


























![特徴行列の作り方 (1)
# X = N×D 次元の行列(今回は D=1)
phi = [
lambda x: 1,
lambda x: x, # φ:特徴関数の列
lambda x: x ** 2, # lambda ってなに?
lambda x: x ** 3
]
N = len(X)
M = len(phi)
PHI = numpy.zeros((N, M)) # Φ:N×M行列の入れ物を用意
for n in xrange(N):
for m in xrange(M):
PHI[n, m] = phi[m](X[n]) # φ_m(x_n)](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-36-2048.jpg)

![つまりラムダ式のところは
phi = [
lambda x: 1, # φ_0(x) = 1
lambda x: x, # φ_1(x) = x
lambda x: x ** 2, # φ_2(x) = x^2
lambda x: x ** 3 # φ_3(x) = x^3
]
• 実はこの数式の実装でした
������������ ������ = ������ ������ (������ = 0, ⋯ , ������ − 1)
• 繰り返しなんだから、もっとかんたんに
できそう](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-39-2048.jpg)
![ぷちPython講座:リスト内包
• リスト内包 : ルールから配列を作る
– for ループを書かなくていい
– R の apply() 系の関数に相当
a = []
for x in xrange(10):
a.append(x * x)
リスト内包なら簡潔!
a = [x * x for x in xrange(10)]
※厳密にはいろいろ(ry](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-40-2048.jpg)
![「リスト内包」を使えば……
phi = [
lambda x: 1,
lambda x: x,
������������ ������ = ������ ������ (������ = 0, ⋯ , ������ − 1)
lambda x: x ** 2,
lambda x: x ** 3
]
こう書ける気がする
phi = [lambda x: x ** m for m in xrange(M)]
• かんたんになったね!](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-41-2048.jpg)
![だめでした……
