available. Tuesday, June 4, 13
- 28. A Brief History Tuesday, June 4, 13
- 29. A Brief History •May 15, 1997 Tuesday, June 4, 13
- 30. A Brief History •May 15, 1997 •Perl 5.004 released. Tuesday, June 4, 13
- 31. A Brief History •May 15, 1997 •Perl 5.004 released. •CPAN.pm is in the core. Tuesday, June 4, 13
- 32. Tuesday, June 4, 13
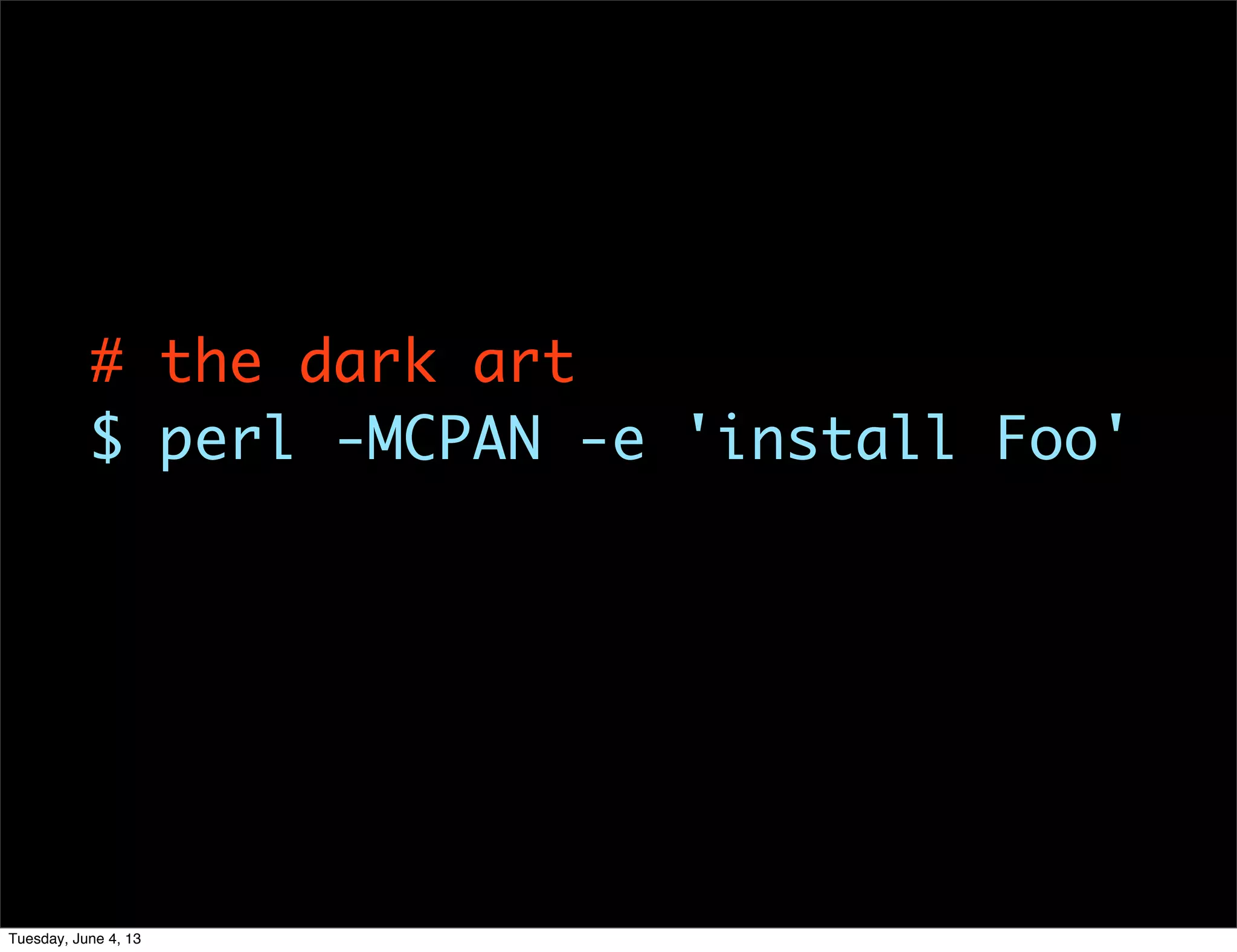
- 33. # the dark art $ perl -MCPAN -e 'install Foo' Tuesday, June 4, 13
- 34. A Brief History Tuesday, June 4, 13
- 35. A Brief History •May, 1998 Tuesday, June 4, 13
- 36. A Brief History •May, 1998 •CPAN Testers conceived Tuesday, June 4, 13
- 37. A Brief History •May, 1998 •CPAN Testers conceived •Automated feedback for authors Tuesday, June 4, 13
- 38. Tuesday, June 4, 13
- 39. Tuesday, June 4, 13
- 40. Tuesday, June 4, 13
- 41. Tuesday, June 4, 13
- 42. A Brief History Tuesday, June 4, 13
- 43. A Brief History •November 15, 2003 Tuesday, June 4, 13
- 44. A Brief History •November 15, 2003 •Perl 5.6.2 released. Tuesday, June 4, 13
- 45. A Brief History •November 15, 2003 •Perl 5.6.2 released. •Test::More is in the core. Tuesday, June 4, 13
- 46. Tuesday, June 4, 13
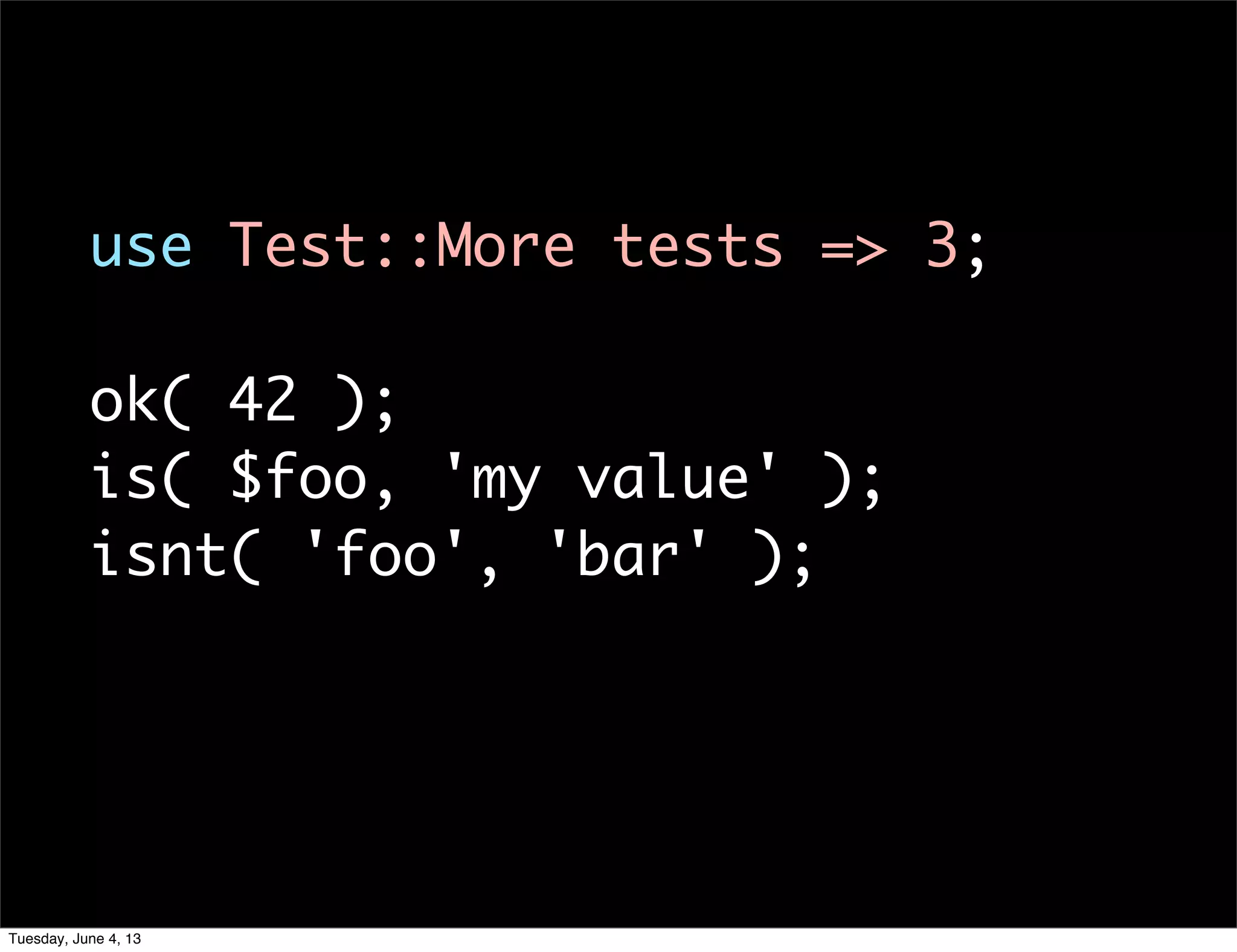
- 47. use Test::More tests => 3; ok( 42 ); is( $foo, 'my value' ); isnt( 'foo', 'bar' ); Tuesday, June 4, 13
- 48. A Brief History Tuesday, June 4, 13
- 49. A Brief History •August 6, 2012 Tuesday, June 4, 13
- 50. A Brief History •August 6, 2012 •Mike goes to work for 10gen Tuesday, June 4, 13
- 51. Tuesday, June 4, 13
- 52. Tuesday, June 4, 13
- 53. WEB SCALE!!!!11 Tuesday, June 4, 13
- 54. WEB SCALE!!!!11 LOL Tuesday, June 4, 13
- 55. Tuesday, June 4, 13
