すでにご存じの方も多いと思いますが、2月22日にAIきりたんなるものが登場し、大騒ぎとなりました。正確にはSHACHI(@SHACHI_KRTN)さんという方が開発したNEUTRINOというAI歌声合成ソフトがフリーウェアで公開されるとともに、それで歌わせた楽曲が、くろ州さんなどによって公開され、話題になったのです。2月22日は、ちょうどMIDI 2.0の日米合意があった日で、そのドタバタでネットをチェックできておらず、私が気づいたのは24日になってから。その歌声を聴いて驚愕しました。
実際どんなものなのかと、さっそくNEUTRINOをダウンロードし、手元にあったMusicXMLデータを元に歌わせてみると、従来のVOCALOIDなどとは別次元の人間的な歌声で、東北きりたんが歌ってくれてさらに驚いたのです。どういうことなのか知りたいと思い、開発者のSHACHIさんに連絡してみたところ「種々の事情により、恐れながら今回の件についてはご辞退させていただきます」と丁重な返事をいただいてしまい断念。一方で、今回の件の仕掛け人が明治大学の専任准教授、森勢将雅(もりせまさのり)先生(@m_morise)であることを知り、連絡をとってみました。その結果、先日お時間をいただき、お話を伺うことができたので、今何が起きているのか、これからどんなことになっていくのか、いろいろ聞いてみました。

いまのAIきりたん騒動、ご存知ない方もいると思うので、NEUTRINOとほぼ同時に公開された以下の動画をご覧ください。
AIきりたんで『キリトリセン』カバー 調声済み
これが歌声合成によるものだと思うと、衝撃的ですよね。NEUTRINOの使い方については、いろいろなところで解説されているので、ここでは割愛しますが、Windowsマシンで動作するソフトとなっているので、それをダウンロードするとともに、BATファイルをエディットし、実行することで、手持ちのMusicXMLデータを歌わせることが可能です。
以前、「AI歌声合成をボーカルに起用した世界初のCDをリリース。歌声合成技術が人間を超える日は来るのか!?」という記事でも紹介した通り、私たちも、昨年、名古屋工業大学の協力を得てAI歌声合成を行ってCDを出したことがありました。
そのサビ部分をNEUTRINOに歌わせてみたのがこちら。
すごいですよね。歌声のニュアンスは違いますが、1年前に制作したときの、さとうささらの歌声と近い印象を持ちます。しかし、何がどうして、こんなすごいものがフリーウェアとして登場したのか、さっぱり状況がつかめません。そこで、森勢先生に話を伺ってみました。森勢先生は、音声分析合成システム『WORLD』を開発されたことで世界的にも知られる研究者。私も情報処理学科のシンポジウムなどでお話を伺ったことがありました。
ーー今回のAIきりたんの騒動!?、森勢先生が仕掛け人であると伺いました。実は森勢先生がSHACHIさんであり、NEUTRINOの開発者だった、ということなんですか?
森勢:いいえ、NEUTRINOを開発したのはSHACHIさんであって、私ではありませんし、SHACHIさんがどんな人なのかも知らないのです。ただ、背景をお話すると2018年9月に国立研究開発法人 科学技術振興機構(JST)の戦略的創造研究推進事業(さきがけ)の新規研究課題として、私が出した「Human-in-the-loop 型歌唱デザインの開発」というテーマが採択されたことがキッカケになっているのは確かだと思います。いま私たちが歌声合成の研究をしようと思っても、その素材となるものがほとんど公開されていません。せっかくなら、みんなで研究できるようにと思い作ったのが今回

--それが2018年のことだったんですね。
森勢:ちょうど著作権法30条の4が改正されたというのも大きなポイントでした。これによりAIによるディープラーニングや楽器開発のために試験的に楽曲を演奏したり歌ったりすることに対する規約が緩和されたのです。つまり人間が聴いて楽しむのではなく、人工知能の学習データとして
今ふと思ったんだけど,東北ずん子のUTAU音源があるんだったら,統計的歌声合成用の歌唱データセットの収録ってやらせてもらえないかしら.費用はこっち持ちで.
— M. Morise (忍者系研究者) (@m_morise) October 1, 2018
ずん子はボカロのみなので、イタコ姉さま、きりたん、他のキャラならぜひやって欲しいです♬♬٩(๑❛▽❛๑)۶♡https://t.co/fPWaTca9kz
— 東北ずん子(公式)💚AIきりたんリリースしました! (@t_zunko) October 1, 2018
その後、直接お話をし、交渉させていただいた結果、81プロデュース所属の声優で、東北きりたんのCVを担当している茜屋日海夏(あかねやひみか)さんが収録に対応してくれることになったのです。
ーーVOCALOIDの歌声データベースの収録は、呪文のような言葉をさまざまな音階で歌う、なんて言われていますが、ここでの収録というのはどういうものなのですか?