• ������0 2 , ������1 2 , ������2 2 , ������3 2 を表示してみる
– “1 2 4 8” と出力されることを期待
M = 4
phi = [lambda x: x ** m for m in xrange(M)]
print phi[0](2), phi[1](2), phi[2](2), phi[3](2)
• ところがこれの実行結果は “8 8 8 8”
– って、全部同じ!? なんで???](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-42-2048.jpg)
![うまくいかない理由は……
• 「レキシカルスコープ」がどうとか
– ちょっとややこしい
• 回避する裏技もあるけど……
– もっとややこしい
M = 4
phi = [lambda x, c=m: x ** c for m in xrange(M)]
print phi[0](2), phi[1](2), phi[2](2), phi[3](2)
# => “1 2 4 8” と表示される(ドヤ](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-43-2048.jpg)

![特徴行列の作り方 (2)
• phi を「ベクトルを返す関数」として定義
– ������������ のリストではなく,������ = (������������ )を扱う
– lambda を書かなくていい
– 関数の呼び出し回数も減って高速化
• 行列の生成にもリスト内包を使う numpy の機能の
一部と言っても
– numpy.array(リスト内包) は頻出! いいくらい
def phi(x):
return [x ** m for m in xrange(4)]
PHI = numpy.array([phi(x) for x in X])](https://image.slidesharecdn.com/formula-to-numpy-111014235718-phpapp01/75/numpy-45-2048.jpg)


数式をnumpyに落としこむコツ
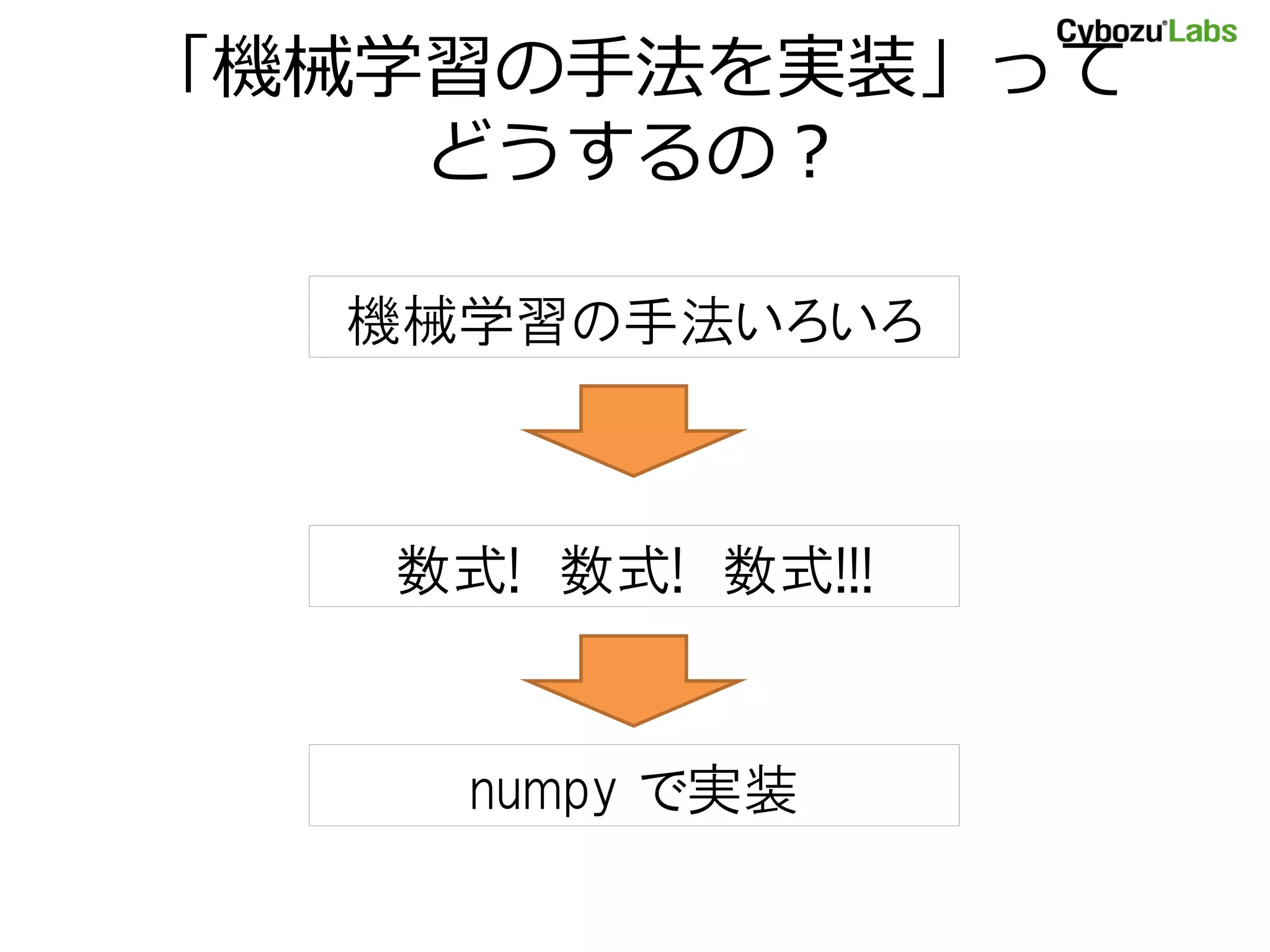
- 1. 数式を numpy に落としこむコツ ~機械学習を題材に~ 2011/10/15 中谷 秀洋@サイボウズ・ラボ @shuyo / id:n_shuyo
- 2. 「機械学習の手法を実装」って どうするの? 機械学習の手法いろいろ 数式! 数式! 数式!!! numpy で実装
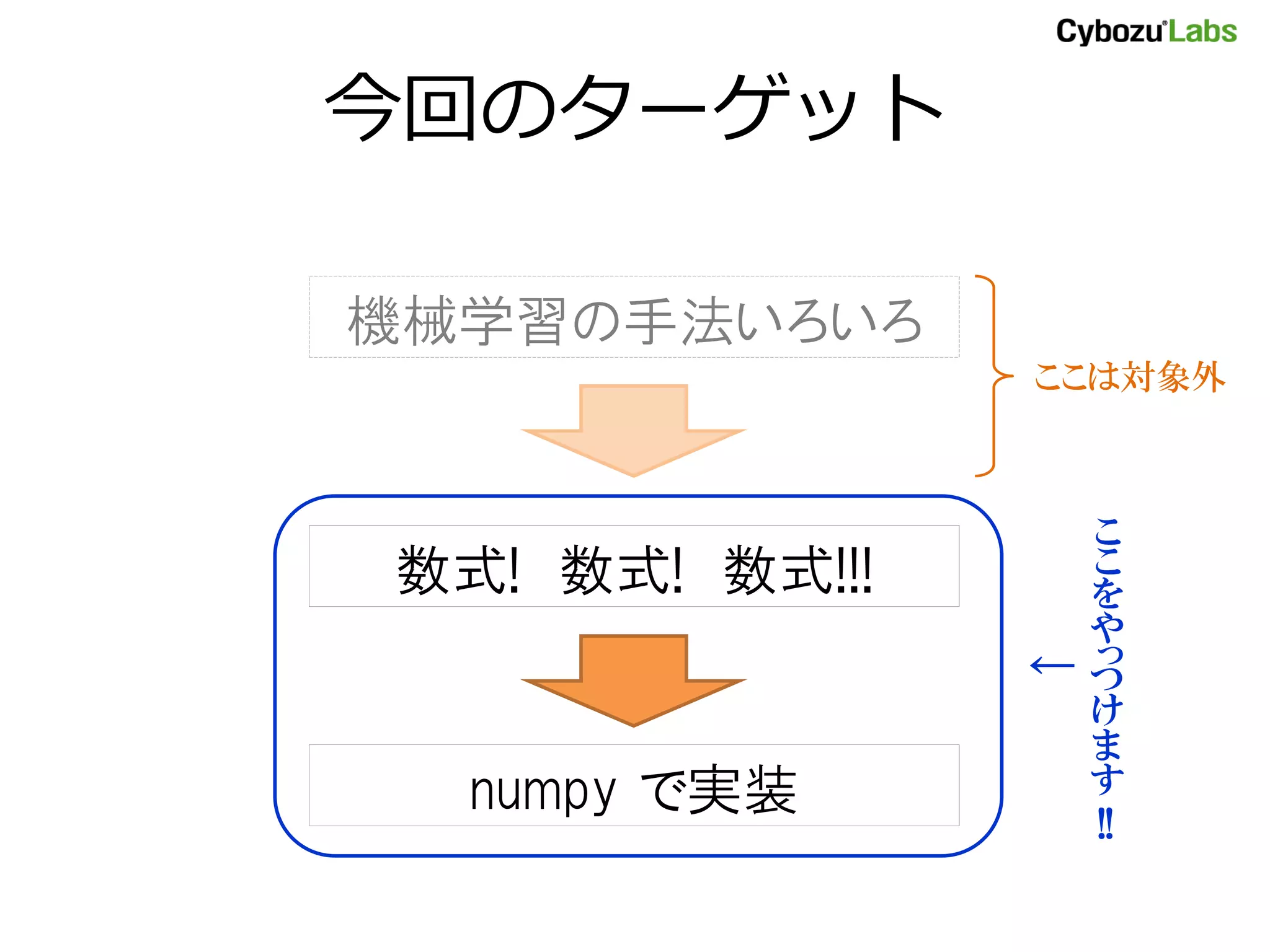
- 3. 今回のターゲット 機械学習の手法いろいろ ここは対象外 こ 数式! 数式! 数式!!! こ を や ← っ つ け ま numpy で実装 す !!