- 56. Bad Idea No. 1 Tuesday, June 4, 13
- 57. Bad Idea No. 1 Come up with a cool Perl MongoDB project to show off atYAPC! Tuesday, June 4, 13
- 58. Bad Idea No. 1 Come up with a cool Perl MongoDB project to show off atYAPC! It'll be fun! Tuesday, June 4, 13
- 59. Bad Idea No. 1 Come up with a cool Perl MongoDB project to show off atYAPC! It'll be fun! promise! Tuesday, June 4, 13
- 60. CPAN Testers is Wonderful and Amazing Tuesday, June 4, 13
- 61. Tuesday, June 4, 13
- 63. Disadvantages: Not real time Tuesday, June 4, 13
- 64. Disadvantages: Not real time Not consistent Tuesday, June 4, 13
- 65. Disadvantages: Not real time Not consistent Polluted / Inconsistent environments Tuesday, June 4, 13
- 66. Disadvantages: Not real time Not consistent Polluted / Inconsistent environments Not all versions on all platforms Tuesday, June 4, 13
- 67. I want Continuous Integration for the entire CPAN. Tuesday, June 4, 13
- 68. Tuesday, June 4, 13
- 69. Bad Idea No. 2 Tuesday, June 4, 13
- 70. CPANci.org Bad Idea No. 2 Tuesday, June 4, 13
- 71. Tuesday, June 4, 13
- 72. Stupid Question No. 3 Tuesday, June 4, 13
- 73. Stupid Question No. 3 How can we test CPAN without the disadvantages of CPAN Testers? Tuesday, June 4, 13
- 74. Postulate: Every CPAN distribution must be tested in isolation, on a virgin Perl installation untouched by human hands. Tuesday, June 4, 13
- 75. Postulate: Every CPAN distribution must be tested in isolation, on a virgin Perl installation untouched by human hands. So how do we do that? Tuesday, June 4, 13
- 76. perlbrew Tuesday, June 4, 13
- 79. Tuesday, June 4, 13
- 80. Bad Idea No. 3 Tuesday, June 4, 13
- 81. Tuesday, June 4, 13