森勢:なるべく自然な歌声を学習させていきたいということで、茜屋さんが所属するアイドルグループ、i☆Risの楽曲を東
ーーその歌声を切り刻むなどして公開した、ということなのですか?
森勢:いいえ、その歌声を生声のまま、研究者向けにそのままWAVデータとして50曲分、公開しています。ただ、それだけではAIにディープラーニングさせることはできないので、その楽曲をMIDIデータとして入力したもの、さらには音素ラベルを付けたテキストデータを3点セットにして公開しています。もっとも、先ほどの著作権法30条の4をどう解釈するかによって考え方に違いが出る可能性もあるので、ダウンロードする際にFacebook認証をすることで、誰に配布したのかが分かるように記録はしています。
ーーなるほど、その公開したデータを元にSHACHIさんが作ったのがNEUTRINOであったというわけですね!
森勢:私たちも、このデータを元に、歌声合成システムを作ろうと計画していたのですが、SHACHIさんのNEUTRINOに先を越された、というわけなのです(笑)。すでにニューラルネットワークを使った統計的歌声合成の手法は学会でも発表され、確立しているので、それに従っていけば人間に近い歌声で歌わせることは可能です。BATファイルを実行し、真っ暗な画面で、いつ完了するか分からないまま待つUIは改良してほしい(苦笑)とは思いますが、素晴らしい品質のソフトだと思います。ご存知だと思いますが、このNEUTRINOには、東北きりたんのほかに、謡子(ようこ)という歌声ライブラリが収録されています。この謡子のほうは、名古屋工業大学で公開されているデータを使ったものだと思われます。ポップス調のものを歌わせると、きりたんが上手に歌いますが、バラード系を歌わせるときりたんはあまり得意ではなく、謡子のほうが上手です。これは学習したi☆Risの楽曲がポップスであったためで、テンポがゆっくりな童謡を歌ったデータを学習した謡子のほうがバラードに向いていたということですね。
ーーもっと、いろいろなジャンルの歌を学習させれば、万能な歌声合成システムができるのでしょうか?
森勢:試してみないと分からない面はありますが、必ずしもそうならないだろうと思います。学習した歌い方を元にして、平均的な歌い方をするから、たとえばロックとポップスとバラードの平均となったとき、それが上手な歌い方なのか……となってくるわけです。そのためロック用、ポップス用、バラード用、演歌用……など同じ人、同じキャラクタの声であっても、作り分けたほうが自然なものになりそうです。
ーーNEUTRINOに入っている歌声ライブラリは、森勢先生が公開された、東北きりたんの歌唱データベースそのものであると考えていいのでしょうか?
森勢:そうではありません。歌声そのものではなく、歌唱データベースを用いて学習したニューラルネットワークのパラメータが公開されていると思われます。NEUTRINOのKIRITANデータとして455MBあるので、結構な容量ですが、これはWAVデータとはまったく異なるものです。これを利用して統計的歌声合成を行うことで、きりたんっぽい歌い方をするのです。
ーー歌声ライブラリは、ニューラルネットワークのパラメータなんですね。これは今後登場してくるであろう、ほかのAI歌声合成のシステムにとって、互換性のある歌声ライブラリになるのですか?また最終的に歌声に合成するためのエンジンというのは誰でも簡単に作ることができるのですか?