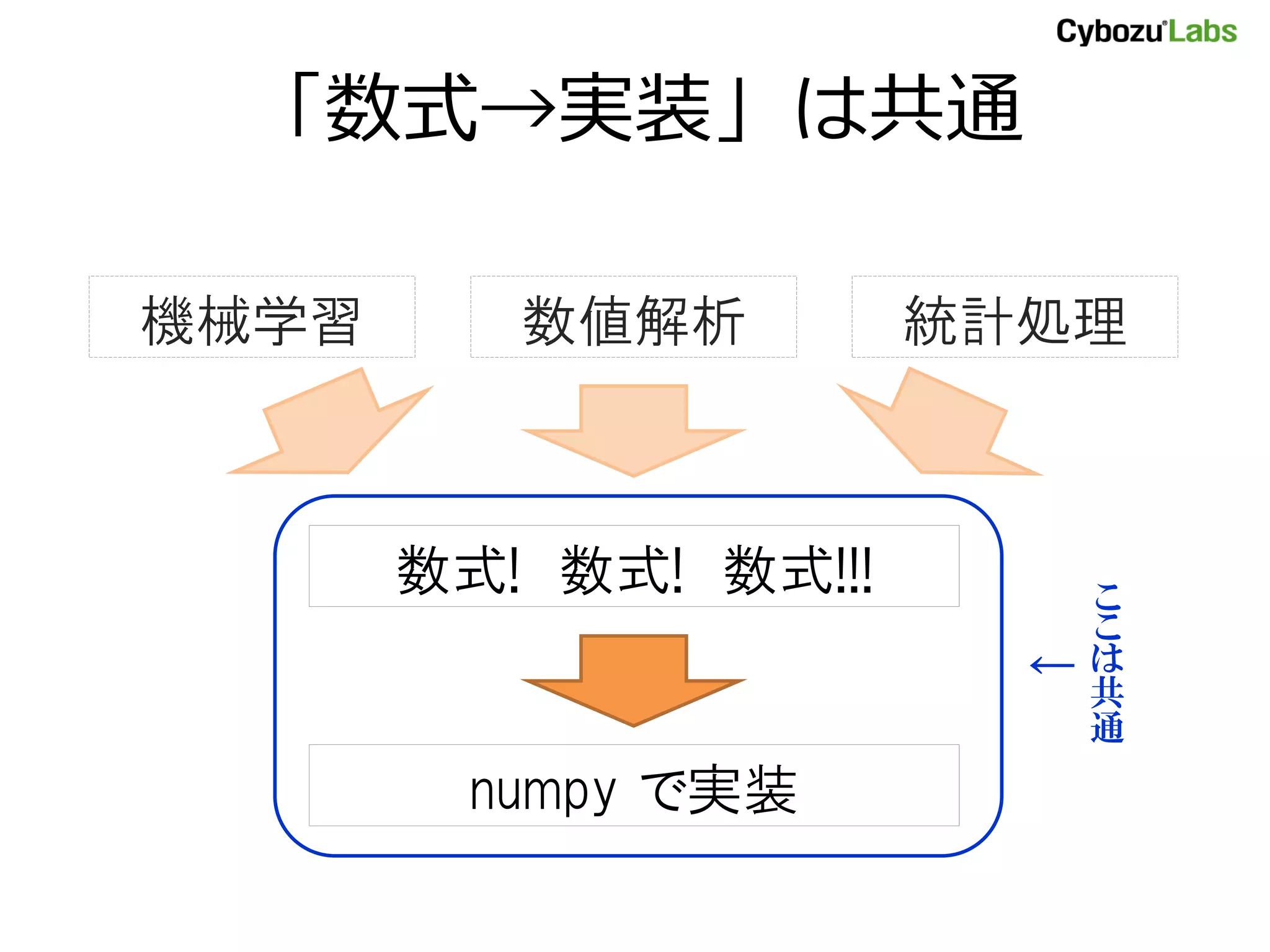
- 4. 「数式→実装」は共通 機械学習 数値解析 統計処理 数式! 数式! 数式!!! こ こ ← は 共 通 numpy で実装
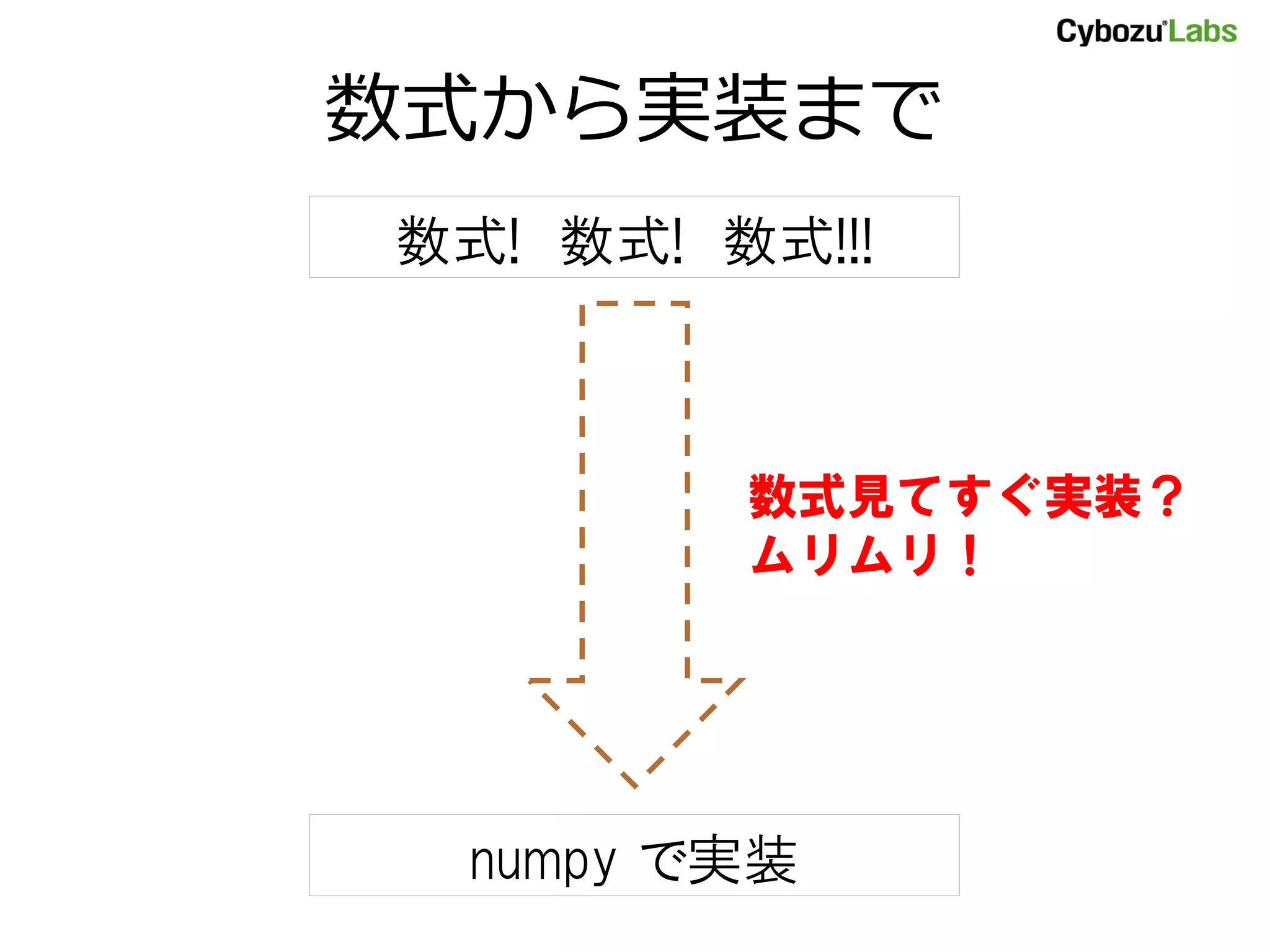
- 5. 数式から実装まで 数式! 数式! 数式!!! 数式見てすぐ実装? ムリムリ! numpy で実装
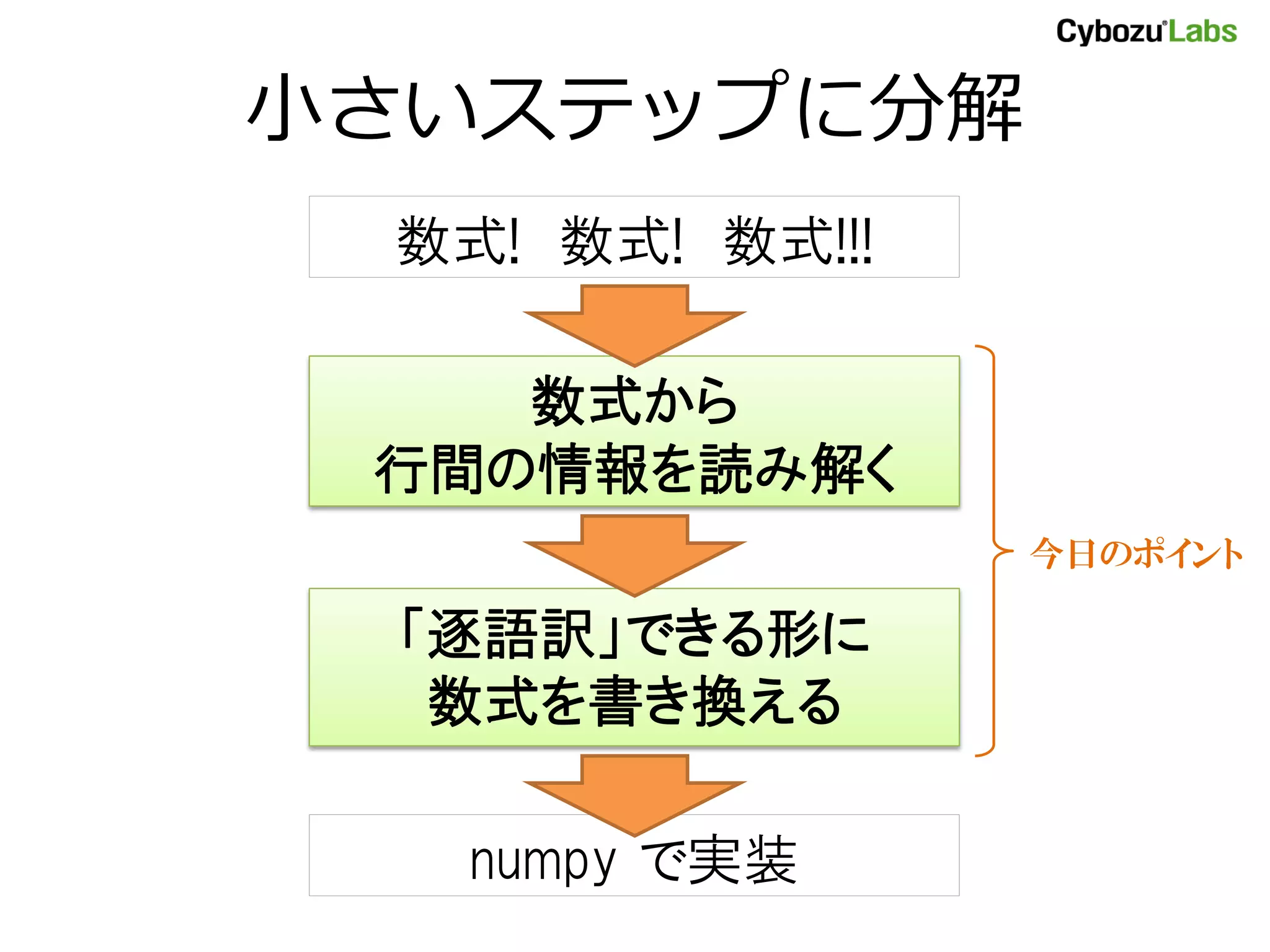
- 6. 小さいステップに分解 数式! 数式! 数式!!! 数式から 行間の情報を読み解く 今日のポイント 「逐語訳」できる形に 数式を書き換える numpy で実装
- 7. この後の流れ 1. 数式が降ってきた! – 「式はどうやって出てきたか」は無視! 2. (必要なら)数式を読み解こう 3. (必要なら)数式を書き換えよう 4. 数式を「逐語訳」で実装しよう
- 9. 対象とする「数式」 • 数式の例は「パターン認識と機械学習」 (以降 PRML)から引く • 主に行列やその要素の掛け算が出てくる数式 – 掛け算は基本中の基本! • コンピュータで実装したい数式は、行列を 使って表されているものも多い – 機械学習は典型例の1つ、かな? – 他の分野は……あまり知りません(苦笑
- 10. おことわり • Python/numpyの基本機能は説明しません – Python の文法とか – 行列やベクトルの四則演算とか • ラムダ式とリスト内包はちょろっと紹介 • 線形代数の基本的な知識も説明しません – 四則演算とか、転置とか、逆行列とかとか • 行列式や固有値なんかは出てこないので安心して
- 11. 記法 • 数式 – ベクトルは太字の小文字 – 行列は太字の大文字 ネームスペースを • コード 省略するの嫌い~ C++ の using namespace も – import numpy は省略 使ったことないしw – import numpy as np はしない – numpy.matrix は使わず ndarray で • 行列積と要素積が紛らわしくなるとかいろいろ嫌いw
- 12. 書き換え不要なパターン
- 13. まずは一番簡単なパターンから ������ = ������ ������ ������ −1 ������ ������ ������ (PRML 3.15 改) • 線形回帰のパラメータ推定の式 – この式がどこから降ってきたかは気にしな い!