- 82. •Create an EC2 image Tuesday, June 4, 13
- 83. •Create an EC2 image •Put perlbrew on it Tuesday, June 4, 13
- 84. •Create an EC2 image •Put perlbrew on it •Install every Perl locally Tuesday, June 4, 13
- 85. •Create an EC2 image •Put perlbrew on it •Install every Perl locally •Boot an instance for every uploaded distribution Tuesday, June 4, 13
- 86. •Create an EC2 image •Put perlbrew on it •Install every Perl locally •Boot an instance for every uploaded distribution •Install needed dependencies for the distribution Tuesday, June 4, 13
- 87. •Create an EC2 image •Put perlbrew on it •Install every Perl locally •Boot an instance for every uploaded distribution •Install needed dependencies for the distribution •Run the tests and report the results Tuesday, June 4, 13
- 88. •Create an EC2 image •Put perlbrew on it •Install every Perl locally •Boot an instance for every uploaded distribution •Install needed dependencies for the distribution •Run the tests and report the results •Shut down the instance Tuesday, June 4, 13
- 89. Tuesday, June 4, 13
- 90. Tuesday, June 4, 13
- 91. Stupid Question No. 4 Tuesday, June 4, 13
- 92. Stupid Question No. 4 How can we do this on one instance? Tuesday, June 4, 13
- 96. App::cpanminus •Self-contained •That is, the cpanm script is self-contained Tuesday, June 4, 13
- 97. App::cpanminus •Self-contained •That is, the cpanm script is self-contained •via App::FatPacker Tuesday, June 4, 13
- 99. App::cpanminus That means the same cpanm can be run by any perl Tuesday, June 4, 13