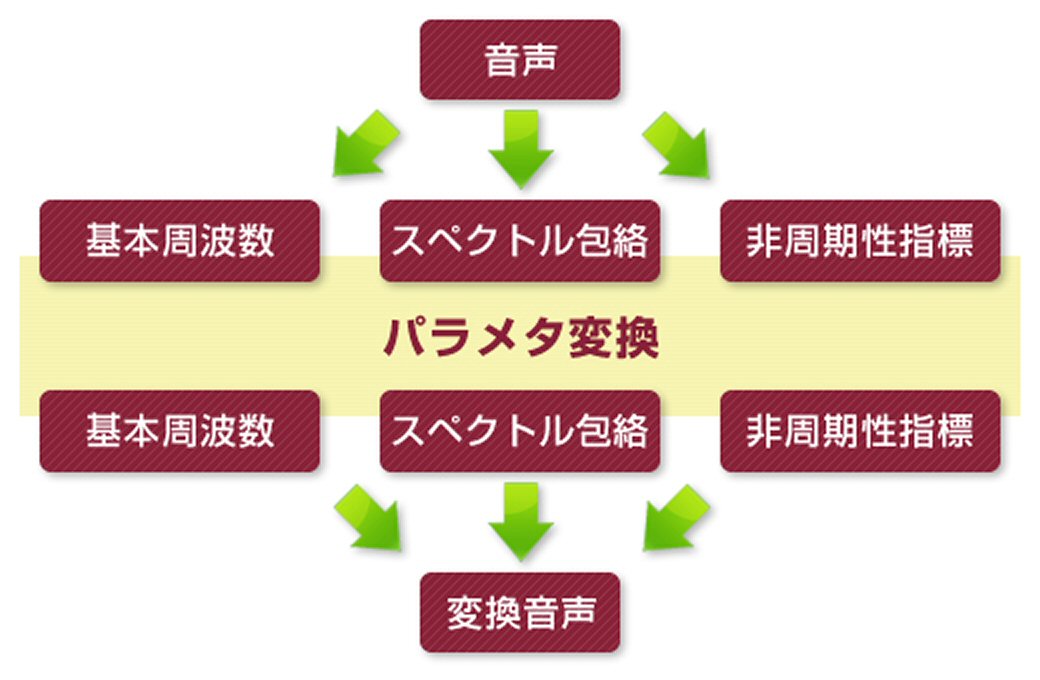
森勢:ディープラーニングにも種類があるので、それぞれで若干、品質は変わると思いますし、どう学習させるかは人によって少しずつアプローチも異なります。実際、NEUTRINOのパラメータは、SHACHIさんの手法で作ったものなのでNEUTRINOでしか使うことができず、たとえば私たちが今後、発表を予定しているシステムとは互換性はないでしょう。また、最終的な合成については私が以前に開発したWORLDを使うことで実現可能ですし、NEUTRINOもWORLDを使っているようですね。
--WORLDとは何なのか、簡単にご紹介いただけますか?
森勢:肉声と区別できないほど高い品質での音声合成を実現するために作られた音声分析合成システムです。ごく簡単にいえば、音声から高さと音色の情報を取り出してパラメータにし、そのパラメータを元に音声を再合成することができるシステムです。WORLDは2010年にプロジェクトを発表したので、今年がちょうど10周年。その後2015年に、ほぼ現在のスタイルへとアップデートし、最新版になったのが2017年です。その後も細かなアップデートはしていますが、オープンソースとして公開しているので、誰でも使うことが可能です。すでに、りんなの歌声合成技術に用いられたり、GREEの「転声こえうらない」というサービスで使われているほか、NTTやマイクロソフト、FacebookなどもWORLDを利用した研究の論文を出版しています。
ーーさて、ここからお伺いしたのは、森勢先生が開発されている、新しいAI歌声合成のシステムについてです。それはどんなものでNEUTRINOとは何がどう違うのでしょうか?
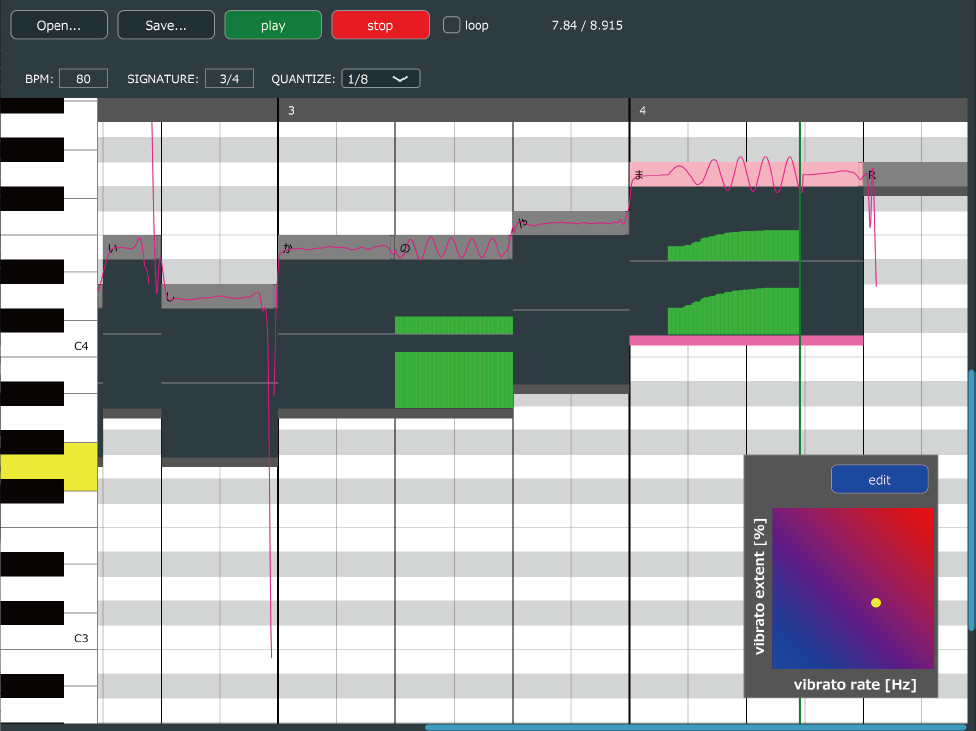
森勢:NEUTRINOは譜面をInputするとオーディオがOutputされるというシステムです。しかし私たちが開発しているのは、譜面データから結果だけを生み出すのではなく、人間の意志による操作を加えた歌い方ができるエディターを作ろうとしているのです。通常であれば、合成された結果をいじる形だとおもいますが、WORLDのパラメータの段階でデータをいじっていくのです。