- 14. ちなみに「線形回帰」って? • 回帰:与えられた点を(だいたい)通る曲線 (関数)を見つけること – 「回帰」って何が戻ってくるの? というの は突っ込んではいけないお約束 • 線形回帰:∑������������ ������(������)という線形結合の形 の中で点を通るものを探す – 線形の関数(つまり直線)を求めているわけで はありません 一応紹介してみたけど、気にしなくていいですw
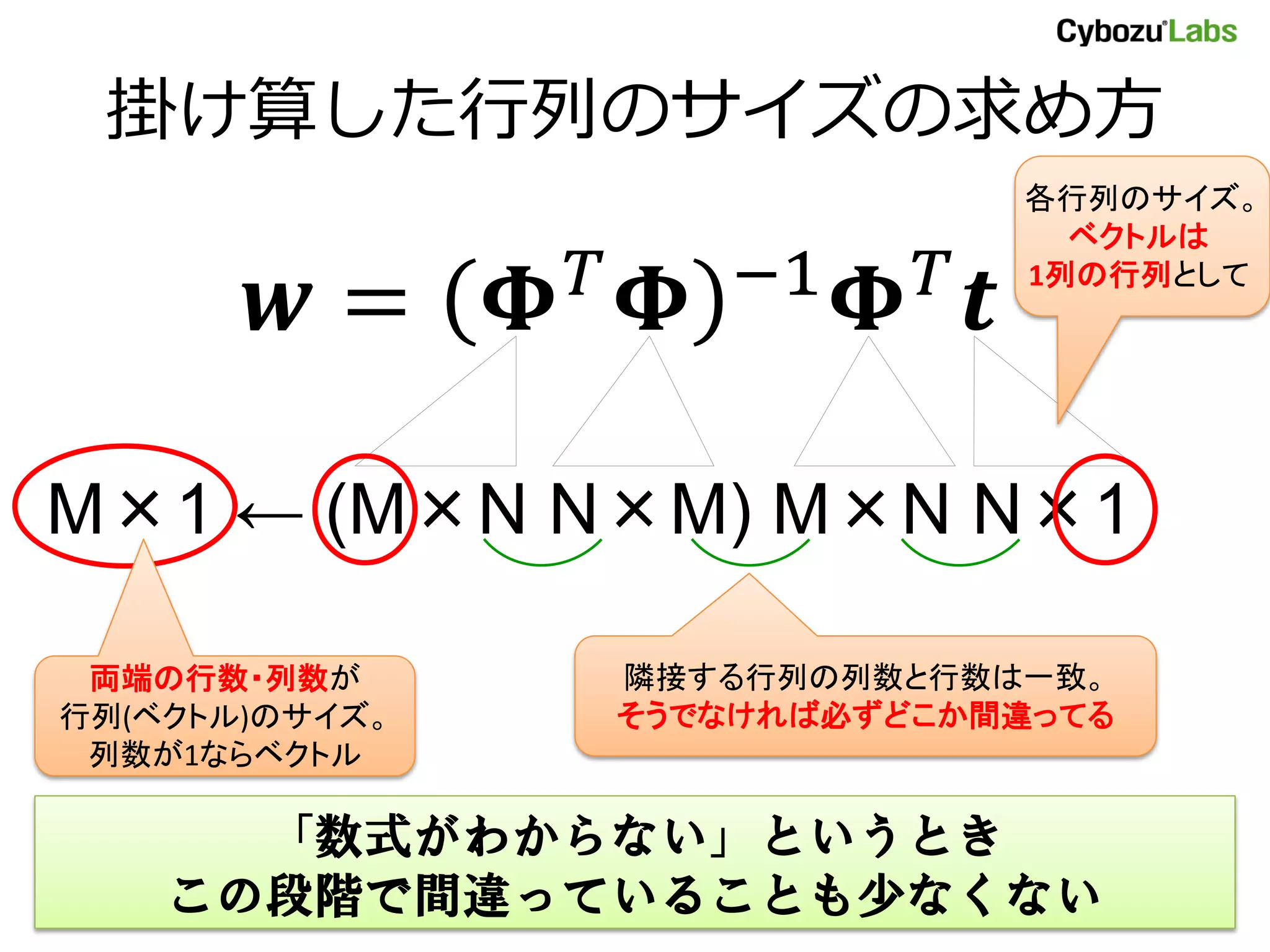
- 15. 数式の「読み解き」 ������ = ������ ������ ������ −1 ������ ������ ������ (PRML 3.15 改) • ������:N×M次元の特徴行列 – 中身は気にしない – N×M次元の行列が与えられているだけ! • t:N次のベクトル(正解データ) – 中身は気にしない(以下同様) • w はベクトル? 行列? 何次の? ※特徴行列の作り方は後の「おまけ」で出てきます
- 16. 掛け算した行列のサイズの求め方 各行列のサイズ。 ベクトルは ������ −1 ������ ������ = ������ ������ ������ ������ 1列の行列として M×1 ← (M×N N×M) M×N N×1 両端の行数・列数が 隣接する行列の列数と行数は一致。 行列(ベクトル)のサイズ。 そうでなければ必ずどこか間違ってる 列数が1ならベクトル 「数式がわからない」というとき この段階で間違っていることも少なくない
- 17. numpy に「逐語訳」 ������ = ������ ������ ������ −1 ������ ������ ������ (PRML 3.15 改) numpy.dot(PHI.T, PHI) numpy.dot(PHI.T, t) ������−1 ������ = numpy.linalg.solve(������, ������) # PHI = N×M次元の特徴行列 # t = N次のベクトル(正解データ) w = numpy.linalg.solve(numpy.dot(PHI.T, PHI), numpy.dot(PHI.T, t)) ※ 逆行列のところで inv() を使ってもいいですが、 solve() の方がコードが短いし、速度もかなり速いです
- 18. いつもこんなにかんたんとは 限りませんよね
- 19. 書き換えが必要になるパターン
- 20. 多クラスロジスティック回帰の 誤差関数の勾配 ������ ������������������ ������ ������ = ������������������ − ������������������ ������������ (k = 1, ⋯ , ������) ������=1 (PRML 4.109 改) • ������ = ������������������ : N×K 次行列(予測値) 与 • ������ = ������������������ : N×K 次行列(1-of-K 表現) え ら • ������ = ������1 , … , ������������ = (������������������ ) : M×K 次行列 れ て い • ������ = ������������������ = ������1 , ⋯ , ������������ ������ : N×M 次行列 る 情 – ������������ = ������ ������������ = ������������ ������������ ������ : M 次ベクトル 報