- 100. App::cpanminus That means the same cpanm can be run by any perl perlbrew switch master curl -L http://cpanmin.us/ | perl - App::cpanminus ln -s ~/perl5/perlbrew/perls/master/bin/cpanm ./cpanm ~/perl5/perlbrew/perls/perl-5.8.9/bin/perl cpanm ~/perl5/perlbrew/perls/perl-5.10.1/bin/perl cpanm ~/perl5/perlbrew/perls/perl-5.12.5/bin/perl cpanm ~/perl5/perlbrew/perls/perl-5.14.4/bin/perl cpanm ~/perl5/perlbrew/perls/perl-5.16.3/bin/perl cpanm ~/perl5/perlbrew/perls/perl-5.18.0/bin/perl cpanm ~/perl5/perlbrew/perls/perl-5.19.0/bin/perl cpanm Tuesday, June 4, 13
- 101. Tuesday, June 4, 13
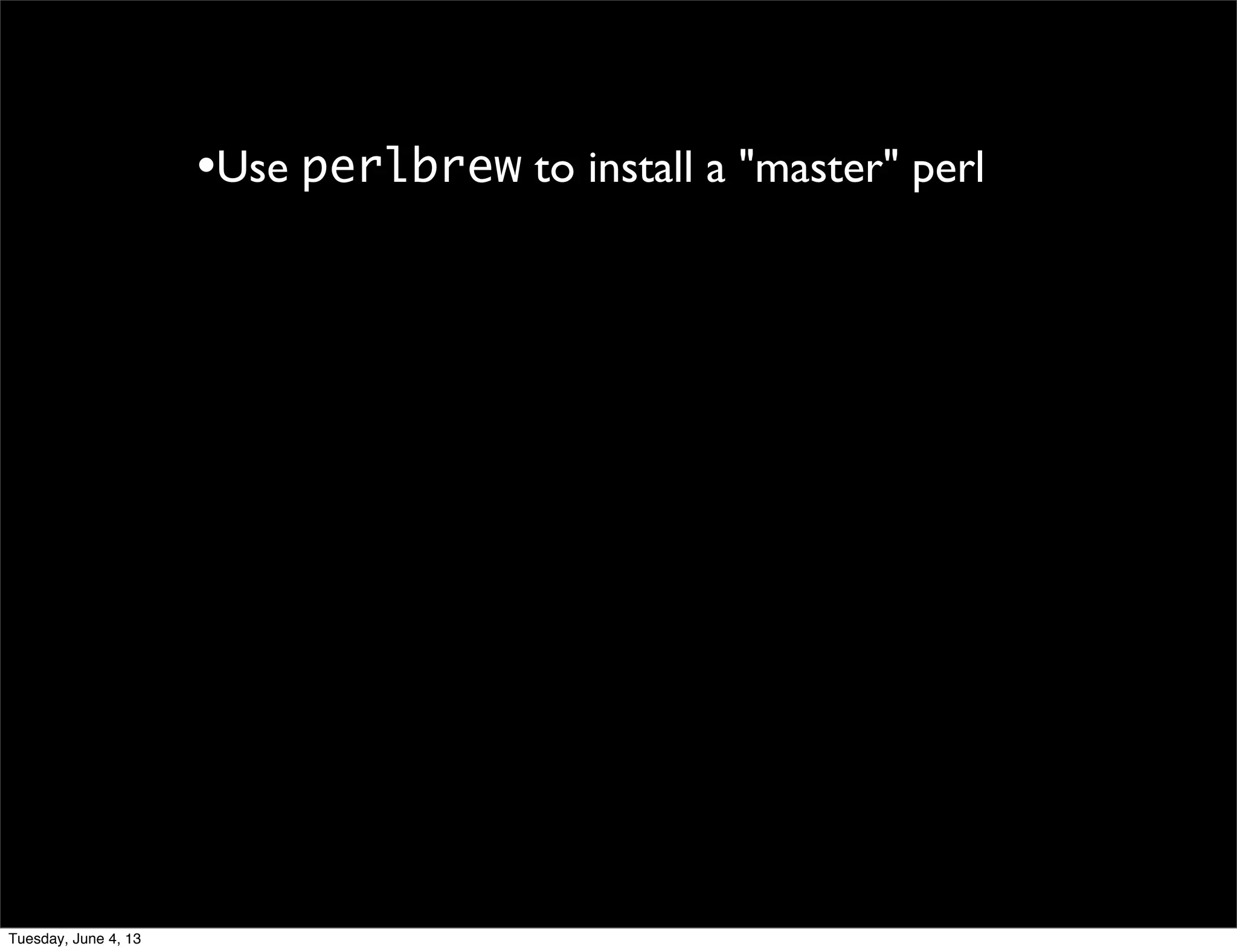
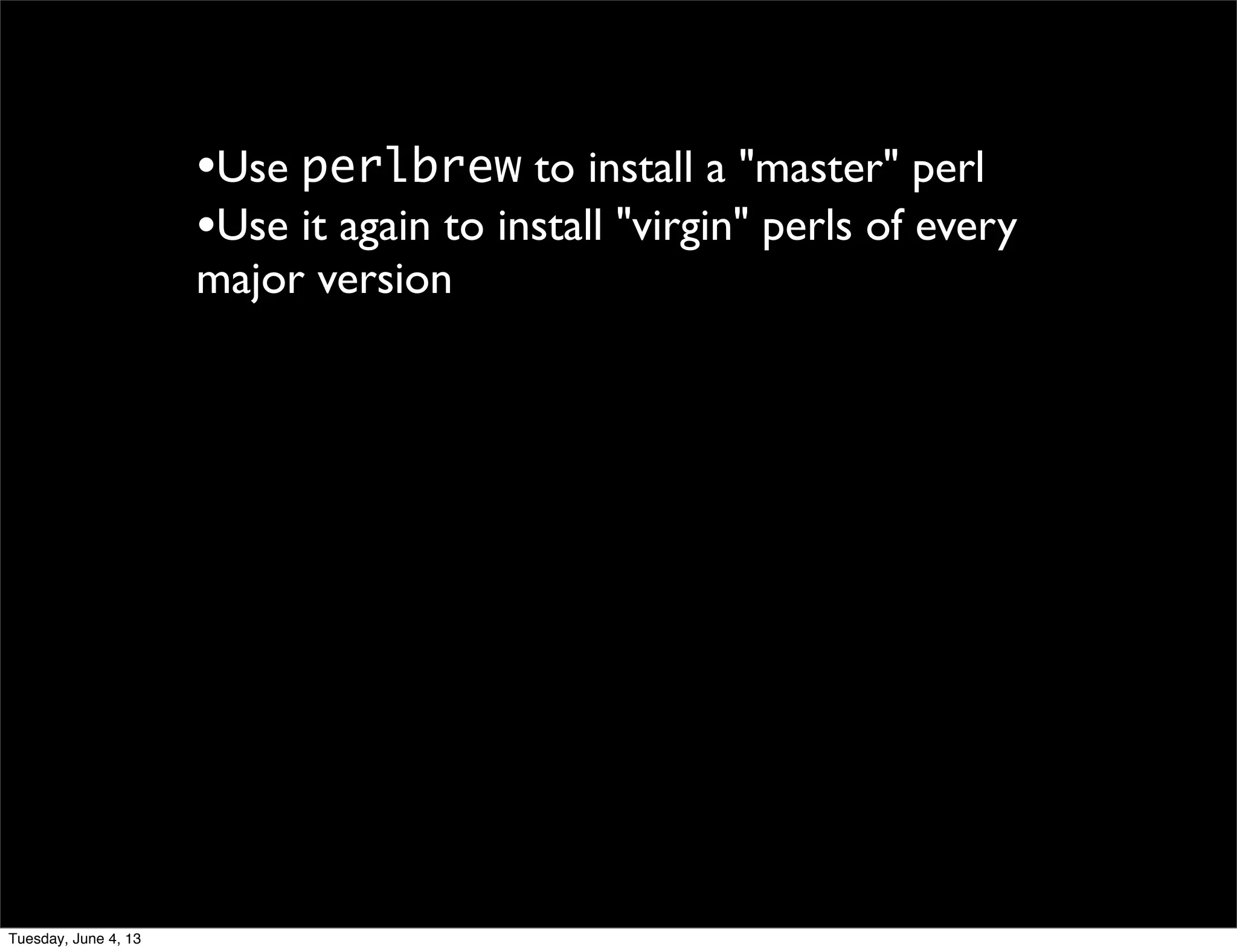
- 102. •Use perlbrew to install a "master" perl Tuesday, June 4, 13
- 103. •Use perlbrew to install a "master" perl •Use it again to install "virgin" perls of every major version Tuesday, June 4, 13
- 104. •Use perlbrew to install a "master" perl •Use it again to install "virgin" perls of every major version •Use the master perl to install everything from CPAN that makes CPANci work Tuesday, June 4, 13
- 105. •Use perlbrew to install a "master" perl •Use it again to install "virgin" perls of every major version •Use the master perl to install everything from CPAN that makes CPANci work •For each distribution, create a temp directory Tuesday, June 4, 13
- 106. •Use perlbrew to install a "master" perl •Use it again to install "virgin" perls of every major version •Use the master perl to install everything from CPAN that makes CPANci work •For each distribution, create a temp directory •Tell cpanminus to install dependencies there, as if for local::lib Tuesday, June 4, 13