--以前、私たちも名工大のシステムで合成してもらったデータを元に、Melodyneにかけてピッチ補正やタイミングの調整などを行いましたが、合成してからエディットするのではなく、エディットしてから合成するわけですね。
森勢:そのとおりです。出力された結果をエディットするとどうしても音が劣化していってしまいます。だから合成する前に人間の意志を反映させていこうというわけです。たとえば、「このタイミングからビブラートをかけていきたい」、と歌声を再生しながら、指定するとそれを再合成するという感じです。
--VOCALOID Editorでの調整とはだいぶ違う形ですね。
森勢:VOCALOID Editor的な要素も取り入れられるとは思いますが、人間が「こうしたい」と指示すると、よさそうな手法をいくつか提示してくれ、それを選ぶだけで人間の思いを簡単に反映できるようなものにしたいと思っています。
ーー先日、ボーカロイドPの方々と、AI歌声合成について意見交換をする機会があったのですが、その際「単に自動で歌声が生成されるのでは面白くない」、「VOCALOID的な歌声をいかに調整して歌わせるかが楽しいので、あまり人間っぽすぎるのは好きでない」なんて意見もありました。
森勢:どう捉えるかは人それぞれですが、やはり自分の思う通りに歌わせたいという人は多いと思うので、それをなるべく効率よくできるシステムを開発していきたいと思っています。また歌い方の一つに、機械的な歌い方というものが存在してもいいのではないでしょうか?それによって歌い方のバリエーションも広がっていくと思います。なお、このエディターはJUCE Frameworkを使って開発しているのでWindows、Mac、Linuxなどさまざまな環境で動かすことが可能になりますし、プラグイン化も容易にできそうです。またこのエディターの研究開発こそが、さきがけで採択された研究テーマです。3か年の計画で進めており、今年度が1年目。ですので、2022年3月までに完成させる予定で進めているところです。
--さきがけでの研究はまだ途中だったんですね。エディターのほかにも何か作る予定はあるのですか?