- 21. 「ロジスティック回帰」って?
- 22. 「誤差関数」って?
- 23. 「勾配」って?
- 24. 式がどこから降ってきたかは 気にしない!
- 25. さすがに「勾配」は 必要なんじゃあないの? ������ これ ������������������ ������ ������ = ������������������ − ������������������ ������������ ������=1 • 右辺は M 次ベクトル – ������������������ − ������������������ はただのスカラー – 一般には先ほどの方法で次元を読み解けばいい • それが k=1,……,K 個あるだけ – つまり求めるのは「M×K次元の行列」と読み解く • ∴「勾配」は実装になんの関係もない!
- 26. 求めるものは 読み解けたが
- 28. 「逐語訳」できる形に書き換える • 掛けて行列になるパターンは大きく3通り – 上から要素積、行列積、直積 ������������������ = ������������������ ������������������ ⇔ C=A*B ������������������ = ∑������ ������������������ ������������������ ⇔ C=numpy.dot(A, B) ������������������ = ������������ ������������ ⇔ C=numpy.outer(a, b) 数式を左の形に書き換えれば、 右の numpy コードに「逐語訳」できる ※「外積」もあるが、使う人やシーンが限られるので略
- 29. 式を書き換える (1) ������ ������������������ ������ ������ = ������������������ − ������������������ ������������ ������=1 • 行列の要素の式になおす ������ ������������ ������ ������������ = ������������������ − ������������������ ������������������ ������=1 (������ = 1, ⋯ , ������; ������ = 1, ⋯ , ������) – ������������ ������ は「求める行列」としてひとかたまりで扱う
- 30. 式を書き換える (2) ������ ������������ ������ ������������ = ������������������ − ������������������ ������������������ ������=1 • 注:右辺の添え字に未解決のものは残らない – 左辺に現れる : m, k – 右辺で解決 : n (総和で消える) • 3種類の積のどれかに帰着するよう変形 – この場合、総和があるので ������������������ = ∑������ ������������������ ������������������ に
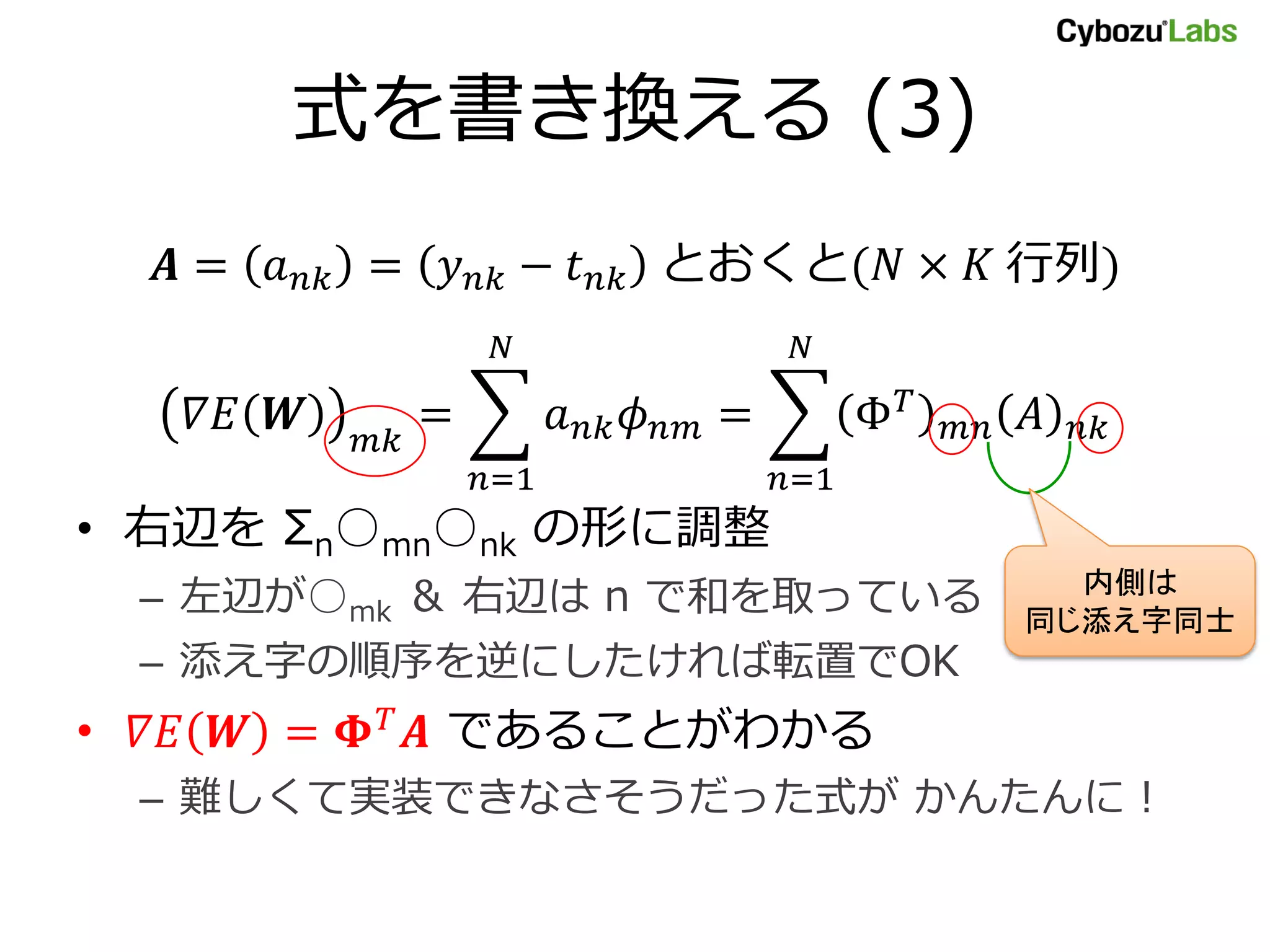