- 107. •Use perlbrew to install a "master" perl •Use it again to install "virgin" perls of every major version •Use the master perl to install everything from CPAN that makes CPANci work •For each distribution, create a temp directory •Tell cpanminus to install dependencies there, as if for local::lib •Run tests and report results Tuesday, June 4, 13
- 108. •Use perlbrew to install a "master" perl •Use it again to install "virgin" perls of every major version •Use the master perl to install everything from CPAN that makes CPANci work •For each distribution, create a temp directory •Tell cpanminus to install dependencies there, as if for local::lib •Run tests and report results •Delete temp directory, leaving each perl untouched! Tuesday, June 4, 13
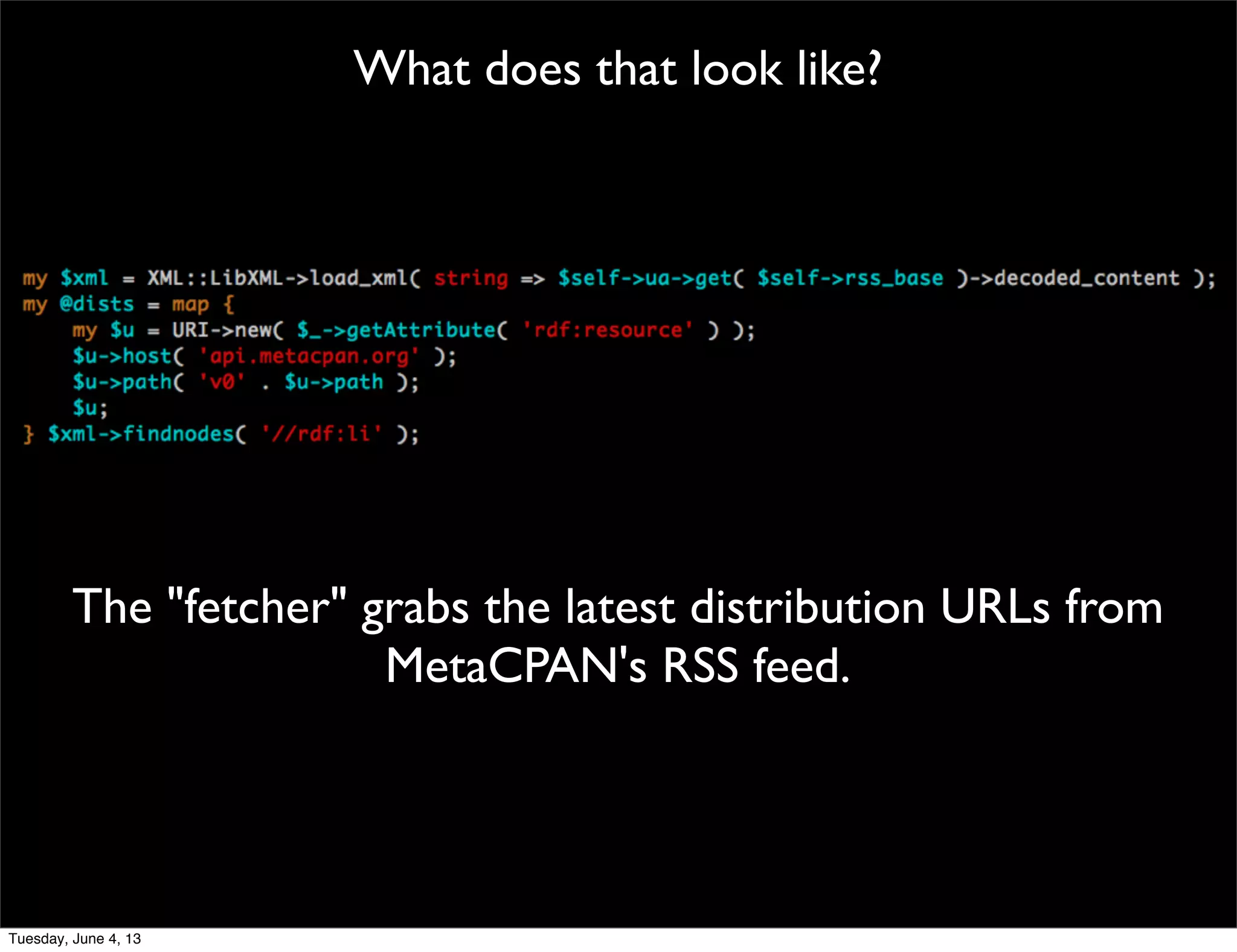
- 109. What does that look like? The "fetcher" grabs the latest distribution URLs from MetaCPAN's RSS feed. Tuesday, June 4, 13
- 110. What does that look like? We retrieve the distribution metadata from the MetaCPAN JSON API and saved it to MongoDB. Then we start the Installer. Tuesday, June 4, 13
- 111. What does that look like? We download the distribution tarball to a temp file. Then the fun stuff starts to happen. Tuesday, June 4, 13
- 112. What does that look like? We extract the archive in a specific "work" directory for each perl. Then create a temp directory for building and installing dependencies. Tuesday, June 4, 13
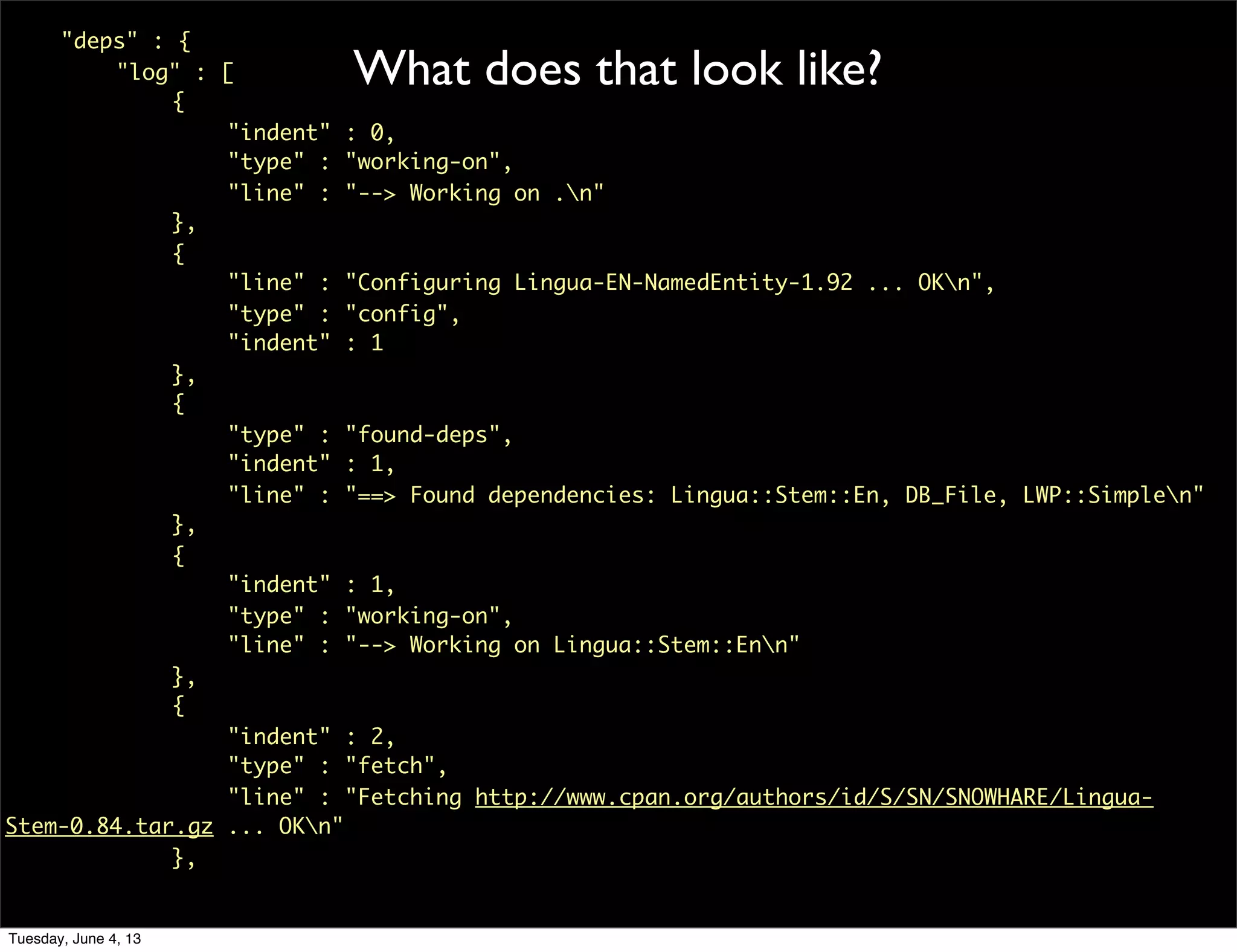
- 113. What does that look like? Use a specific perl binary to run cpanm and install dependencies, with no tests, to the temp directory. Then we parse the cpanm log on stderr Tuesday, June 4, 13