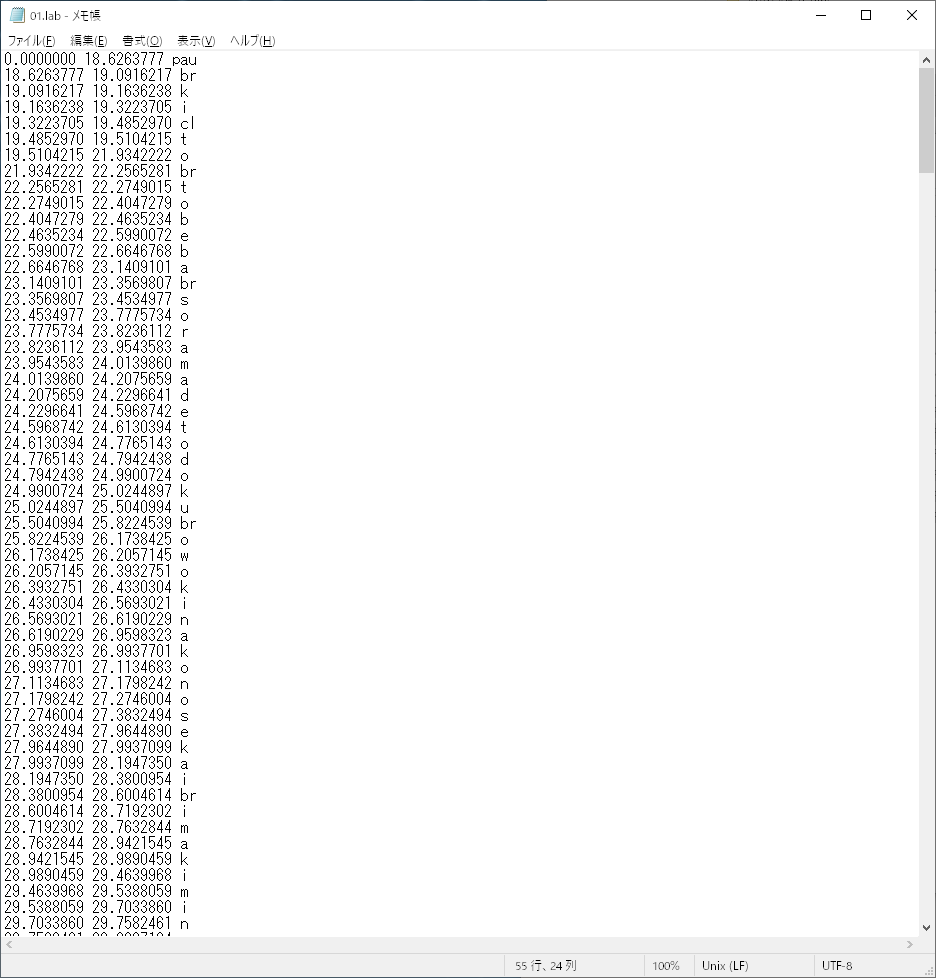
森勢:東北きりたんとは別に、もうひとつ歌唱データベースを作りたいと思っています。前回、東北きりたんのデータベースを作るのには、5日間のレコーディング後に、MIDIデータの入力や、音素ラベルの作成に4か月程度を要しました。ラベル付けには、学生にアルバイト料を払って手伝ってもらいましたが、Twitter上で協力してくれる、という人も現れたので、もう少し効率よく進められるかもしれません。
ーーちなみに、そのラベル付けとはどんな作業なのですか?
森勢:何秒目から何秒目までは、何の音素のデータなのか、1つ1つテキストで記述するものです。前回、東北きりたんで行ったときはWaveSurferというオープンソースのツールを使って作業をしていきました。が、同様の作業はUTAU音源のラベル付けなどでも行われており、そうした方に聞くとWaveSurferは使いづらく、効率が悪い、とのこと。もっと使いやすいツールもあるようなので、その辺は任せることができれば、と思っています。
--きりたんに加え、新しい歌声が誕生し、しかも使いやすく、思い通りに歌わせることが可能なエディターまで登場するとなれば、本当に楽しみです。これらも無料で公開されると期待していいのでしょうか?
森勢:はい、私たちはすべてオープンソースで無料公開していく予定です。また、今回のNEUTRINOのように、別の人が新しいツールなどを開発してくる可能性もあります。先ほどの著作権法の話でも触れた通り、基本的には研究を対象にしたものに無料公開しているわけですが、「いいものが開発でき、ビジネスとして展開したい」となった場合は、商用ライセンスとしての契約も可能にしているので、ぜひお声がけください。

ーー最後に、将来の予想について伺いたいのですが、こうした歌声のデータベースは増えていくと思われますか?また増えるとしたらどんな形で登場してきそうでしょうか?作曲家の人たちと話しをすると、ボーカロイドPの人たちとは違い、できるだけ簡単に仮歌を歌わせることができるといいけれど、そのシンガーのバリエーションが多いと嬉しいと言っています。
森勢:企業が参入してくることで、歌声のデータベースが増えてくる可能性があるほか、UTAUのような展開が広がっていくのではないかと思っています。つまり一般の方々が歌声をレコーディングし、MIDIデータ作成とラベル付けをしていくことで、膨大な歌声データベースができあがってくるのではないか、と。そうすれば、歌声の選択の幅も大きく広がっていくだろうと思っています。
ーーとっても楽しみな未来です。ありがとうございました。
【関連情報】
研究者向け音声合成検証用 東北きりたん歌唱データベース
NEUTRINO NEURAL SINGING SYNTHESIZERページ
WORLDページ
東北ずん子officialページ