- 31. 式を書き換える (3) ������ = ������������������ = ������������������ − ������������������ とおくと(������ × ������ 行列) ������ ������ ������������ ������ ������������ = ������������������ ������������������ = Φ������ ������������ ������ ������������ ������=1 ������=1 • 右辺を Σn○mn○nk の形に調整 内側は – 左辺が○mk & 右辺は n で和を取っている 同じ添え字同士 – 添え字の順序を逆にしたければ転置でOK • ������������ ������ = ������ ������ ������ であることがわかる – 難しくて実装できなさそうだった式が かんたんに!
- 32. numpyに「逐語訳」 • ������ = ������ − ������, ������������ ������ = ������ ������ ������ を実装 – うわあ、かんたんすぎ # PHI = N×M 次元の特徴行列 # Y, T = N×K 次元の行列 gradient_E = numpy.dot(PHI.T, Y - T) • 元の数式と見比べてみよう ������ ������������������ ������ ������ = ������������������ − ������������������ ������������ (k = 1, ⋯ , ������) ������=1
- 33. まとめ • 数式から条件を読み解こう – この段階で間違っていると、絶対うまく行かない – さぼらず紙と鉛筆で確認するのが一番賢い • 「逐語訳」できる数式なら実装かんたん – 基本機能の呼び出しで完成! – 難しい数式は「逐語訳」できる形に書き換え – さぼらず紙と鉛筆(ry
- 35. 特徴行列(先ほどの ������) ������1 ������1 ������1 ������2 ⋯ ������1 ������������ ������2 ������1 ������2 ������2 ⋯ ������2 ������������ ������ = ⋮ ⋮ ⋱ ⋮ ������������ ������1 ������������ ������2 ⋯ ������������ ������������ • 関数 ������ ������ = ������1 ������ , ⋯ , ������������ ������ と、 • データ ������ = (������1 , ⋯ , ������������ ) から作る行列 – カーネル法のグラム行列も似たような作り
- 36. 特徴行列の作り方 (1) # X = N×D 次元の行列(今回は D=1) phi = [ lambda x: 1, lambda x: x, # φ:特徴関数の列 lambda x: x ** 2, # lambda ってなに? lambda x: x ** 3 ] N = len(X) M = len(phi) PHI = numpy.zeros((N, M)) # Φ:N×M行列の入れ物を用意 for n in xrange(N): for m in xrange(M): PHI[n, m] = phi[m](X[n]) # φ_m(x_n)
- 37. ‘lambda’ ってなに?