- 114. What does that look like? "deps" : { "log" : [ { "indent" : 0, "type" : "working-on", "line" : "--> Working on .n" }, { "line" : "Configuring Lingua-EN-NamedEntity-1.92 ... OKn", "type" : "config", "indent" : 1 }, { "type" : "found-deps", "indent" : 1, "line" : "==> Found dependencies: Lingua::Stem::En, DB_File, LWP::Simplen" }, { "indent" : 1, "type" : "working-on", "line" : "--> Working on Lingua::Stem::Enn" }, { "indent" : 2, "type" : "fetch", "line" : "Fetching http://www.cpan.org/authors/id/S/SN/SNOWHARE/Lingua- Stem-0.84.tar.gz ... OKn" }, Tuesday, June 4, 13
- 115. What does that look like? Use a specific perl to run each test file, save the TAP output and any errors, and use the exit status to determine if it passed. Tuesday, June 4, 13
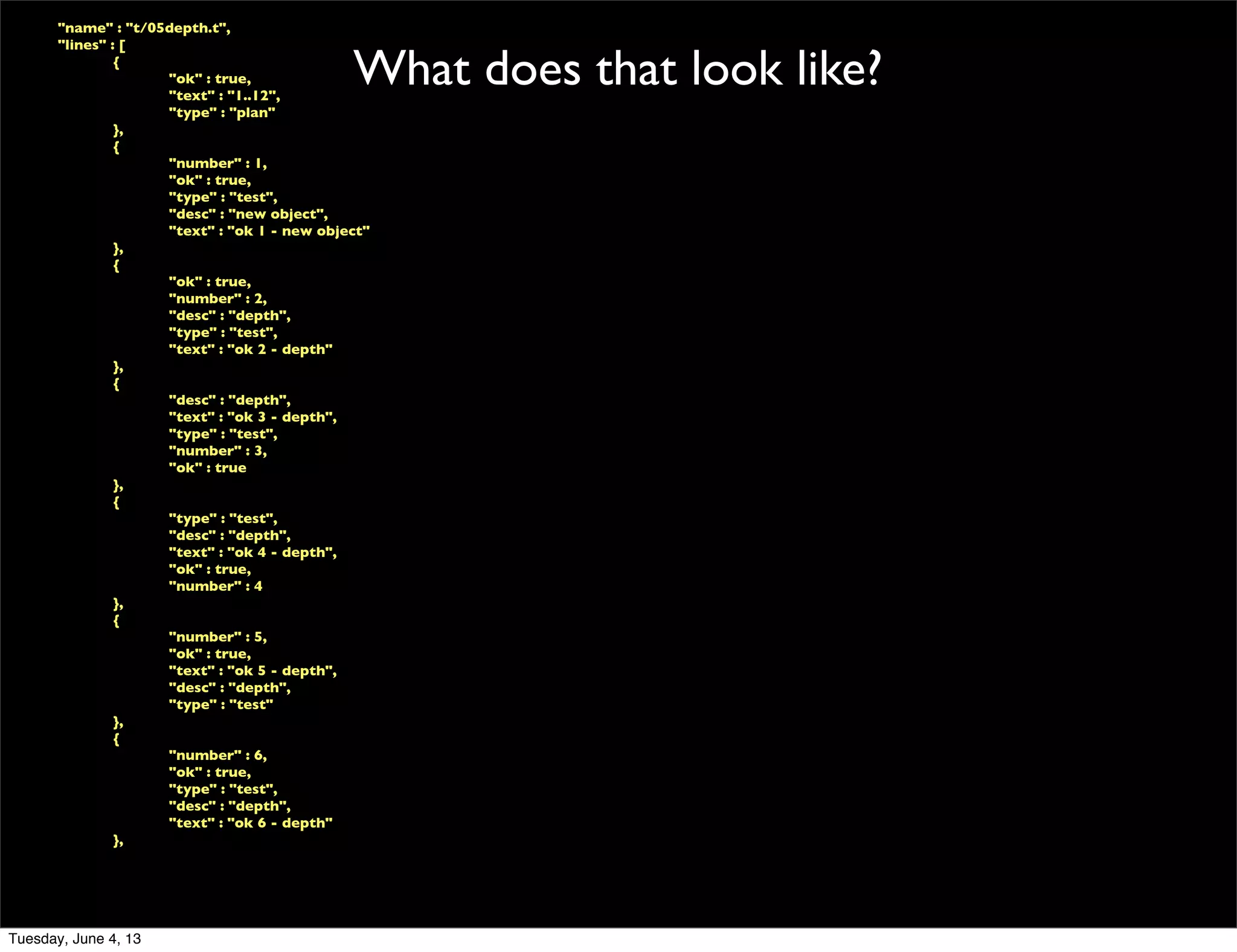
- 116. What does that look like? Parse the TAP output of each test into a structure which can be saved in MongoDB Tuesday, June 4, 13
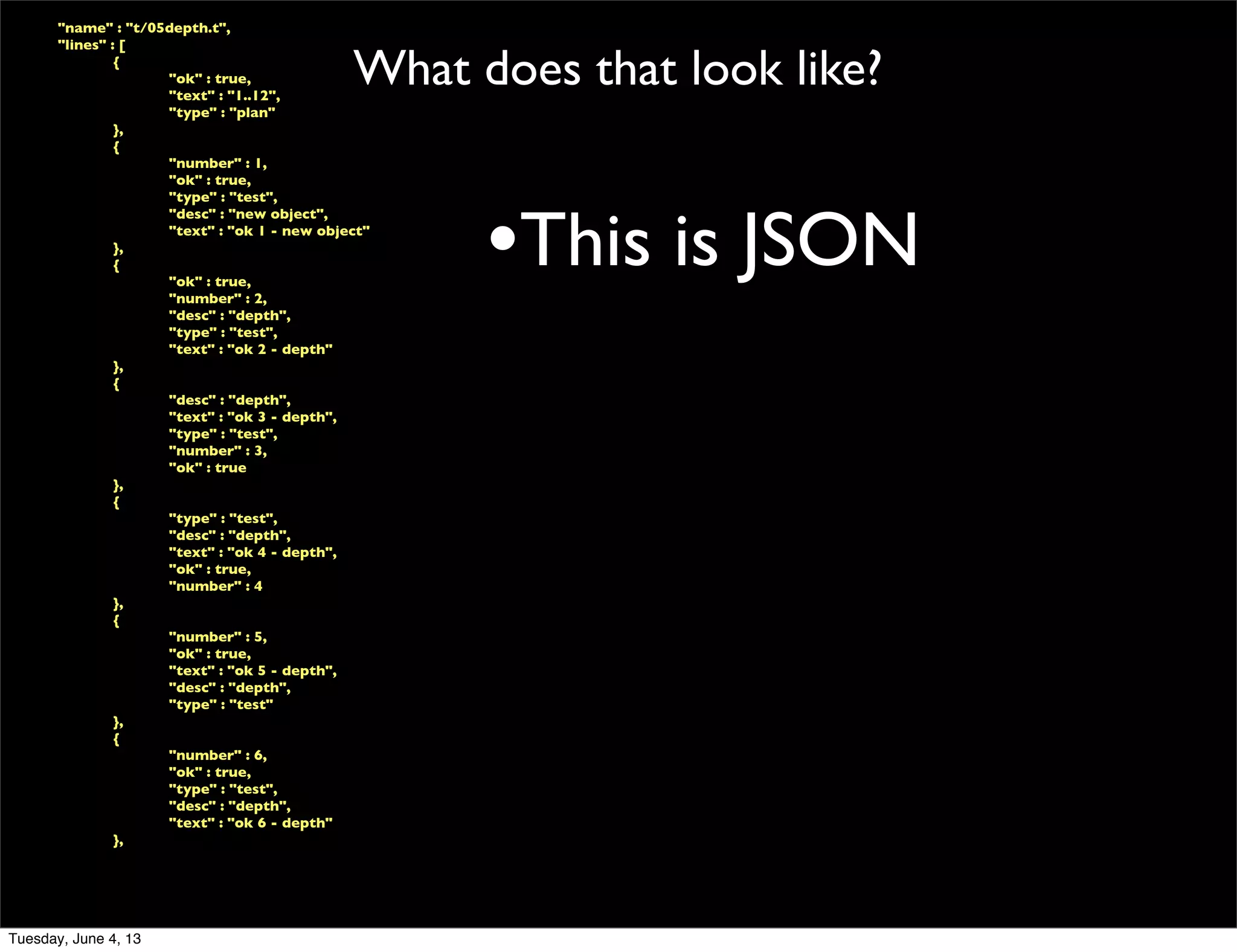
- 117. What does that look like? "name" : "t/05depth.t", "lines" : [ { "ok" : true, "text" : "1..12", "type" : "plan" }, { "number" : 1, "ok" : true, "type" : "test", "desc" : "new object", "text" : "ok 1 - new object" }, { "ok" : true, "number" : 2, "desc" : "depth", "type" : "test", "text" : "ok 2 - depth" }, { "desc" : "depth", "text" : "ok 3 - depth", "type" : "test", "number" : 3, "ok" : true }, { "type" : "test", "desc" : "depth", "text" : "ok 4 - depth", "ok" : true, "number" : 4 }, { "number" : 5, "ok" : true, "text" : "ok 5 - depth", "desc" : "depth", "type" : "test" }, { "number" : 6, "ok" : true, "type" : "test", "desc" : "depth", "text" : "ok 6 - depth" }, Tuesday, June 4, 13
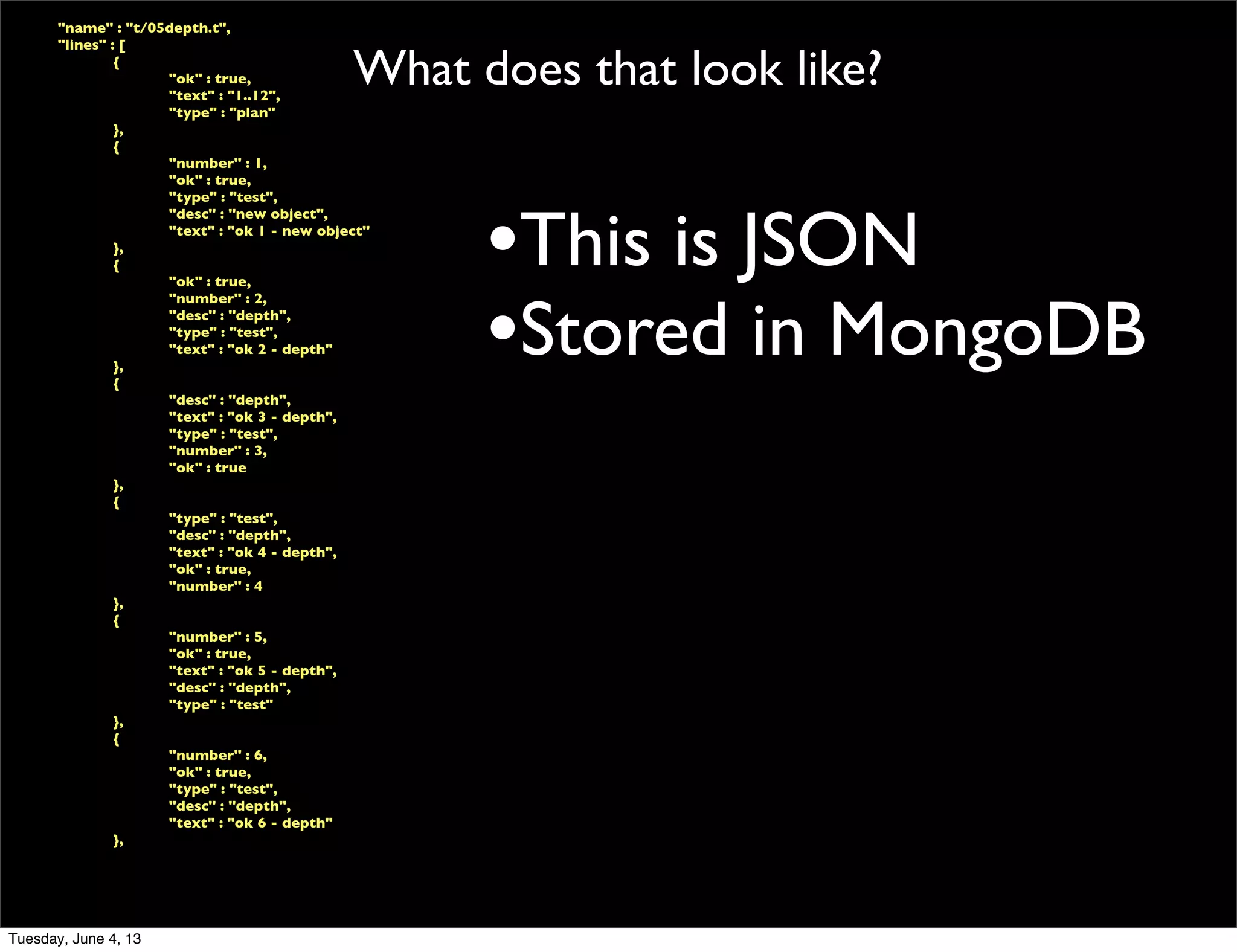
- 118. What does that look like? "name" : "t/05depth.t", "lines" : [ { "ok" : true, "text" : "1..12", "type" : "plan" }, { "number" : 1, "ok" : true, "type" : "test", "desc" : "new object", "text" : "ok 1 - new object" }, { "ok" : true, "number" : 2, "desc" : "depth", "type" : "test", "text" : "ok 2 - depth" }, { "desc" : "depth", "text" : "ok 3 - depth", "type" : "test", "number" : 3, "ok" : true }, { "type" : "test", "desc" : "depth", "text" : "ok 4 - depth", "ok" : true, "number" : 4 }, { "number" : 5, "ok" : true, "text" : "ok 5 - depth", "desc" : "depth", "type" : "test" }, { "number" : 6, "ok" : true, "type" : "test", "desc" : "depth", "text" : "ok 6 - depth" }, •This is JSON Tuesday, June 4, 13
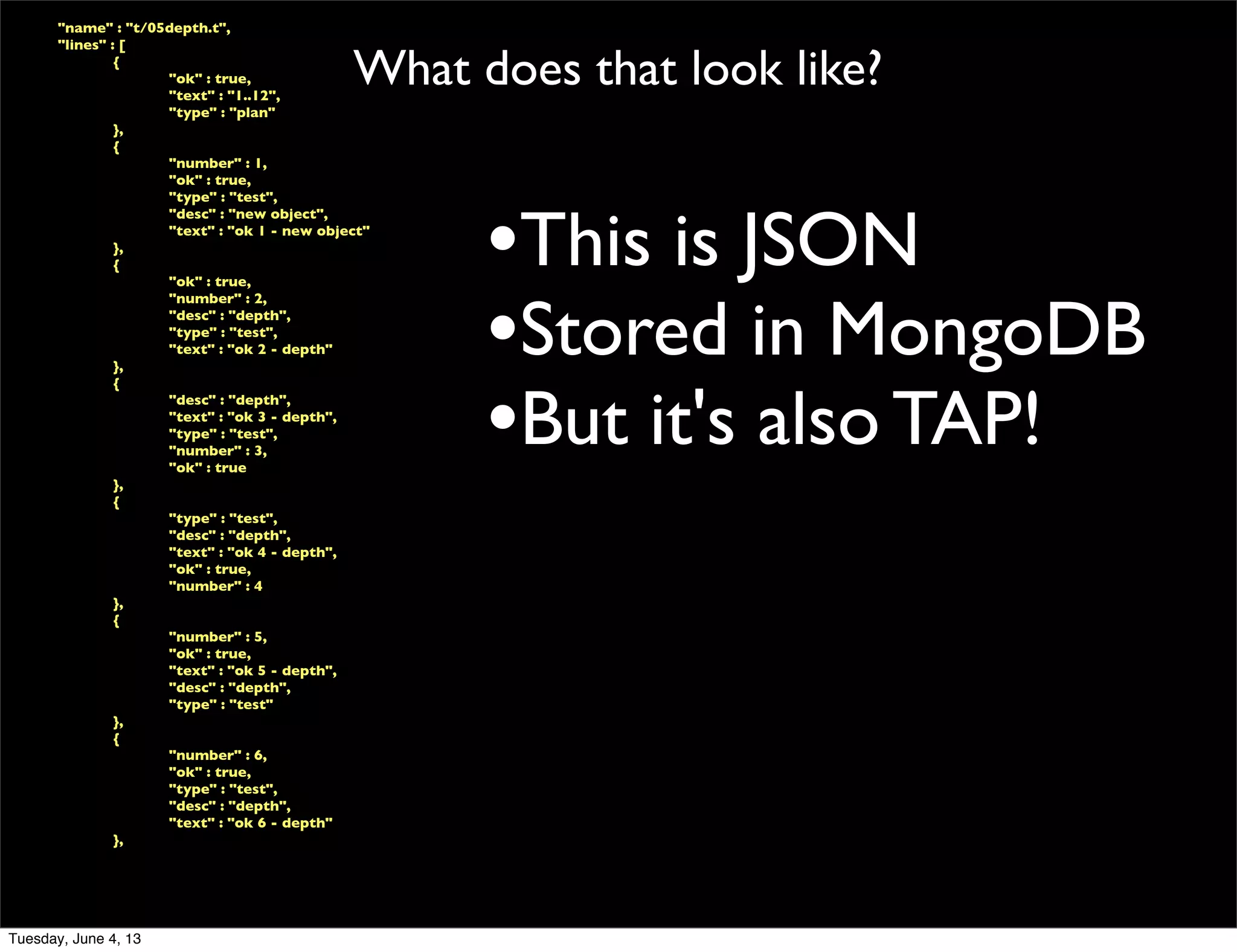
- 119. What does that look like? "name" : "t/05depth.t", "lines" : [ { "ok" : true, "text" : "1..12", "type" : "plan" }, { "number" : 1, "ok" : true, "type" : "test", "desc" : "new object", "text" : "ok 1 - new object" }, { "ok" : true, "number" : 2, "desc" : "depth", "type" : "test", "text" : "ok 2 - depth" }, { "desc" : "depth", "text" : "ok 3 - depth", "type" : "test", "number" : 3, "ok" : true }, { "type" : "test", "desc" : "depth", "text" : "ok 4 - depth", "ok" : true, "number" : 4 }, { "number" : 5, "ok" : true, "text" : "ok 5 - depth", "desc" : "depth", "type" : "test" }, { "number" : 6, "ok" : true, "type" : "test", "desc" : "depth", "text" : "ok 6 - depth" }, •This is JSON •Stored in MongoDB Tuesday, June 4, 13
- 120. What does that look like? "name" : "t/05depth.t", "lines" : [ { "ok" : true, "text" : "1..12", "type" : "plan" }, { "number" : 1, "ok" : true, "type" : "test", "desc" : "new object", "text" : "ok 1 - new object" }, { "ok" : true, "number" : 2, "desc" : "depth", "type" : "test", "text" : "ok 