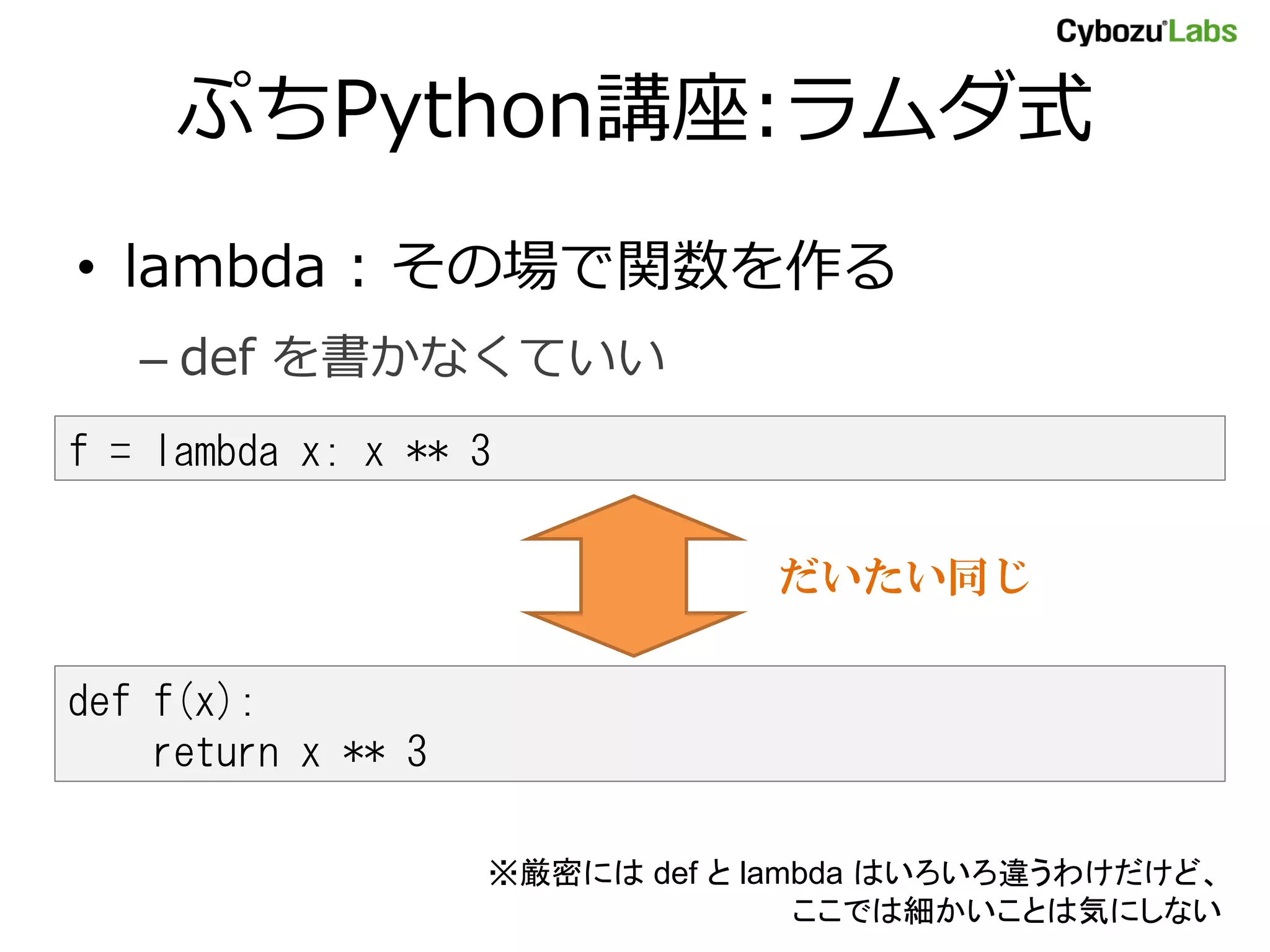
- 38. ぷちPython講座:ラムダ式 • lambda : その場で関数を作る – def を書かなくていい f = lambda x: x ** 3 だいたい同じ def f(x): return x ** 3 ※厳密には def と lambda はいろいろ違うわけだけど、 ここでは細かいことは気にしない
- 39. つまりラムダ式のところは phi = [ lambda x: 1, # φ_0(x) = 1 lambda x: x, # φ_1(x) = x lambda x: x ** 2, # φ_2(x) = x^2 lambda x: x ** 3 # φ_3(x) = x^3 ] • 実はこの数式の実装でした ������������ ������ = ������ ������ (������ = 0, ⋯ , ������ − 1) • 繰り返しなんだから、もっとかんたんに できそう
- 40. ぷちPython講座:リスト内包 • リスト内包 : ルールから配列を作る – for ループを書かなくていい – R の apply() 系の関数に相当 a = [] for x in xrange(10): a.append(x * x) リスト内包なら簡潔! a = [x * x for x in xrange(10)] ※厳密にはいろいろ(ry
- 41. 「リスト内包」を使えば…… phi = [ lambda x: 1, lambda x: x, ������������ ������ = ������ ������ (������ = 0, ⋯ , ������ − 1) lambda x: x ** 2, lambda x: x ** 3 ] こう書ける気がする phi = [lambda x: x ** m for m in xrange(M)] • かんたんになったね!
- 42. だめでした…… • ������0 2 , ������1 2 , ������2 2 , ������3 2 を表示してみる – “1 2 4 8” と出力されることを期待 M = 4 phi = [lambda x: x ** m for m in xrange(M)] print phi[0](2), phi[1](2), phi[2](2), phi[3](2) • ところがこれの実行結果は “8 8 8 8” – って、全部同じ!? なんで???
- 43. うまくいかない理由は…… • 「レキシカルスコープ」がどうとか – ちょっとややこしい • 回避する裏技もあるけど…… – もっとややこしい M = 4 phi = [lambda x, c=m: x ** c for m in xrange(M)] print phi[0](2), phi[1](2), phi[2](2), phi[3](2) # => “1 2 4 8” と表示される(ドヤ
- 44. 結論 • リスト内包の中では lambda を使わない ようにしよう!(ぇ – これで同種の問題はだいたい避けられる • かんたんに書く他の方法を考えてみる
- 45. 特徴行列の作り方 (2) • phi を「ベクトルを返す関数」として定義 – ������������ のリストではなく,������ = (������������ )を扱う – lambda を書かなくていい – 関数の呼び出し回数も減って高速化 • 行列の生成にもリスト内包を使う numpy の機能の 一部と言っても – numpy.array(リスト内包) は頻出! いいくらい def phi(x): return [x ** m for m in xrange(4)] PHI = numpy.array([phi(x) for x in X])
- 46. まとめ • リスト内包は超便利 – 憶えましょう – 憶えてなかったら Python 使ってる意味ない と言い切ってしまっていいくらい • ラムダ式も便利 – でもリスト内包の中で使うとハマることがあ るので避けましょう
- 47. よだん • numpy.fromfunction() を使って特徴行 列を作る方法もあるよ。あるけど…… – なんかいろいろひどい • take とか dtype=int とか – ダメな numpy の見本 PHI = numpy.fromfunction( lambda n, m: X.take(n) ** m, (N, M), dtype=int)