2 - depth" }, { "desc" : "depth", "text" : "ok 3 - depth", "type" : "test", "number" : 3, "ok" : true }, { "type" : "test", "desc" : "depth", "text" : "ok 4 - depth", "ok" : true, "number" : 4 }, { "number" : 5, "ok" : true, "text" : "ok 5 - depth", "desc" : "depth", "type" : "test" }, { "number" : 6, "ok" : true, "type" : "test", "desc" : "depth", "text" : "ok 6 - depth" }, •This is JSON •Stored in MongoDB •But it's also TAP! Tuesday, June 4, 13
- 121. Tuesday, June 4, 13
- 122. Bad Idea No. 4 Tuesday, June 4, 13
- 123. Bad Idea No. 4 LIVE DEMO! Tuesday, June 4, 13
- 124. The future? Tuesday, June 4, 13
- 125. The future? •Integration with Pinto Tuesday, June 4, 13
- 126. The future? •Integration with Pinto •Integration with Stratopan Tuesday, June 4, 13
- 127. The future? •Integration with Pinto •Integration with Stratopan •All kinds of cool statistics on the website Tuesday, June 4, 13
- 128. The future? •Integration with Pinto •Integration with Stratopan •All kinds of cool statistics on the website •Organizations using CPANci for their internal DarkPANs Tuesday, June 4, 13
- 129. Final Thoughts Tuesday, June 4, 13
- 130. Final Thoughts •Play with new toys. Tuesday, June 4, 13
- 131. Final Thoughts •Play with new toys. •Think before you code. Tuesday, June 4, 13
- 132. Final Thoughts •Play with new toys. •Think before you code. •Have bad ideas. Tuesday, June 4, 13
- 133. Final Thoughts •Play with new toys. •Think before you code. •Have bad ideas. •Ask stupid questions. Tuesday, June 4, 13
- 134. Final Thoughts •Play with new toys. •Think before you code. •Have bad ideas. •Ask stupid questions. •Have fun. Tuesday, June 4, 13